한계를 뛰어넘는 자바의 마법, Virtual Thread 뜯어보기
https://youtu.be/pt7cNy7KlpE?si=OUiwPpv_nywXW7ko
들어가며
최근 사내에서 Virtual Thread에 대한 기술 세미나를 열었는데요. 사내 세미나 한 번으로 해당 내용을 묵혀두기는 아까워서 유튜브 영상으로도 공유하고.. 블로그에도 남겨볼려고 합니다. 다만 사내 세미나와 영상에서는 비IT 직무 인원들도 이해할 수 있게끔 최대한 비유를 들며 쉽게 설명하려고 했던 것과 다르게 블로그에는 최대한 기술적으로(?) 작성해보고자 합니다.
Virtual Thread는 JDK21버전부터 공식 Feature로 포함된 기술로, 블록체인이나 AI같이 산업의 변화를 이끌고 있는 기술보다는 성능 최적화를 위해 쓰이는 뒷단의 기술에 가깝습니다. Java를 기반으로 하는 플랫폼이 기존에 어떤 컨셉의 모델을 사용해왔고, 이게 어떤 한계가 있었고, 이를 바탕으로 Virtual Thread가 어떤 목적으로 나온 기술인지 이번 포스트에서 살펴보겠습니다. 그리고 Virtual Thread의 Context Switching, Throughput에 대한 테스트 내용과 사용 시 주의사항에 대해 소개하겠습니다.
목차는 다음과 같습니다.
- Thread per Request & Thread Pool (Java가 전통적으로 사용해 온 방식)
- Reactive Programming의 등장 및 한계
- Virtual Thread의 개념과 장점
- Virtual Thread의 동작 방식 및 원리
- Virtual Thread 테스트 - Context Switching
- Virtual Thread 테스트 - Throughput
- Virtual Thread 주의사항 - Pinning
- 정리
1. Thread per Request & Thread Pool
Spring으로 대표되는 Java 기반 플랫폼은 사용자로부터 하나의 Request가 들어오면 하나의 스레드로 이를 처리하는 Thread per Request라는 방식을 옛날부터 사용해왔습니다. 그러나 매 Request마다 새로운 스레드를 생성하는 것은 비용 부담이 크기 때문에, 미리 일정량의 스레드를 만들어두고 Request가 들어올 때마다 만들어둔 스레드에게 해당 Request의 처리를 맡기는 Thread Pool이란 개념을 사용해왔습니다.

그러나 시간이 흐르며 서비스의 규모가 커지고 Request의 양이 늘어남에 따라, 서비스의 처리량을 늘려야 하는 미션이 생기게 됩니다. 가장 심플한 방법은 스레드풀의 사이즈, 즉 스레드의 개수를 늘리는 것이지만 공간적인 한계 때문에 스레드의 개수가 제한될 수밖에 없었고, 이는 서비스의 처리량이 일정 수준으로 한정되는 결과로 이어졌습니다. 그리고 Java는 자바 스레드(유저 스레드)와 커널 스레드가 1 : 1로 매핑되는 스레딩 모델을 사용하기 때문에, 스레드 간 전환은 곧 커널 스레드간의 전환을 의미하고 이는 Context Switching 비용 부담이 점점 부각되는 문제점을 보이게 됐습니다. 또한 자바 스레드가 I/O 작업 등으로 인해 Blocking되면 매핑된 커널 스레드까지 함께 Blocking됐기 때문에, 만들어둔 스레드들이 실질적으로 task를 수행하는 시간보다 대기하는 시간 즉 idle time이 훨씬 더 많아지는 문제점도 부각되기 시작했습니다.

