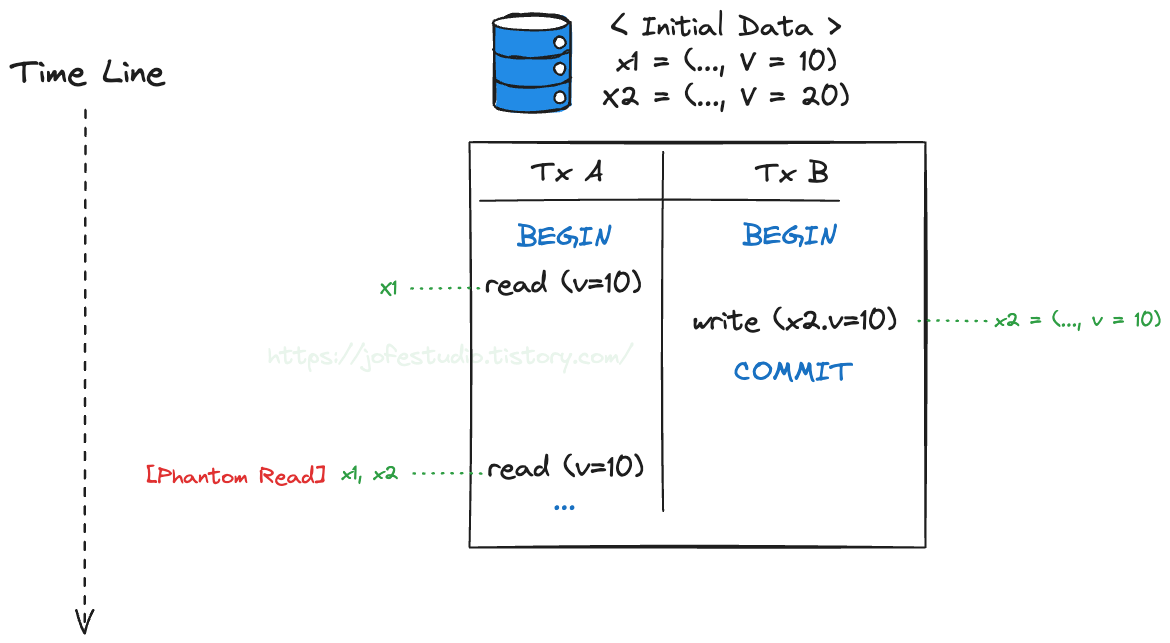
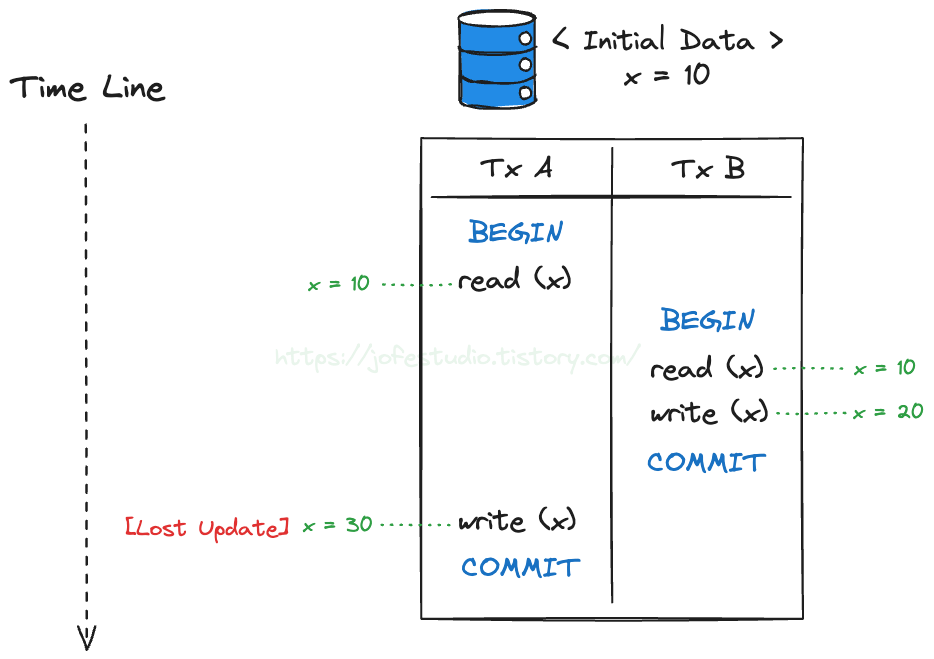
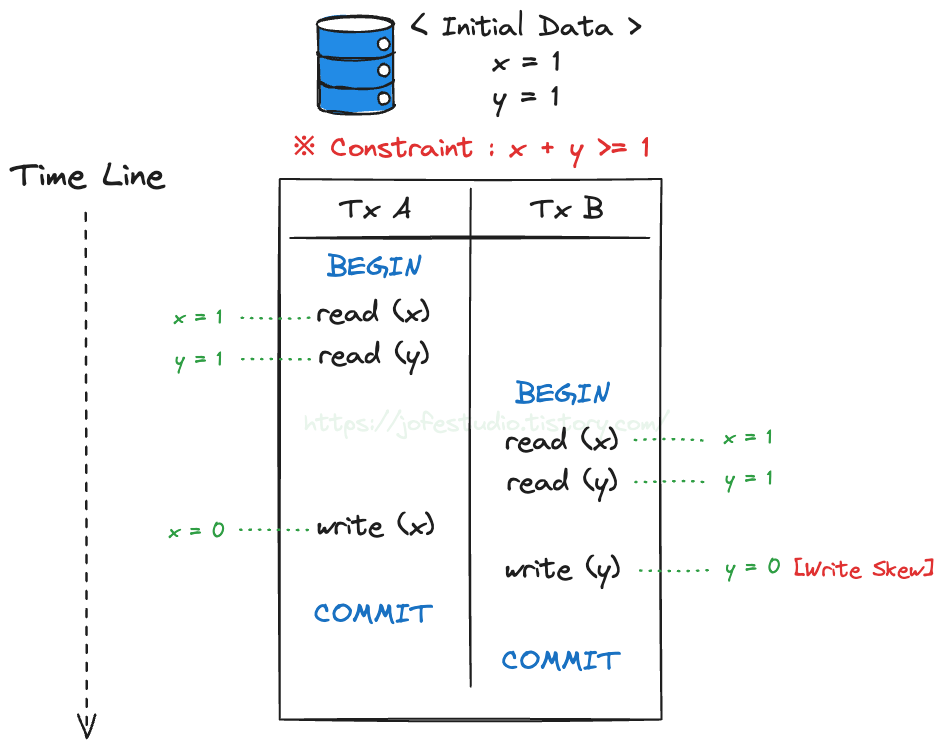
들어가며
작년 말, IfKakao 2024에서 카카오페이에서 지연이체 개발기란 제목의 세미나가 공개됐습니다. Kafka를 활용해 지연이체 서비스를 설계한 과정이 담겨있었는데요. 개인적으로 굉장히 흥미롭게 봤기 때문에, 직접 설계 과정을 따라가보면 왜 카카오페이에서 세미나에 녹여냈던 선택들을 했는지 더 잘 이해할 수 있고 그 과정에서 공부가 많이 되겠다는 생각이 들어, 회사 동기들과 직접 Kafka를 활용해 예약이체 서비스를 사이드 프로젝트 수준에서 설계해봤습니다.
참고로 실제 이체 프로세스가 어떻게 정교하게 흘러가는지는 잘 몰랐기 때문에.. 이체 프로세스는 출금계좌의 돈을 빼고, 타행이체일 경우는 API호출을 가정하여 1초간 Thread.sleep()을 하는 수준으로만 가정하고 설계를 진행했습니다.
본 글은 다음 목차로 진행됩니다.
- 예약이체란?
- 개략적인 설계
- 세부 프로세스 설계
- 속도 높이기
- 소감
- Reference
1. 예약이체란?

이 글에선 은행 점검 시간에 송금 건을 예약하여 은행 점검 시간 이후 자동으로 예약된 송금 건이 실행되도록 하는 것을 말하도록 하겠습니다. 참고로 송금 예약을 눌렀을 때 어떻게 저장하는지는 여기서 다루지 않고, 저장된 예약이체 건을 실행하는 것에 대한 아키텍처와 프로세스만을 다뤘습니다.
2. 개략적인 설계
다음 내용들에 대한 개략적인 설계입니다.
- 데이터 스키마 설계
- API 설계
- 개략적인 아키텍처와 프로세스
1) 데이터 스키마 설계
예약이체 테이블 (scheduled_transfer)
| 필드 | 설명 | 자료형 |
| scheduled_transfer_id (PK) | 예약이체 건 식별자 | bigInt |
| from_account | 출금계좌(source) | varchar(20) |
| to_account | 송금계좌(destination) | varchar(20) |
| to_bank_code | 송금은행코드 | varchar(10) |
| transfer_amount | 송금금액 | decimal(15, 2) |
| transfer_available_dttm | 송금가능일시 | datetime |
| status | 예약이체 건 상태 | tinyInt |
| scheduled_dttm | 예약일시 | datetime |
예약이체 건 상태값으론 0, 1, 2 등이 저장되며 각각 PENDING, COMPLETED, FAILED 등을 의미합니다. 신규 상태값이 추가될 수도 있음을 고려해 enum이 아닌 tinyInt타입을 사용하도록 했습니다. 마지막 수정일시 등의 컬럼도 필요하겠으나 위 표에서는 생략했습니다.
