위치 기반 서비스를 위한 아키텍처 설계 - 근접성 서비스
※ 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2권 - 챕터 1을 읽고 정리한 글입니다.
들어가며
근접성 서비스(Proximity Service)란 특정 위치를 기반으로 가까운 시설을 찾는 서비스를 의미합니다. 예를 들어 주변 맛집 찾기 서비스를 설계한다고 할 때, 2차원 형태(위도, 경도)로 표현되는 공간 데이터를 빠르게 검색하는 기술에 대한 이해를 바탕으로 아키텍쳐를 설계할 필요가 있습니다. 공간 데이터를 검색하는 기술들을 설펴보고, 그 중 지오해시(Geohash)를 기반으로 한 아키텍처 설계 방법에 대해 소개하겠습니다.
공간 데이터 검색 기술
다음과 같이 특정 위치와 반경을 기반으로 주변의 시설들을 검색하는 방법들에 대해 살펴보겠습니다.
1) 가장 단순한 공간 데이터 검색 : 2차원 검색
가장 단순한 방법입니다. 주어진 반경값을 토대로 검색해야 하는 위도와 경도의 범위를 계산하여 검색에 활용하는 방법입니다. 그러나 별도의 인덱스 설정이 없으면 테이블 전체를 풀 스캔해야 하는 단점이 있습니다. 위도와 경도에 인덱스를 달아둔다고 해도, 각 인덱스를 통해 얻어낸 두 집합의 교집합을 구해야 하는 데서 많은 비용이 발생합니다. 이런 문제들은 기본적으론 DB 인덱스가 한 차원의 검색 속도를 개선시키는 것에서 비롯되므로, 2차원의 공간 데이터에 대한 인덱스 생성 방법을 고려할 필요가 있습니다.
공간 데이터에 대해 인덱스를 만드는 방법은 다음과 같이 분류 가능합니다.
- Hash 기반
- 균등 격자 (even grid)
- 지오해시 (Geohash)
- 카르테시안 계층 (Cartesian tiers)
- 트리 기반
- 쿼드트리 (Quadtree)
- 구글 S2
- R-tree
각 기술들의 세부 구현 방법은 서로 다르지만, 기본적으로는
- 공간을 여러 작은 영역들로 분할
- 공간 데이터들을 분할된 영역들로 매핑 (2차원 데이터가 1차원 데이터로 매핑되는 효과)
- "분할된 영역"들을 빠르게 검색
하는 형태로 인덱스가 활용된다고 보면 됩니다. 여기서는 균등 격자와 지오 해시, 쿼드 트리 및 R-tree에 대해 소개하겠습니다.
2) Hash 기반 공간 데이터 검색 : 균등 격자
2차원 공간을 다음과 같이 균일한 크기를 가진 격자로 나누는 접근법입니다.

각 격자들에 1부터 시작하는 식별자 번호를 할당할 수 있고, 공간 데이터들을 각 격자들로 매핑시켜 활용할 수 있게 됩니다. 그러나 뒤에서 소개할 다른 방법들과는 달리 격자 식별자를 할당하는 방법에 명확한 체계가 있는 방식은 아니기 때문에, 특정 격자 주변에 있는 격자를 찾는 것이 어렵다는 단점이 있습니다. 우리의 목적인 "특정 위치와 반경을 기반으로 주변의 시설을 검색하기"를 위해서는 인접한 격자를 쉽게 찾을 수 있어야 하지만 그 부분에 제약이 걸리는 것으로 볼 수 있습니다. 또한 각 격자별로 갖는 공간 데이터들의 분포가 균등하지 않다는 단점도 있습니다.
3) Hash 기반 공간 데이터 검색 : 지오해시
균등 격자와 비슷하게 2차원 공간을 균일한 크기를 가진 격자로 나누고 격자들에 식별자를 할당합니다. 다만 식별자 할당에 체계가 있다는 차이점이 있습니다.