이런 상황에서 어쨌거나 처리량을 올려야 했고, 가장 단순한 방법인 "스레드 늘리기"는 공간적 제약으로 할 수 없는 상황입니다. 전통적으로 사용해 온 Thread per Request는 하나의 스레드가 하나의 요청을 처리하는 방식인데, "하나의 스레드가 두 개 이상의 요청을 동시에 처리하게 한다면 처리량이 올라가지 않는가?"라는 아이디어가 나오게 됩니다.
※ 이 때의 "동시"는 시간적으로 동시에 한다는 개념이 아니라, 스레드가 대기할 동안 다른 일을 시킨다는 개념입니다.
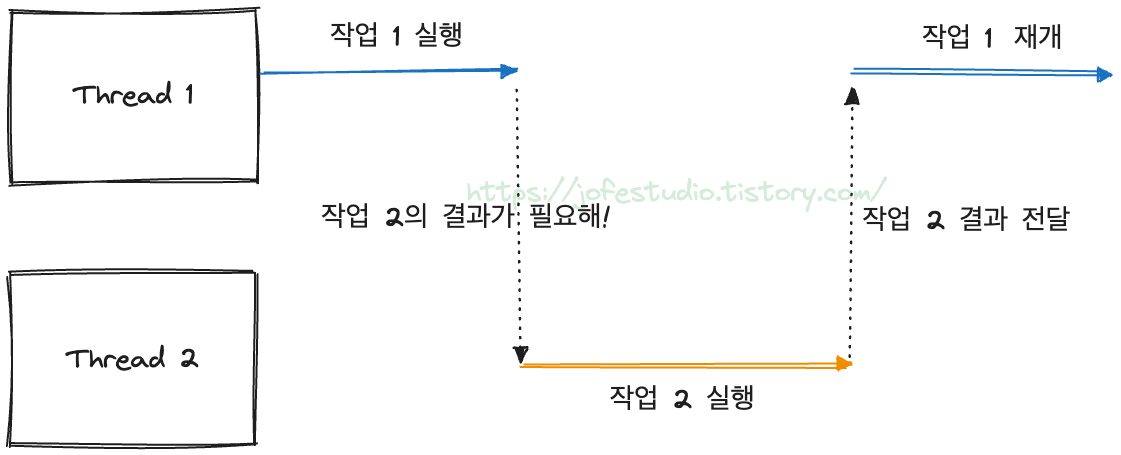

이 아이디어를 바탕으로 Reactive Programming이 등장하게 됩니다.
2. Reactive Programming의 등장 및 한계
"하나의 스레드가 동시에 두 개 이상의 Request를 처리하게 한다"라는 생각을 바탕으로 등장한 비동기 + Non-Blocking 방식의 프로그래밍 패러다임입니다.

컴퓨터 자원을 좀 더 효율적으로 사용할 수 있었기 때문에, Reactive Programming을 통해 더 적은 스레드로 더 많은 Request를 처리할 수 있었습니다. 즉 주어진 미션대로 처리량을 높일 수 있었습니다.
그러나.. Reactive Programming은 다음과 같은 단점들이 있었습니다.
1. 높은 진입장벽
"하나의 스레드가 동시에 두 개 이상의 Request를 처리하게 한다"라는 것은 기존의 동기적인 관점에서 벗어나 비동기라는 관점에서 프로그래밍을 해야 했습니다. 그렇다보니 러닝커브가 높아지게 됐고, 이는 기존에 사용하던 동기적인 방식의 코드와 로직을 전환하는 것에도 부담이 되는 요소로 작용하게 됐습니다. 여러 로직이 맞물릴 때, 하나만 비동기로 바꾸면 되는 게 아니라 전체를 비동기로 바꿔야 하기 때문인 것도 있습니다.
2. 직관적인 코드 이해의 어려움
기존의 동기적인 관점에서 코드를 작성할 땐, 주어진 비즈니스 요구사항 즉 비즈니스 프로세스가 이 코드에 잘 반영됐는지 파악하는 것이 상대적으로 쉬웠습니다. 또한 새로운 기능을 추가해야 할 때, 기존 코드의 어느 부분에 추가해야 할지 판단하는 것도 어렵지 않았습니다. 하지만 Reactive Programming에서는 우리의 비즈니스 프로세스가 이 코드에 잘 반영됐는지, 새로운 기능을 추가한다면 어느 부분에 추가해야 하는지를 판단하는 것이 상대적으로 어려웠습니다. 1번과 이어지는 얘기지만, 결국 Reactive Programming은 프로그래밍 패러다임, 즉 프로그래밍을 하는 관점 자체를 달리 하는 것이 원인인 것이죠.
3. 어려워진 디버깅, 예외처리
기존에는 Thread per Request, 하나의 스레드가 하나의 Request을 처리하는 컨셉이었기 때문에, 문제가 발생하면 콜스택 등을 통해 디버깅하거나 예외처리를 해주는 것이 상대적으로 쉬웠습니다. 그러나 Reactive Programming은 Request(다른 말로는 task)를 여러 스텝으로 쪼개고 각 스텝들을 파이프라인(다른 말로는 스트림) 형태로 엮어서 여러 스레드에서 처리하게 됩니다. 그렇다보니 콜스택을 통해 디버깅하거나 예외처리하는 것이 상대적으로 어려워지게 됐습니다.
정리하면, Reactive Programming을 통해 분명 처리량을 높일 수 있었습니다. 하지만 그에 반비례해서 개발 생산성이 떨어진다는 리스크가 있었죠. "Reactive Programming 이거 분명 잘 쓰면 좋아. 근데 잘 쓰기가 너무 어려워!"라는 문제점이 점점 부각되기 시작했습니다.
그래서 다시 Thread per Request & Thread Pool 이라는 원점으로 돌아옵니다. 주어진 미션은 여전히 "처리량을 높이는 것"입니다. 하지만 여기에 한 스푼 더 얹어서 "기존의 동기적인 코드 흐름을 유지할 순 없을까?" 라는 욕심이 들기 시작합니다. 이를 충족시키는 가장 간단한 방법은 역시나 "스레드 개수 늘리기"이지만, 공간적인 제약 때문에 그렇게 할 수 없었죠. (스레드는 메모리에서 2MB정도까지 공간을 차지할 수 있다고 합니다) 근데 여기서, "그러면 스레드를 가볍게 만들면 엄청 많이 만들 수 있는 거 아냐?" 라는 관점이 나오기 시작합니다.
이 아이디어를 바탕으로, 스레드를 가볍게, "경량"으로 만들어서
- 서비스의 처리량 향상
- 기존의 동기적인 코드 흐름 유지
라는 2개의 목표를 달성하기 위해 본 포스트의 메인 주제인 Virtual Thread가 등장하게 됩니다.
3. Virtual Thread의 개념과 장점

