리눅스 awk 커맨드 사용법 및 동작 원리
awk 커맨드란
awk programming language라는 프로그래밍 언어로 작성된 프로그램을 실행하는 커맨드.
어떤 파일들로부터 레코드(행)들을 읽어들여서 어떤 값을 조작하거나 데이터화하는 것을 목적으로 패턴 매칭 검사 등에 활용한다.
SQL 쿼리를 통해 내가 원하는 테이블의 row들을 하나씩 보면서 where 조건절에 부합하는 애들만 뽑아내는 것처럼, awk를 통해 특정 파일의 레코드들을 읽으며 비슷한 동작을 해줄 수가 있는 것이다.
간단한 활용 예시
다음과 같은 test.txt파일이 있다고 하자.
seq_num name age score
1 kim 27 100
2 cho 26 99
3 park 24 94
awk를 통해 파일 전체를 출력하려면 다음과 같이 쓴다.
$ awk '{print}' test.txt
seq_num name age score
1 kim 27 100
2 cho 26 99
3 park 24 94
awk를 통해 첫 번째 필드 값만 출력하려면 다음과 같이 쓴다.
$ awk '{print $1}' test.txt
seq_num
1
2
3
awk를 통해 score값(네 번째 필드)이 100점인 사람의 이름만 출력하려면 다음과 같이 쓴다.
$ awk '$4 == 100 {print $2}' test.txt
kim
awk 동작 원리
우선 awk는 입력 데이터(파일을)을 레코드와 필드라는 이름으로 구분한다. RDB 테이블의 행, 열을 떠올리면 이해하기 쉽다.
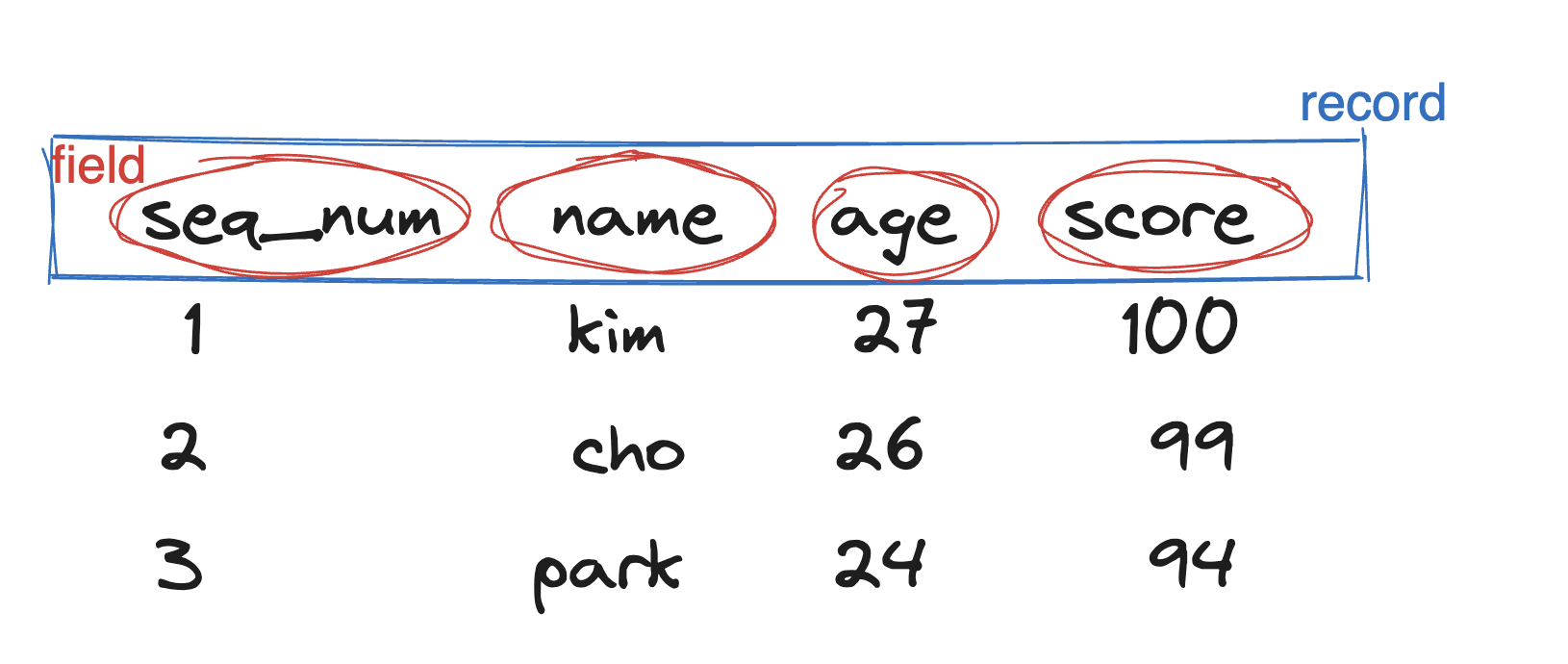
레코드의 텍스트들은 공백 문자(물론 다른 걸로 지정 가능)를 기준으로 각 필드를 구분한다.
레코드 하나하나는 $0값으로 들어오며, 해당 레코들의 각 필드들은 $1부터 채워지게 된다(즉 레코드별 첫 필드 = $1).
이렇게 각 레코드와 필드값들을 채웠으면, "pattern(일종의 조건)과 action(실제 수행할 내용)"을 통해 특정 동작들을 수행하게 된다.
awk 커맨드 구성은 다음과 같다.
$ awk [OPTION] 'pattern { action }' FILE_NAME(or vaiables)
옵션으로 다음 항목들을 사용 가능하다.