2차원 공간을 그림처럼 4개로 나눈 후, 위도 경도의 범위를 기준으로 4개 영역에 비트값을 할당합니다. 다시 각 격자를 4개로 나눈 후, 각 영역에 비트값을 추가하는 과정을 원하는 정밀도(즉 격자의 크기)가 나올 때까지 반복합니다. 이렇게 나온 비트값을 base 32 표현법으로 인코딩해 나온 문자열을 지오해시라고 부릅니다.
ex) 비트값이 "1001 11010 01001 10001 11111 11110" 이면 지오해시는 "9q9hvu"
지오해시의 길이가 길수록 정밀도가 높은 것(사이즈가 작은 격자들로 분할된 것)을 의미하며, 지오해시의 길이에 따라 총 12 레벨로 분류할 수 있습니다. 길이 1짜리인 1레벨은 지구 전체에 해당(즉 격자 1개)하고 길이 12짜리인 12레벨은 격자 하나의 사이즈가 3.7cm X 1.9cm입니다. 일반적인 경우 4 ~ 6레벨을 사용하며, 사용자가 지정한 반경으로 그린 원을 덮는 최소 크기 격자를 만드는 지오해시 길이를 최적 정밀도로 계산할 수 있습니다.
ex) 지정한 반경이 1km일 때, 지오해시 레벨이 5인 격자의 크기가 4.9km X 4.9km으로 지정된 반경으로 그린 원을 덮을 수 있는 최소 크기 격자가 됩니다. 레벨 6짜리 격자의 크기는 1.2km X 0.6km입니다.
앞서 살펴봤듯이, 지오해시는 격자를 4개로 나눈 후 원래 가지던 비트값 뒤에 01, 11, 00, 10을 추가하는 식으로 식별자 할당이 진행됩니다. 따라서 이 비트값들을 base 32로 인코딩한 지오해시값들은 비슷할 수밖에 없고, 이를 통해 "공통접두어가 긴 격자들은 인접해있다"를 도출할 수 있습니다. 또한 뒤에 붙어있는 비트값을 떼주면, 해당 격자를 포함하는 좀 더 넓은 격자로 범위를 확장시킬 수 있습니다. 따라서 지오해시는 이 점들을 활용해 범위 기반 지역 검색을 쉽게 할 수 있게 됩니다.
다만 하나의 격자만 볼 때는 균등 격자와 마찬가지로 각 격자별로 갖는 공간 데이터들의 분포가 균등하지 않다는 단점은 남아있으며, 공통접두어가 긴 격자들은 인접하다라는 명제는 성립하나 "인접한 격자들은 공통접두어가 같다"는 성립하지 않음에 유의해야 합니다. 이유는 다음 그림과 같이 인접한 격자임에도 비트값들은 서로 완전히 다를 수 있기 때문입니다.

4) 트리 기반 공간 데이터 검색 : 쿼드트리
지오해시는 격자들에 할당된 식별자들을 DB에 저장해 가지는 방식이었다면, 쿼드트리는 격자를 재귀적으로 4개로 쪼개가며 만든 트리를 메모리에 둔 채로 활용하는 방식입니다. 구체적으로는 트리의 리프노드들에 담긴 공간 데이터가 내가 원하는 수(k) 이하가 될 때까지 분할하며, 리프노드에는 해당 격자에 포함된 공간 데이터의 정보들을 갖도록 구성합니다.

모든 격자를 균일한 사이즈로 해야했던 지오해시와는 달리, 쿼드트리는 맘만 먹으면 원하는 영역에 대해 세밀하게 격자를 분할하는 것이 쉽습니다. 또한 트리 구성 시 특정 숫자(k)를 기준으로 만들어 나가는 점을 활용해 "현재 내 위치에서 가까운 공간 데이터 x개 찾기"를 쉽게 할 수 있게 됩니다. 하지만 트리 구조인 만큼 공간 데이터 추가 / 삭제로 인한 인덱스 변경이 좀 더 까다롭고, 서버 시작 시 트리를 구축해서 메모리에 둬야 하기 때문에 서버 시작 시간이 길어질 수 있음을 유의해야 합니다.