앞서 말씀드렸듯이 Java가 사용하는 스레딩 모델은 자바 스레드와 커널 스레드의 1 : 1로 매핑 모델입니다. CPU의 실질적인 스케쥴링 대상은 커널 스레드로, 커널 스레드가 CPU를 점유하면 그에 매핑된 자바 스레드가 수행되는 구조로 이해할 수 있습니다. Virtual Thread는 기존의 자바 스레드보다 더 가벼운 스레드를 만들어 하나의 자바 스레드에 다수의 Virtual Thread가 매핑시키는 구조로, 커널 스레드가 CPU를 점유하면 매핑된 자바 스레드에 mount된 Virtual Thread가 실행되는 개념입니다.
동작 과정도 간단히 살펴보면, 기존에는 자바 스레드가 Blocking되면 매핑된 커널 스레드까지 Blocking되는 구조였습니다. 그러나 Virtual Thread는 실행 중 Blocking된다면 mount되어 있던 자바 스레드에서 unmount되고, 다른 Virtual Thread가 자바 스레드에 mount되어 실행되는 구조입니다. 따라서 실질적으로 CPU를 점유하고 있는 커널 스레드는 Blocking되지 않게 됩니다.
이러한 특징 덕분에, Virtual Thread 사용 시 기존에 사용하던 동기적인 코드 흐름을 그대로 유지할 수 있으면서도, 내부적으론 비동기 방식과 비슷하게 동작하게 되어 Non-Blocking 처리가 가능해져 처리량을 높일 수 있게 됩니다. 또한 기존 스레드 간의 Context Switching은 커널 레벨에서 발생하지만 Virtual Thread간의 Context Switching은 유저 레벨에서 발생한다는 특징이 있는데요, 이를 통해 Context Switching 비용을 좀 더 아낄 수 있게 된다는 장점도 있습니다.
구체적인 동작 방식을 통해 좀 더 살펴보겠습니다.
4. Virtual Thread의 동작 방식 및 원리
0. Virtual Thread 주요 구성 요소
동작 방식 설명 전 Virtual Thread의 주요 구성 요소들을 살펴보면 다음과 같습니다.

