PARTITION BY와 GROUP BY의 차이점
배경
다음과 같은 관계를 갖는 테이블이 있다고 하자.

member는 회원들의 회원번호와 가입일을,
sales는 회원별 물품을 주문한 정보를,
menu는 각 상품 정보를 가지는 테이블이다.
이때, 현재 members, sales, menu에 다음과 같이 데이터들이 적재돼있다고 하자.
1. members

2. sales

3. menu

주어진 문제
각 고객들이 구입한 첫 물건은?
sales 테이블에는 각 회원들이 특정 물품을 구입한 날에 대한 데이터들이 적재돼있으니, 이 테이블에서 적절한 쿼리를 활용해볼 수 있을 것이다. 이 때 처음 물품을 구매한 날짜에 여러 물품을 구매했다면, 해당 물품들의 정보를 모두 출력해야 한다.
풀이1 : GROUP BY를 활용한 접근
sales테이블에 있는 구매한 물품들에 대한 상세정보는 sales와 menu의 product_id들을 INNER JOIN을 걸어 알아낼 수 있다. 그러나 회원별로 가장 처음 구매한 물품들에 대한 정보만 필요하다. sales에서 customer_id로 GROUP BY를 걸고, 그 안에서 MIN함수를 통해 가장 낮은 order_date를 뽑아내면 다음과 같이 회원별로 물품을 처음 구매한 날짜를 추출할 수 있다.
SELECT customer_id, min(order_date)
FROM sales
GROUP BY customer_id;

위 결과를 WHERE절에서 활용, sales테이블에서 다음과 같이 회원별로 해당 날짜에 대한 데이터들을 추출 가능하다.
SELECT *
FROM sales
WHERE (customer_id, order_date) in (
SELECT customer_id, min(order_date)
FROM sales
GROUP BY customer_id
);
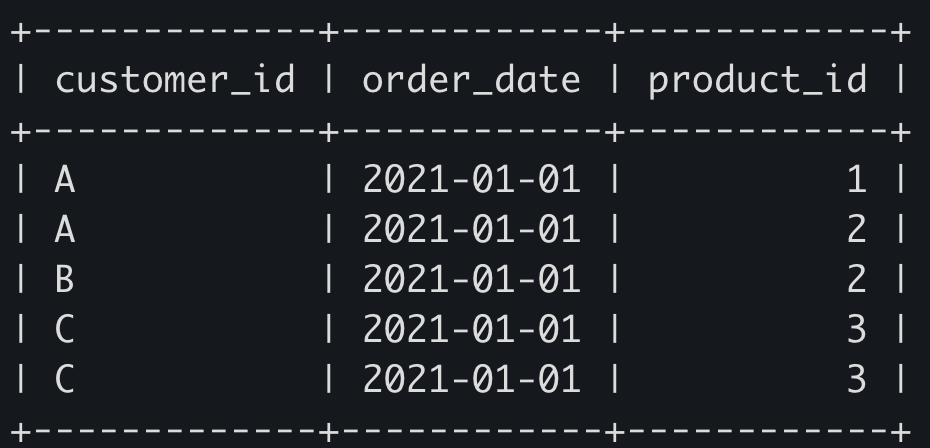
그러나 위 결과에서 4, 5번 레코드를 보면 중복되는 레코드들임을 알 수 있다. C는 2021년 1월 1일에 3번 물품을 2번 구매했기 때문에 이런 결과가 생기는 것이다. 따라서 다음과 같이 DISTINCT를 걸어줘서 중복을 제거할 수 있다.
✅ DISTINCT
: SQL에서 중복된 값을 제거하여 결과 집합에서 고유한 값을 반환하는 데 사용되는 키워드. DISTINCT 뒤에 2개 이상의 컬럼을 사용하면, 해당 컬럼들로 구성되는 조합들에 대한 중복을 제거하는 식으로 동작한다.