설계
위에서 살펴본 기술 중, 지오해시를 사용할 때의 일반적인 설계 방법에 대해 살펴보겠습니다. 특정 위치와 반경을 기준으로 주변 시설을 조회하는 기능과 특정 시설의 상세 정보를 제공하는 서비스로, 다음과 같은 기능적 요구사항이 있다고 가정합니다.
- 사용자의 경도와 위도, 반경에 매치되는 시설 목록을 반환해야 함
- 시설 정보가 추가/갱신/삭제될 수 있으나 실시간으로 반영될 필요는 없음
- 시설의 상세 정보를 조회할 수 있어야 함
그리고 주변 시설을 빠르게 검색 가능해야 하고 트래픽이 급증해도 감당할 수 있어야 한다는 비기능적 요구사항이 있다고 하겠습니다. 또한 1초에 5,000번 정도의 검색이 발생하는 읽기 연산 위주의 시스템으로 가정하며, 다음과 같은 API들이 있다고 하겠습니다.
| Method | API | 설명 |
| GET | /v1/search/nearby | 인자로 위도, 경도, 반경을 받은 뒤 검색 기준에 맞는 사업장 목록 반환 |
| GET | /v1/businesses/:id | 특정 사업장의 상세 정보 반환 |
| POST | /v1/businesses | 신규 사업장 추가 |
| PUT | /v1/businesses/:id | 사업장 상세 정보 갱신 |
| DELETE | /v1/businesses/:id | 특정 사업장 정보 삭제 |
1) 서버 및 로드밸런서 설계
해당 시스템을 위치 기반으로 시설들을 검색하는 서비스(LBS)와 시설 서비스(시설 상세조회, 등록 등을 담당)로 구분할 수 있습니다. 사용자가 보내는 요청들을 각각의 알맞는 서비스로 전달하기 위해 로드밸런서에서 URL 경로를 분석해 다음과 같이 설정해줄 수 있습니다.

또한 LBS와 시설 서비스는 이전 요청의 상태나 데이터를 유지하지 않는 무상태 서비스이므로 확장성이 좋습니다. 따라서 트래픽이 몰릴 때는 서버를 추가하여 대응하고, 트래픽이 줄어들면 서버를 삭제하도록 유연하게 구성할 수 있습니다. 또한, 클라우드에 시스템을 띄운다면 여러 지역 또는 여러 가용 영역에 둠으로써 고가용성도 확보할 수 있겠습니다. 여러 지역에 둘 경우 DNS 라우팅을 통해 사용자와 가까운 서버에서 트래픽을 처리하도록 하여 응답 시간을 줄이는 효과 등을 기대할 수 있으며, 한 지역 안에서도 여러 가용 영역을 활용한 부하 분산을 기대할 수 있습니다.
2) 데이터베이스 설계
이 시스템은 앞서 가정한대로 읽기 연산이 많이 발생하는 특징이 있습니다. 따라서 데이터베이스를 master-slave 형태로 구성하여 master가 쓰기 요청을, slave가 읽기 연산을 처리하도록 구성하여 부하를 어느 정도 분산시키도록 구성할 수 있습니다.
그리고 테이블을 위치 정보 관련 연산의 효율을 위해 시설의 상세 정보를 담는 테이블(business 테이블)과 공간 인덱스 테이블(지오해시값과 시설id만 가지는)로 분리할 수 있습니다.
먼저 business 테이블의 경우 시설 데이터가 방대하다면 한 서버에 담기지 못할 수 있으므로, 샤딩을 통해 수평적으로 분리 확장시킬 수 있겠습니다.
공간 인덱스 테이블은 서버 한 대에 충분히 수용 가능할 것으로 예상되나, 읽기 연산이 많은 경우 가용한 리소스(CPU, 네트워크 대역폭 등)의 한계가 있으므로 부하 분산이 필요할 수 있는데요. 보통 부하 분산이 필요한 경우 Replica를 늘리는 것과 샤딩을 고려할 수 있으나, 지오해시는 격자별 공간 데이터 분포가 고르지 않아 샤딩이 까다롭고 공간 인덱스 테이블은 서버 한 대에 충분히 수용 가능할 것으로 예상되므로 Replica를 활용하는 것이 더 나은 방안이 될 수 있습니다.