고객 정보, 계좌 정보, 은행 정보에 대한 스키마는 아주 간단한 수준(식별자, 고객명, 은행코드, 은행명 등만 있는 수준)으로만 설계했으므로 따로 작성하진 않겠습니다.
2) API 설계
앞서 말씀드렸듯 예약이체 건을 저장하는 프로세스는 다루지 않았기 때문에, 예약이체 건을 저장하는 API는 설계하지 않았습니다.
POST /v1/scheduled-transfers/:id/execute
예약 이체 건을 실행하는 API입니다. id는 예약이체 건의 식별자이며, API 호출 시 body에 담아 전달하는 인자들은 다음처럼 설계했습니다.
| 필드 | 설명 | 자료형 |
| from_account | 출금계좌(source) | varchar(20) |
| to_account | 송금계좌(destination) | varchar(20) |
| to_bank_code | 송금은행코드 | varchar(10) |
| transfer_amount | 송금금액 | decimal(15, 2) |
3) 개략적인 아키텍처와 프로세스
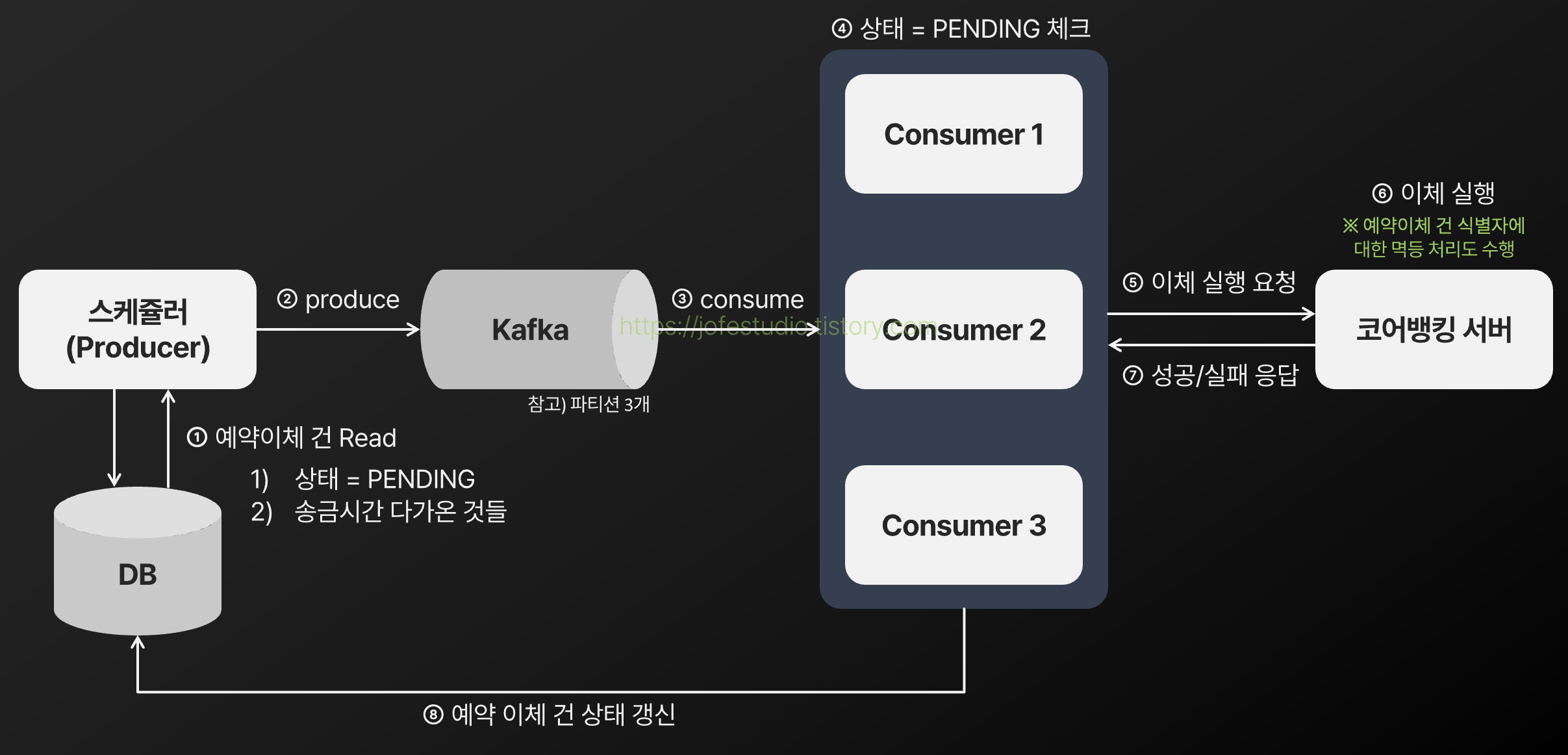
가장 초기에 구상한 아키텍처와 프로세스는 다음과 같습니다.