(즉, 아래 예제에서는 customer_id, order_date, product_id로 이뤄지는 조합에서 중복이 없어진다)
SELECT DISTINCT customer_id, order_date, product_id
FROM sales
WHERE (customer_id, order_date) in (
SELECT customer_id, min(order_date)
FROM sales
GROUP BY customer_id
);
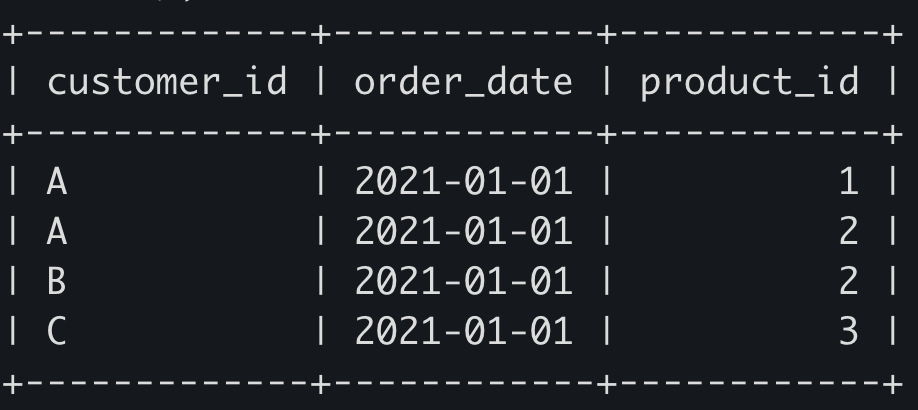
이제 menu와 INNER JOIN을 걸어 다음과 같이 처음 구매한 물품의 상세정보를 뽑아낼 수 있다.
SELECT DISTINCT customer_id, order_date, sales.product_id, product_name, price
FROM sales
INNER JOIN menu ON sales.product_id = menu.product_id
WHERE (customer_id, order_date) in (
SELECT customer_id, min(order_date)
FROM sales
GROUP BY customer_id
);
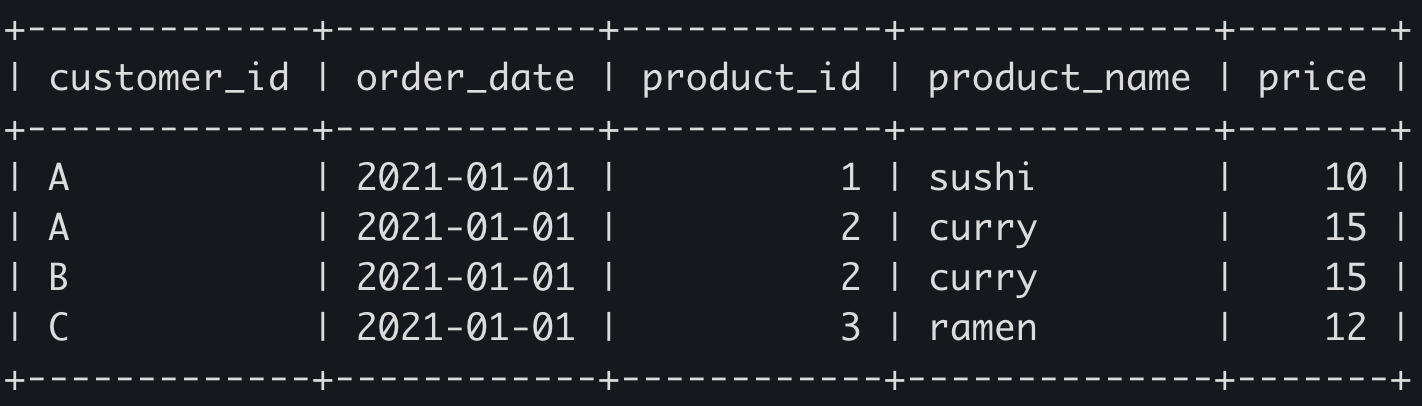
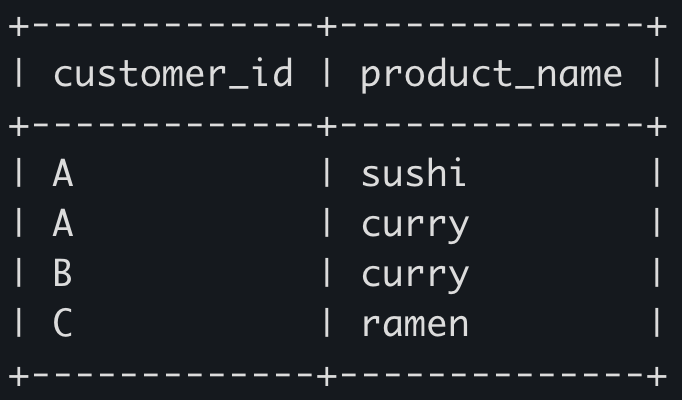
쿼리를 좀만 다듬으면(사실 SELECT절에서 필요한 정보만 뽑도록 하면), 다음과 같이 회원 아이디와 상품명만 추출 가능하다.