3) 캐시 설계
다중 서버 환경이므로 로컬 캐시보다는 캐시 서버를 구축하는 형태의 글로벌 캐시를 사용하는 것이 좋습니다. 가장 직관적으로 떠올릴 수 있는 캐시 키는 사용자의 위도 경도입니다. 그러나 위도 경도는 사용자가 조금만 움직여도 달라지기 때문에, 캐시 키로 설정할 경우 캐시 히트가 발생하길 기대하기가 매우 어렵습니다. 이때 아까 배웠던 지오해시나 쿼드트리 등을 사용한다면 같은 격자 내의 시설들이 같은 격자 식별자 값을 갖도록 만들 수 있으므로 이 문제를 효과적으로 해결 가능합니다.
구체적으로 다음 데이터들을 캐시에 보관하도록 할 수 있습니다.
| 키 | 값 |
| 지오해시 | 해당 격자 내의 시설 id 목록 |
| 시설 id | 시설 상세 정보 객체 |
특정 지오해시에 대응되는 시설 목록을 요청받은 경우, 다음과 같이 설계할 수 있겠습니다.
- 캐시 먼저 조회
- 없으면 DB에서 해당 지오해시에 대응되는 시설 id 목록 가져와서 캐싱
시설 서비스를 통해 시설의 상세 정보를 조회하는 경우도 위 플로우대로 설계할 수 있겠습니다. 새로운 시설을 추가하거나 기존 시설 정보를 편집 또는 삭제하는 경우, DB를 그에 맞춰 갱신하고 캐시에 보관된 항목은 무효화시킬 수 있습니다. 만약 검색 반경으로 가능한 값들이 정해진 경우, 각 반경에 맞춘 적절한 지오해시 레벨들을 계산 가능하므로 해당하는 레벨에 대한 검색 결과들을 미리 캐싱해둘 수도 있겠습니다. 또한 고가용성 보장을 위해 캐시 서버도 클러스터를 구성하는 것을 고려할 수 있으며, 서버들을 여러 지역에 둔 것과 마찬 가지로 캐시 서버 클러스터를 각 지역별로 구성하여 가까운 캐시 서버를 사용하도록 구성할 수 있겠습니다.
4) 최종 설계도