1) ForkJoinPool
Virtual Thread들의 static 멤버(즉 모든 Virtual Thread가 공유)로, Virtual Thread들을 스케쥴링하는 스케쥴러 역할을 합니다.
2) Carrier Thread
Virtual Thread이 mount되어 실행되는 실질적인 자바 스레드이며, Carrier Thread들은 저마다 하나씩 WorkQueue라 불리는 work-stealing 방식으로 동작하는 큐를 가집니다. 논리적인 관점에서 Carrier Thread는 Virtual Thread와 1 : N의 매핑 관계를 가지며, Carrier Thread와 커널 스레드는 1 : 1의 매핑 관계를 가집니다.
※ work-stealing : Carrier Thread들이 자신의 workQueue에 아무 것도 없으면 다른 Carrier Thread의 workQueue에 있는 걸 훔쳐와서 사용하는데, 이를 work-stealing이라고 표현합니다.
3) Continuation
Virtual Thread가 실행해야 하는 작업과 그 작업에 대한 정보(어디까지 실행했는지 등)을 가지는 객체입니다.
4) runContinuation
Continuation을 실질적으로 실행시키는 일종의 람다식입니다.
1. 동작 방식 - Virtual Thread가 Carrier Thread에 mount되는 과정

기존 자바 스레드는 start 메서드를 호출하면 start0라는 native 메서드를 거쳐 JNI를 통해 해당 자바 스레드와 매핑될 새로운 커널 스레드를 생성하게 됩니다. 반면 Virtual Thread는 start메서드 호출 시 submitRunContinuation 메서드가 호출되고, 스케쥴러(ForkJoinPool)의 execute 메서드가 호출됩니다. 그러면 스케쥴러가 적당한 Carrier Thread를 하나 골라 runContinuation을 해당 Carrier Thread의 WorkQueue에 넣어주게 됩니다. 이후 Carrier Thread가 본인의 WorkrQueue에 들어있는 runContiation을 뽑아 실행시키면 Virtual Thread와 Carrier Thread가 mount되고 Virtual Thread가 실행됩니다.
2. 동작 방식 - Virtual Thread가 실행 중 Blocking될 때 unmount되는 과정

Virtual Thread가 실행되다가 I/O 요청 등으로 인해 Blocking되면 내부적으로 park메서드가 호출됩니다. park메서드는 doYield라는 native 메서드를 거쳐 JNI를 통해 jvm단에서 memcpy라는 표준 C 라이브러리 함수를 호출하게 됩니다. Virtual Thread가 사용 중이던 스택 프레임을 Heap에다가 복사해두는 기능을 수행하는 것이며, 이를 통해 나중에 Blocking이 끝나고 Virtual Thread가 재개될 때 중단 지점부터 재개하는 것이 가능해집니다. 참고로 CPU에서 사용되던 PC 레지스터 값 등도 함께 Heap에 복사되는 과정도 코드를 분석해보면 보실 수 있습니다. (저는 GitHub에 있는 openjdk를 뜯어봤습니다)
이런 과정을 거치며 unmount가 진행되고, Carrier Thread는 다른 Virtual Thread와 mount되게 됩니다.
3. 동작 방식 - Blocking됐던 Virtual Thread가 다시 재개되는 과정

Blocking상태가 끝나면 내부적으로 unpark() 메서드가 호출되며, 다시 submitRunContinuation이 호출되면서 Carrier Thread의 WorkQueue에 runContinuation필드가 들어갑니다. 이후 Carrier Thread가 이를 뽑아내서 mount할 때 아까 Heap에 복사해뒀던 스택 프레임을 다시 복구시켜서 중단 지점부터 작업을 재개합니다.
4. Virtual Thread 동작 방식 최종 정리

- Virtual Thread는 Carrier Thread의 WorkQueue에서 work-strealing 방식으로 mount되어 실행됩니다.
- mount된 Virtual Thread는 실행이 끝나면 다른 Virtual Thread로 갈아끼워집니다. (Context Switching)
- mount된 Virtual Thread는 실행 중 Blocking되면 현재까지의 실행 정보(스택 프레임)를 Heap에 저장하고 다른 Virtual Thread로 갈아끼워집니다. (Context Switching)
- Blocking이 끝난 Virtual Thread는 mount될 때 Heap에 저장해둔 스택 프레임을 불러와 중단 지점부터 다시 작업을 재개합니다.
5. Virtual Thread 테스트 - Context Switching
앞서 살펴본 것처럼 Virtual Thread 간의 Context Switching은 Virtual Thread의 실행이 끝났을 때 또는 Virtual Thread가 실행되다가 Blocking됐을 때 발생합니다. 그리고 이 과정은 코드 레벨에서 살펴봤듯 스택 프레임을 Heap에 저장하는 과정 등을 거치며 유저 레벨에서 발생됩니다. (참고 : 스택 프레임을 Heap에 복사할 때 사용되는 memcpy는 표준 C 라이브러리 함수로 시스템콜이 아닙니다)
코드 상에선 그렇게 확인했지만, 실제로 Virtual Thread간의 Context Switching이 유저 레벨에서 발생하는지를 직접 검증하고 싶었습니다. 그래서 다음과 같은 코드를 준비했습니다. 코드 상에서 회사명이 나오는 부분들은 가렸습니다.