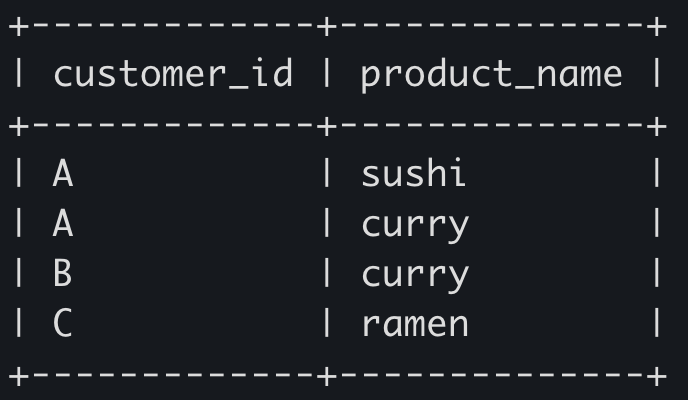
SELECT DISTINCT customer_id, product_name
FROM sales
INNER JOIN menu ON sales.product_id = menu.product_id
WHERE (customer_id, order_date) in (
SELECT customer_id, min(order_date)
FROM sales
GROUP BY customer_id
);
풀이 2 : PARTITION BY를 이용한 접근
그러나 이 문제는 PARTITION BY를 이용해서도 풀 수 있다.
✅ PARTITION BY?
: 특정 그룹 내에서의 집계 또는 순위를 매길 때 사용하는 함수.
(집계함수 : MIN, MAX, SUM 등을 말함)
(순위함수 : ROW_NUMBER, RANK 등을 말함)
🧐 GROUP BY와의 차이점?
: GROUP BY, PARTITION BY 모두 특정 컬럼을 기준으로 레코드들을 그룹핑한다는 공통점이 있다. 그러나 GROUP BY는 그룹핑되는 과정에서 레코드들의 상세 정보들이 없어지는 반면(레코드들이 집약되기 때문), PARTITION BY는 그룹핑돼도 레코드들의 상세 정보가 남아있게 된다.