앞서 설명한 것들을 토대로 다음과 같은 아키텍처를 설계할 수 있게 됩니다.
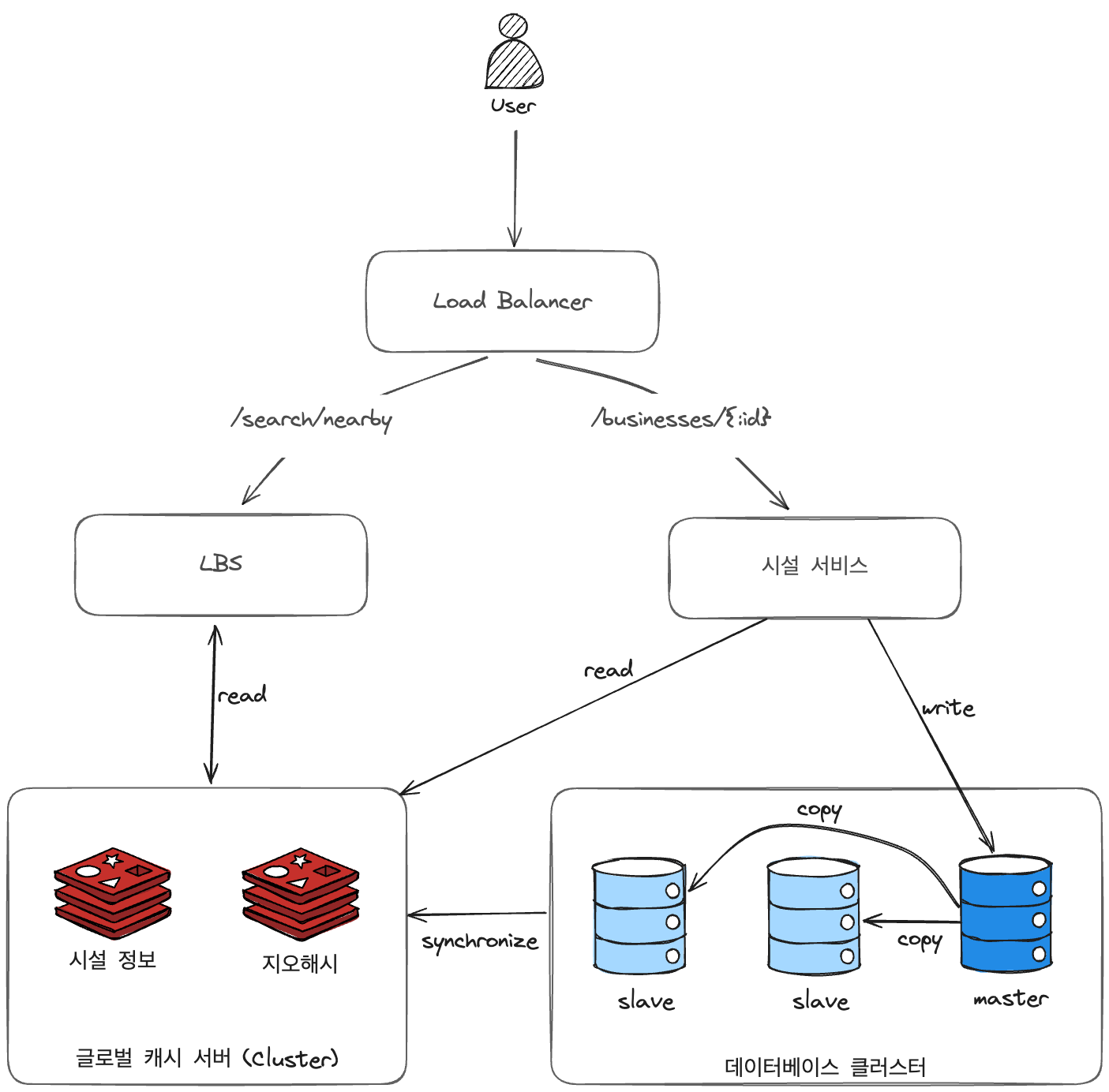
해당 아키텍처에서의 플로우는 다음과 같이 설계할 수 있습니다.
a) 주변 시설들을 검색하는 경우
- 클라이언트는 위치(위도, 경도)와 검색 반경을 로드밸런서로 전송합니다.
- 로드밸런서는 URL을 보고 해당 요청을 LBS로 보냅니다.
- LBS는 요청에 포함된 위치와 반경 정보를 토대로 최적 정밀도를 갖는 지오해시 길이를 계산합니다.
- LBS는 사용자의 위치를 담는 지오해시와 인접한 지오해시들을 계산하여 목록으로 가집니다.
- LBS는 목록에 있는 각 지오해시값에 대해, 글로벌 캐시 서버로부터 해당 지오해시에 매핑된 시설들의 id목록을 가져옵니다. 만약 캐싱된 게 없다면 DB의 공간 인덱스 테이블에서 가져와서 캐싱합니다.
- 각 시설id들에 대해, 글로벌 캐시 서버로부터 해당 id에 매핑된 상세 정보들을 가져옵니다. 만약 캐싱된 게 없다면 DB의 business 테이블에서 가져와서 캐싱합니다.
b) 시설의 상세정보를 조회하는 경우
- 클라이언트는 조회할 시설의 id를 로드밸런서로 전송합니다.
- 로드밸런서는 URL을 보고 해당 요청을 시설 서비스 서버로 보냅니다.
- 시설 서비스 서버는 글로벌 캐시 서버로부터 해당 시설id에 대한 상세 정보를 가져옵니다. 만약 캐싱된 게 없다면 DB의 business테이블에서 가져와서 캐싱합니다.
시설 정보가 추가/갱신/삭제된 경우, 해당 정보가 실시간으로 반영될 필요는 없음을 처음에 가정했으므로 캐시에 보관된 시설 정보의 갱신은 밤 사이에 배치를 수행하는 방식으로 처리할 수 있습니다.