총 200개(THREAD_COUNT)의 자바 스레드를 만들고, 각각의 스레드가 10ms 동안 대기하는 과정을 100번(ITERATIONS)만큼 반복하여, 프로그램 실행 중 최소 20,000번(THREAD_COUNT X ITERATIONS) 이상의 Context Switching이 발생하도록 합니다. 동일한 코드를 Virtual Thread를 활용한 방식으로도 작성해줍니다.

이 각각의 프로그램들을 컴파일한 뒤, Linux에서 제공하는 커널 퍼포먼스 측정 도구인 perf를 활용해 각 프로그램을 실행하는 과정에서 Context Switching이 몇 번 발생했는지 측정해줍니다. 이때 커널 레벨에서 발생한 Context Switching이 측정되는 것이므로, 정말 Virtual Thread가 Context Switching이 유저 레벨에서 발생한다면 기존 스레드를 사용했을 때가 Context Switching 횟수가 더 높게 측정될 것임을 예측할 수 있습니다.
총 3번씩 측정했으며, 결과는 다음과 같습니다.


| 기존 스레드 | Virtual Thread | |
| Context Switching 횟수 | 약 19,900 / s | 약 5,300 / s |
| 유저 모드, 커널 모드 실행 시간 비율 | 약 1.3 : 1 | 약 6.2 : 1 |
물론 이 테스트에서 기존 스레드는 커널 스레드가 생성되는 과정이 함께 측정되는 부분도 감안해야 합니다. 그러나 Virtual Thread를 사용한 프로그램이 기존 스레드를 사용한 프로그램보다 3배 이상 커널 레벨에서 Context Switching이 덜 발생했고, 유저 모드와 커널 머드에서의 실행 시간 비율을 볼 때도 Virtual Thread를 사용했을 때가 유저 레벨에서 실행된 비율이 더 높음을 쉽게 파악할 수 있습니다. 이를 통해 Virtual Thread간의 Context Switching이 유저 레벨에서 발생한다는 것을 실질적으로 확인할 수 있었고, 따라서 Virtual Thread를 통해 Context Switching 비용을 줄일 수 있음을 도출할 수 있습니다.
6. Virtual Thread 테스트 - Throughput
이번에는 Virtual Thread 사용시 정말 처리량을 높일 수 있는지를 테스트해봤습니다. 실제 업무에서 쓰이는 API에 테스트해보면 좋겠지만 그럴 수 없던 관계로.. 다음과 같이 Spring Boot를 활용해 간단히 2개의 API를 만들어줬습니다.
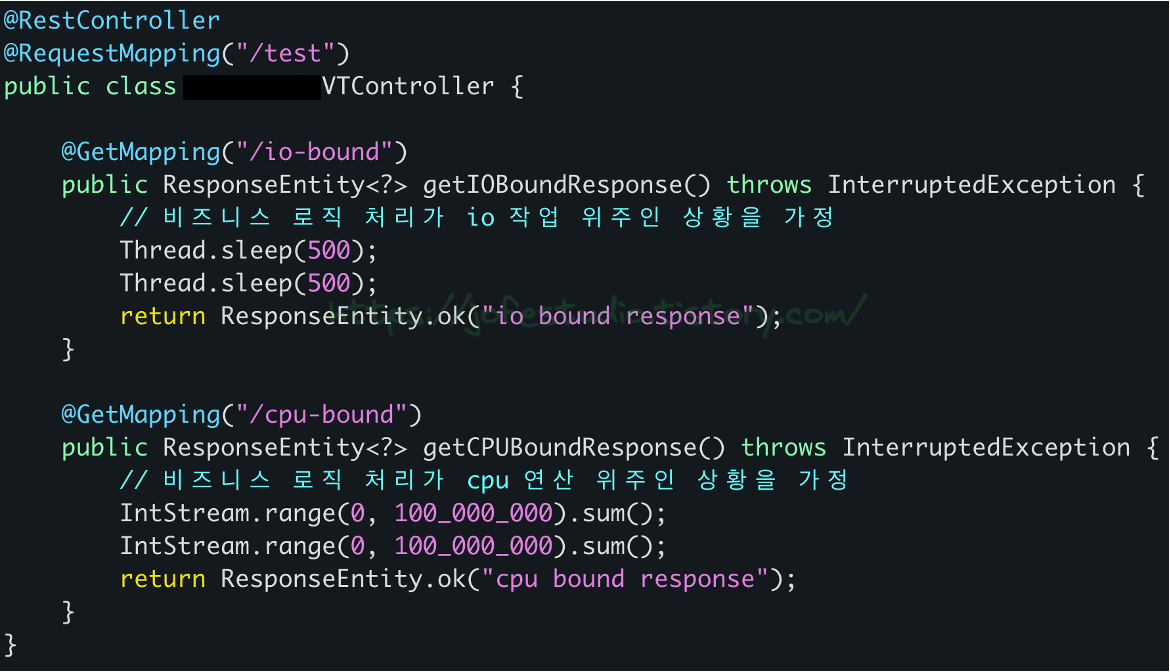
첫 번째로는 500ms씩 2번 Sleep하게 하는 API를 만들어주고, 두 번째로는 1부터 1억까지의 연산을 2번 반복하는 API를 만들어줘서 각각 I/O 작업 위주로 비즈니스 로직을 처리하는 상황과 CPU 연산 위주로 비즈니스 로직을 처리하는 상황을 가정해줍니다. 이를 토대로 I/O Bound 상황과 CPU Bound 상황에 대해, 기존 스레드 사용 시와 Virtual Thread의 사용 시의 처리량을 측정해봅니다.
테스트 환경은 다음과 같습니다.
- Ubuntu 24.04
- 2 core CPU / 4GB RAM
- Spring Boot 3.3.4 / OpenJDK21
- K6로 VU를 2,000까지 늘리며 진행, 각 3회씩 측정
먼저 I/O Bound 상황에 대한 결과입니다.