sales테이블에 대해 회원별로 구매 횟수를 알고 싶다고 할 때, GROUP BY와 PARTITION BY에 대한 다음 결과를 비교해보면 더욱 잘 이해할 수 있다.
1) GROUP BY로 그룹핑해서 계산하는 경우
SELECT customer_id, count(*) as purchased_count
FROM sales
GROUP BY customer_id;
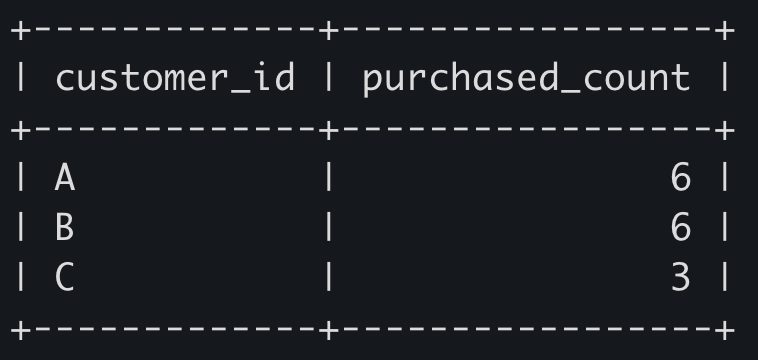
sales 테이블이 갖고 있던 레코드들이 나오는게 아니라, 집계 결과만 나오는 모습을 확인 가능하다. 만약 order_date나 product_id를 SELECT에서 찍어서 보려고 하면, 1055 ERROR가 난다 (GROUP BY가 사용된 경우, GROUP BY로 그룹핑할 때 사용된 컬럼만 SELECT에서 명시가 가능하기 때문)
2) PARTITION BY로 그룹핑해서 계산하는 경우
SELECT customer_id, count(*) OVER (PARTITION BY customer_id) as purchased_count
FROM sales;
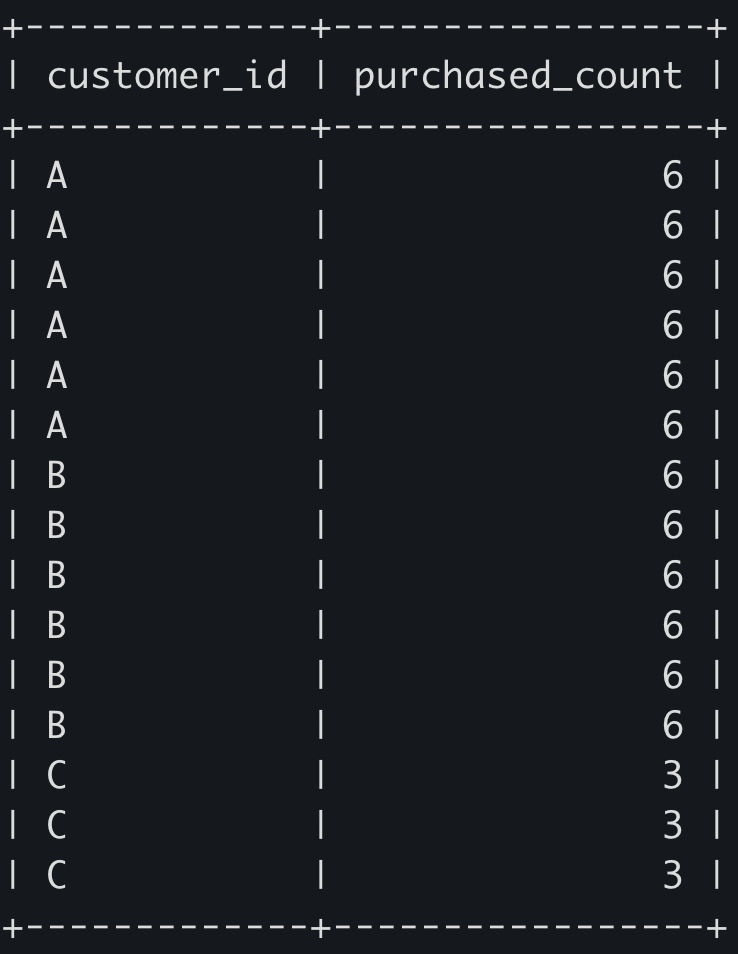
sales테이블이 갖고 있는 레코드들이 살아있음을 확인할 수 있다. SELECT절에서도 order_date, product_id컬럼값을 뽑아낼 수 있으며 에러가 나지 않는다.