- -F : 필드 구분자를 직접 지정한다
- -f : awk program(awk 명령 스크립트) 이 있는 경로를 지정한다 (즉, 'pattern { action }' 부분은 -f가 없을 때 실행될 'awk program'에 해당
- -v : awk program에서 사용될 특정 변수값들을 지정한다
pattern과 action은 둘 다 생략이 가능한 부분이다. pattern이 생략되면 모든 레코드가 적용되고, action이 생략되면 default action인 print가 수행된다.
# pattern을 생략하는 경우
$ awk '{ print }' test.txt # test.txt의 모든 레코드를 출력함
seq_num name age score
1 kim 27 100
2 cho 26 99
3 park 24 94
# action을 생략하는 경우
$ awk '$4 < 100' ./file.txt # test.txt에서 4번째 필드값이 100보다 작은 레코드들 출력함
2 cho 26 99
3 park 24 94
pattern
앞서 봤듯, awk에서 특정 조건에 따라 작업을 처리하게 하는 구성 요소. 크게 세 가지 유형으로 나눌 수 있으며, 이들을 조합하거나 단독으로 사용하여 데이터를 필터링하고 조작할 수 있다.
1. 관계식 패턴
$ awk '관계식패턴 {action}' FILE관계식(비교 연산)을 사용하여 조건에 맞는 라인을 선택하게 한 뒤 action을 수행한다. 필드 값이 특정 조건을 만족하는지 여부를 평가할 때 등에 사용한다.
# ex 1
$ awk '$4 == 100 {print $2}' test.txt
kim
# ex 2
$ awk '$4 < 100' ./file.txt
2 cho 26 99
3 park 24 94
2. 정규표현식 패턴
$ awk '/패턴/ {action}' FILE파일에서 pattern(정규표현식을 활용한)이 포함된 모든 라인을 찾아 해당 라인에 대해 action을 수행한다. 정규표현식은 /들로 둘러싸야 한다.
# ex 1 : k가 들어있는 레코드만 프린트
$ awk '/k/ {print}' test.txt
1 kim 27 100
3 park 24 94
3. BEGIN & AND 패턴
$ awk 'BEGIN {action1} pattern {action2} END {action3}' FILE특수 패턴으로, BEGIN은 입력 데이터로부터 첫 번째 레코드를 처리하기 전 자신에게 지정된 action을 실행하고, END는 모든 레코드를 처리한 다음 자신에게 지정된 action을 실행한다.
# ex 1
$ awk 'BEGIN {print "Start Processing"} {print $1} END {print "End Processing"}' test.txt
Start Processing
seq_num
1
2
3
End Processing
※ 패턴 범위 지정
$ awk 'start_pattern,end_pattern {action}' FILEstart패턴이 처음 나타난 레코드부터 end패턴이 마지막으로 나타난 라인까지의 모든 레코드들에 대해 action을 수행한다. 로그 파일의 특정 섹션을 추출할 때 유용하다.
action
특정 조건(pattern)에 일치하는 레코드에 대해 수행할 작업을 정의하는 부분이다. 중괄호 {} 안에 작성되며, 여러 가지 연산과 명령을 포함할 수 있다. 일반적으로 데이터 처리와 조작을 위해 사용한다.
편의를 위해, pattern은 생략하고 action들의 유형을 설명한다.
1. 출력
$ awk 'pattern {print}' FILE패턴을 만족하는 레코드들을 출력한다.
# ex 1: 4번째 값이 200보다 작은 레코드들을 출력
$ awk '$4 < 200 {print}' test.txt
1 kim 27 100
2 cho 26 99
3 park 24 94
2. 변수 할당
$ awk 'pattern {sum = sum + 1}' FILEpattern을 만족하는 레코드들에 대해 변수를 할당하는 동작을 한다.
# ex 1 : 4번째 필드값이 200이하인 모든 레코드의 4번째 필드값을 합산 후 출력
$ awk 'BEGIN {sum_score = 0} $4 < 200 {sum_score = sum_score + $4} END {print sum_score}' test.txt
293
3. 조건문 사용
$ awk 'pattern {if(조건문) action }' FILEpattern을 만족한 레코드들에 대해 조건문이 true로 평가되면 action을 수행한다. 참고로 else등도 활용 가능하다.
# ex 1: k가 포함된 레코드들에 대해 4번째 필드가 100이하면 해당 레코드를 출력한다
$ awk '/k/ {if($4 < 100) print $0}' test.txt
3 park 24 94
4. 반복문(for, while) 사용
$ awk 'pattern {반복문 action}' FILEpattern을 만족한 레코드들에 대해 반복문을 돌며 action을 수행한다.
# ex 1 : 4번째 필드가 100보다 작은 레코드들에 대해, 1 ~ NF까지 루프를 돌며
# 현재 레코드 번호와 필드값을 출력
$ awk '$4 < 100 {for(i=1; i<=NF; i++) print NR, $i}' test.txt
3 2
3 cho
3 26
3 99
4 3
4 park
4 24
4 94
참고로, NR은 현재 레코드 번호(1부터 시작)를 의미하며 NF는 현재 레코드에 있는 필드값 수를 의미하는 것으로 내장 변수다.
또한 파이썬 등과 마찬가지로 break나 continue의 사용이 가능하다
이 외에도, next라는 action을 통해 다음 레코드로 넘기는 것도 가능하고(일종의 continue), exit를 통해 실행 중이던 awk를 종료시키는 것도 가능하다. 또한 sub, cos같은 다양한 내장 함수도 가지고 있다. 본 글에서처럼 파일에 작성된 값들에 대해 awk를 사용함으로써 데이터 변환 등이 가능하지만, vmstat이나 netstat등의 커맨드 결과를 파이프(|)를 통해 awk의 input으로 줌으로써 모니터링 관리 등에도 활용 가능하다.