| TPS | Response Time (avg) | |
| Virtual Thread - 1회 | 911 | 1.06 s |
| Virtual Thread - 2회 | 881 | 1.07 s |
| Virtual Thread - 3회 | 839 | 1.08 s |
| 기존 스레드 - 1회 | 189 | 5.27 s |
| 기존 스레드 - 2회 | 188 | 5.27 s |
| 기존 스레드 - 3회 | 189 | 5.27 s |
물론 간단한 코드를 기반으로 테스트한 것이므로 해당 결과가 실제 운영 환경을 대변하진 않습니다. 그래도 결과를 해석해보면, I/O Bound 상황에서 Virtual Thread는 Non-Blocking 처리가 가능하기 때문에 기존 스레드보다 더 높은 처리량을 보이고 있음을 눈으로 확인해볼 수 있습니다. 또한 Spring Boot에 내장된 톰캣의 스레드풀 사이즈를 별도로 설정해주지 않아 스레드풀 사이즈가 디폴트값인 200으로 만들어졌었는데요. 500ms씩 2번, 총 1초 정도를 대기하도록 API를 구성했기 때문에 기존 스레드를 사용한 결과가 TPS가 200 가까이는 올라가지만 200을 넘지 못하고 있는 것도 확인해볼 수 있었습니다.
다음으론 CPU Bound 상황에 대한 결과입니다.