SELECT customer_id, order_date, product_id, count(*) OVER (PARTITION BY customer_id) as purchased_count
FROM sales;
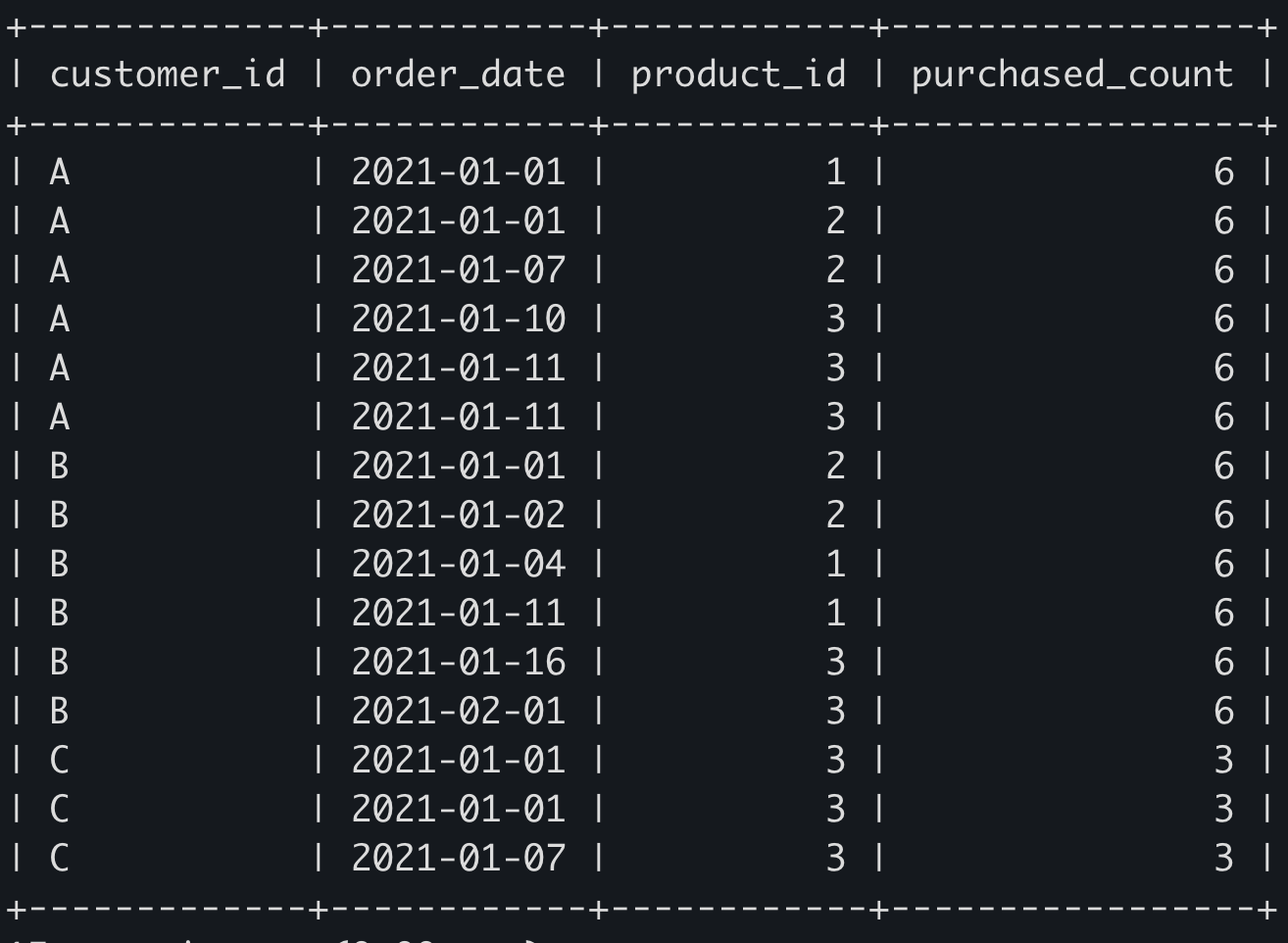
RANK순위 함수와 ORDER BY를 사용하면 그룹핑된 섹션 내에서 order_date를 기준으로 다음과 같이 순위를 매길 수 있다.
SELECT
customer_id,
order_date,
product_name,
RANK() OVER (PARTITION BY customer_id ORDER BY order_date) as order_date_rank
FROM sales
INNER JOIN menu ON sales.product_id = menu.product_id;
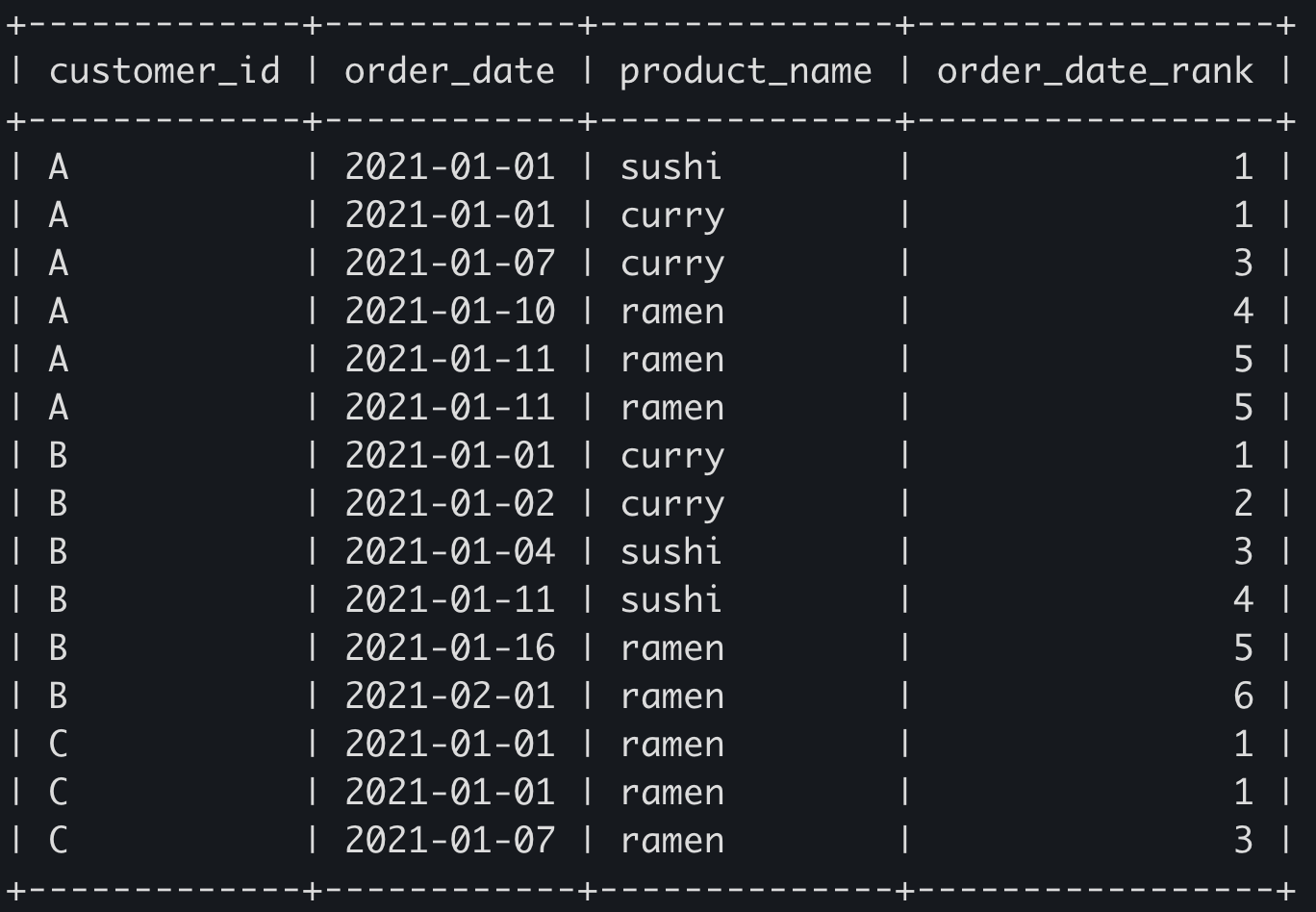
그룹핑된 각 섹션 내에서 order_date값이 같으면 같은 rank가 매겨진다. RANK와는 달리 DENSE_RANK를 사용하면 동일한 등수가 발생해도 다음번 등수는 이전 등수 + 1이 된다.
위 결과를 WHERE절에서 활용, order_date_rank가 1인 레코드만 추출하면 원하는 결과를 가져올 수 있다.
WITH ranked_date as (
SELECT
customer_id,
order_date,
product_name,
RANK() OVER (PARTITION BY customer_id ORDER BY order_date) as order_date_rank
FROM sales
INNER JOIN menu ON sales.product_id = menu.product_id
)
SELECT DISTINCT customer_id, product_name
FROM ranked_date
WHERE order_date_rank = 1;
더 적합한 방식은?
위에서 소개한 GROUP BY와 PARTITION BY 모두 같은 결과를 뱉는다. 그러면 둘 중 어느 것이 좀 더 "적합"할까? 어느 것이 더 효율적으로 동작하는가? 지금은 sales테이블에 데이터가 끽해야 15개 남짓이지만, x억개 있는 상황이라면 뭐가 더 나을까?
쿼리 실행 계획을 살펴보며 어떤 것이 더 나을지 살펴보자.
문제 출처 : 8 week SQL Challenge
https://8weeksqlchallenge.com/
8 Week SQL Challenge
Start your SQL learning journey today!
8weeksqlchallenge.com