| TPS | Response Time (avg) | |
| Virtual Thread - 1회 | 21 | 28.19 s |
| Virtual Thread - 2회 | 20 | 28.40 s |
| Virtual Thread - 3회 | 20 | 28.38 s |
| 기존 스레드 - 1회 | 23 | 27.10 s |
| 기존 스레드 - 2회 | 24 | 26.91 s |
| 기존 스레드 - 3회 | 23 | 27.12 s |
마찬가지로 이 결과가 운영 환경을 대변하진 않지만, 결과를 보면 CPU Bound 상황에서는 Virtual Thread 사용시 오히려 처리량이 낮아지는 걸 볼 수 있습니다. Virtual Thread는 앞서 살펴본 것처럼 실행 시 Carrier Thread의 WorkQueue에 들어갔다가 mount되고, 다 끝난 뒤엔 unmount를 하는 과정 등을 거칩니다. 따라서 작업을 실행하는 데 드는 비용 자체는 기존 스레드가 Virtual Thread보다 더 저렴합니다. Blocking을 처리하는 비용이 Virtual Thread가 기존 스레드보다 훨씬 더 저렴한 것이죠. 따라서 작업을 실행하는 도중에 Blocking이 발생하지 않는 경우라면 오히려 Virtual Thread를 사용하는 것이 안티 패턴이 될 수도 있음을 도출할 수 있습니다. 이 테스트에서 사용된 CPU Bound 상황에 대한 것을 그 예로 볼 수 있습니다.
7.Virtual Thread 주의사항 - Pinning
Virtual Thread는 Carrier Thread에 mount되어 수행되다가, Blocking되면 Carrier Thread로부터 unmount된다고 소개했습니다. 근데 Virtual Thread가 Carrier Thread에 mount된 상태로 고정되어, Blocking이 발생해도 unmount가 되지 않는 상황이 발생할 수 있습니다. 이를 Pinning현상(Pinned 현상이라고도 부릅니다)이라고 부르며, 다음 상황에서 발생합니다.
- Virtual Thread에서 synchronized 블록 사용 시
- Virtual Thread에서 native method 사용 시
synchronized 블록은 모니터 락을 사용하여 동시 접근을 제어하는데, Virtual Thread가 아닌 Carrier Thread 수준(jvm 단)에서 이 락을 잡다보니 락을 획득한 Carrier Thread가 연관된 작업을 처리하는 동안 다른 작업을 처리할 수 없도록 고정되는 것이 원인입니다. Native method 역시 비슷한 이유로 고정됩니다. 이렇게 Pinning 현상이 발생하면 Virtual Thread의 장점이자 존재 이유(?)인 "Blocking 시 갈아끼우기"를 시전할 수 없게 되므로 성능 저하의 직접적인 원인이 될 수 있습니다.
Pinning 현상을 직접 테스트하기 위해 다음과 같은 코드를 준비했습니다.



2개의 Virtual Thread를 만들어 실행하는데, 각 Virtual Thread는 현재 스레드의 정보를 로그로 남기고, 2초 대기하다가 다시 스레드의 정보를 로그로 남기는 메서드를 실행하도록 합니다. 이 때 run이란 메서드를 synchronized로 묶지 않았을 때와 묶을 때 각각 어떻게 결과가 나오는지를 테스트합니다.
참고로 Carrier Thread는 여러 개가 만들어질 수 있는데, 제가 만든 2개의 Virtual Thread가 서로 다른 Carrier Thread에 mount되어 실행된다면 이 테스트는 의미가 없습니다. 따라서 다음과 같이 옵션을 줘서 Carrier Thread가 하나만 만들어지게 하고 테스트를 진행했습니다.
-Djdk.virtualThreadScheduler.parallelism=1
-Djdk.virtualThreadScheduler.maxPoolSize=1
-Djdk.virtualThreadScheduler.minRunnable=1
테스트 결과는 다음과 같습니다.


우선 로그에 남아있는 스레드 정보가 ForkJoinPool-1-worker-1로 동일하기 때문에, 하나의 Carrier Thread에서 Virtual Thread들이 실행됐음을 볼 수 있습니다. Pinning이 발생하지 않은 경우 VT1이 먼저 로그를 찍고 sleep에 들어가면서 VT2로 갈아끼워지게 되고, VT2도 로그를 찍은 뒤 sleep에 들어가게 된 것을 볼 수가 있습니다. 2초 뒤에 VT1, VT2 둘 다 깨어나면서 로그를 찍게 되므로 전체 실행 시간이 약 2초임을 볼 수 있습니다. 반면 Pinning이 발생한 경우 VT1이 먼저 로그를 찍고 sleep에 들어가지만 VT2로 갈아끼워지지 못하게 되고, 2초 뒤에야 VT2로 갈아끼워지면서 전체 실행 시간이 4초 정도로 나오는 것을 볼 수 있습니다.
이를 통해 실질적으로 Virtual Thread 사용 중 Pinning이 발생한다면 성능 저하의 원인이 될 수 있음을 도출했습니다. Pinning이 발생된 구간에서 Blocking이 발생하지 않는다고 해도, 앞서 말씀드린 것처럼 작업을 실행하는 비용 자체는 기존 스레드가 더 저렴하기 때문에 Virtual Thread 사용 시 Pinning이 발생하지 않도록 주의할 필요가 있습니다.
글을 작성하는 시점인 24년 10월 9일 현재, Pinning에 대해 다음과 같이 조치할 수 있습니다.
- synchronized block은 ReentrantLock으로 대체
- native method 사용은 최애한 지양
참고로 현재 여러 Java Library들이 Virtual Thread와의 호환을 위해 내부적으로 사용하던 synchronized를 ReentrantLock으로 바꾸는 작업을 진행하고 있습니다.

8. 정리
1) 그래서 언제 쓰면 좋을까?
우선 다시 한 번 상기할 점은 작업을 실행하는 데 드는 비용 자체는 기존 스레드가 더 저렴하나, Blocking 처리 비용이 Virtual Thread가 훨씬 저렴하다는 것입니다. 또한 Virtual Thread는 지연시간이 아닌 처리량을 높이는 기술이므로, API 응답 시간을 줄이는 것 등이 주어진 미션일 때는 Virtual Thread 도입을 권장하지 않습니다.
현재 시스템이 Thread per Request를 기반으로 하는 Spring mvc 등을 사용 중일 때 Virtual Thread를 도입을 고려할 수 있습니다. 만약 현재 시스템이 Reactive Programming의 대표 격인 Spring Webflux 등을 사용 중이라면, Virtual Thread와는 패러다임 자체가 다르므로(Reactive Programming인 비동기, Virtual Thread는 동기) Virtual Thread 도입은 안티 패턴이 될 수 있습니다.
또한 현재 시스템이 받는 워크로드가 I/O 작업 위주이며, 시스템의 주 병목 원인이 이 I/O 작업들 위주인 것이 분명하다면 Virtual Thread 도입 시 처리량 향상을 꾀할 수 있습니다. 만약 워크로드가 CPU 연산 위주라면, 아까 살펴본 것처럼 Virtual Thread의 도입은 안티 패턴이 될 수 있습니다.
2) Virtual Thread 도입 시 검토해볼 것들
Pinning 발생을 방지하기 위해, 사용 중인 코드나 사용 중인 라이브러리 또는 프레임워크 내부에 synchronized 등을 사용하는 곳이 있는지 검토해야 합니다. -Djdk.tracePinnedThreads 옵션을 통해 Pinning을 trace할 수 있으며, 특히 Pinning이 발생한 구간에서 Blocking되는 부분이 있는지도 검토해야 합니다.
그리고 Virtual Thread 사용 시, 시스템과 연동되는 타 시스템으로 폭발적인 트래픽 전파가 발생할 수 있음을 주의해야 합니다. 처리량이 올라가게 되면, 평소에 다른 시스템으로 10개의 요청을 보내다가 갑자기 100개 1,000개 10,000개 이상의 트래픽을 보내게 될 수 있습니다. Virtual Thread에는 배압을 조절하는 기능이 아직 없다보니, 상대 시스템도 이러한 트래픽을 처리할 수 있는 능력(?)이 되는지를 검토해볼 필요가 있습니다. 특히 DB connection같은 한정된 개수의 자원에 접근하는 경우, 내가 보낸 요청들이 되려 timeout이 나면서 떨어질 수 있는 가능성도 있습니다. 현재는 세마포어를 통해 배압을 조절하는 것이 권장되고 있으나, 결국 개발자 본인들이 Virtual Thread를 통해 해당 내용에 대해 인지하고 있을 필요가 있습니다.
이 외에도, Virtual Thread는 기존 스레드와 달리 매우 많은 수가 생성될 수 있으므로 ThreadLocal 등을 사용하는 곳이 있는지 검토할 필요가 있습니다.
정리하면, Virtual Thread를 실질적으로 도입하게 될 경우
- 우리가 사용 중인 라이브러리 등의 대응이 가능한가?
- 우리 서비스가 놓여진 인프라가 뒷밤침될 수 있는가?
를 검토해야겠습니다.
참고한 레퍼런스
https://junhkang.tistory.com/37
https://velog.io/@kimyj1234/Java-가상-스레드-Virtual-Thread
https://kkyu0718.tistory.com/126
https://findstar.pe.kr/2023/04/17/java-virtual-threads-1/
https://tech.kakaopay.com/post/ro-spring-virtual-thread/
https://spring.io/blog/2022/10/11/embracing-virtual-threads
https://dev.java/learn/new-features/virtual-threads/
https://dzone.com/articles/the-long-road-to-java-virtual-threads
https://d2.naver.com/helloworld/1203723
https://notypie.dev/java-virtual-thread-와-platform-thread/
https://dev.to/elayachiabdelmajid/java-21-virtual-threads-1h5b
https://nomoresanta.tistory.com/4
https://velog.io/@appti/Virtual-Thread