각 컴포넌트별 역할 및 프로세스
- 스케쥴러(Producer) : scheduled_transfer 테이블에 PENDING상태로 있는 예약이체 건들 중 송금시간이 다가온 것들(송금가능일시 <= 현재시간)을 5분 주기로 조회하여 Kafka로 발행하는 역할을 합니다.
- Kafka : 스케쥴러가 발행한 예약이체 건들에 대한 브로커 역할을 합니다. 예약이체 건들은 scheduled-transfer라는 토픽에 저장되며, 해당 토픽은 파티션 3개로 구성했습니다.
- Consumer : Kafka에 발행된 예약이체 건들을 가져와서 코어뱅킹 서버로 이체 실행 요청을 보내는 역할을 합니다. 각 Consumer들은 Kafka 파티션들과 1 : 1로 대응되도록 3개로 구성했습니다.
- 코어뱅킹 서버 : Consumer로부터 요청받은 예약 이체 건을 실행하는 내부 서버 역할을 합니다.
완료된 예약 이체 건의 상태 갱신은 누가 할까?
초기엔 단순하게 Consumer에서 코어뱅킹 서버로 이체 실행 요청을 보낸 후, 응답값에 따라 Consumer에서 예약 이체 건들의 상태를 갱신하는 프로세스를 구상했습니다. 그러나 다음과 같은 케이스들이 발생할 수 있었습니다.
- 코어뱅킹 서버에서 이체 실행은 완료됐으나 네트워크 오류 등으로 Consumer로 응답을 못 준 경우
- 코어뱅킹 서버로부터 응답은 왔으나 Consumer에서 예약 이체 건의 상태 갱신에 실패하는 경우
- 등등..
예약 이체 테이블(scheduled_transfer)과 계좌 테이블들이 같은 DB에 있었기 때문에, 코어뱅킹 서버에서 이체 실행과 예약 이체 건의 상태 갱신을 하나의 DB 트랜잭션에서 처리하도록 설계하여 위 문제를 해결할 수 있겠다는 생각이 들었습니다. 그러나 실무 상황이라면 예약 이체 테이블과 계좌 테이블이 다른 DB에 있다든가, 코어뱅킹 서버에서 예약 이체 테이블이 있는 DB로 접근할 수 없다든가 하는 제약들이 따를 수 있습니다. 따라서 코어뱅킹 서버에서 예약이체 건 식별자(scheduled_transfer_id)에 대한 멱등 처리를 통해 중복 이체 실행을 막고, 기 실행됐던 예약 이체 건에 대한 실행 요청을 받은 경우 이미 실행된 건임을 알리는 응답을 주도록 한 뒤 Consumer에서 해당 응답에 따라 예약 이체 건들의 상태를 갱신하도록 설계했습니다.
리소스 낭비 방지를 위한 Consumer 단 필터링 프로세스 추가
스케쥴러가 예약 이체 건들을 kafka로 5분 주기로 발행해주므로, 이전에 발행한 건이 아직 실행되지 않았다면 스케쥴러가 동일한 예약 이체 건을 Kafka로 여러 번 발행할 수 있습니다. 물론 코어뱅킹 서버에서 예약 이체 건 식별자(scheduled_transfer_id)에 대한 멱등 처리를 해줘서 실제로 이체가 중복으로 발생하지 않도록 처리했으나, 처리될 필요가 없는 예약 이체 건도 코어 뱅킹 서버로 전달되어 리소스를 낭비하게 되는 상황은 발생 가능하다고 생각했습니다. 만약 코어뱅킹 서버에서 멱등 처리가 제대로 기능하지 않게 된다면 이는 리소스 낭비에서 끝나지 않고 중복 이체 발생으로도 이어질 수 있습니다. 따라서 Consumer에서 Kafka에서 가져온 예약 이체 건들의 PENDING 여부를 확인 후 필터링된 건들만 이체 실행 요청을 보내도록 했습니다.
정리하면 다음과 같은 프로세스를 설계하게 됐습니다.
3. 세부 프로세스 설계
1) Consumer 단 필터링을 거쳐도 리소스 낭비가 가능했다
스케쥴러가 Kafka로 동일한 예약 이체 건을 중복으로 쌓아두는 상황은 여전히 가능한 상황이었습니다. Consumer에서 상태가 PENDING인지 체크하는 과정을 추가하여 처리할 필요가 없는 예약 이체 건에 대한 리소스 낭비를 막고자 했지만, 만약 동일한 예약이체 건들이 서로 다른 Consumer에서 동시에 실행된다면 다음과 같이 여전히 리소스 낭비가 발생할 수 있었습니다.
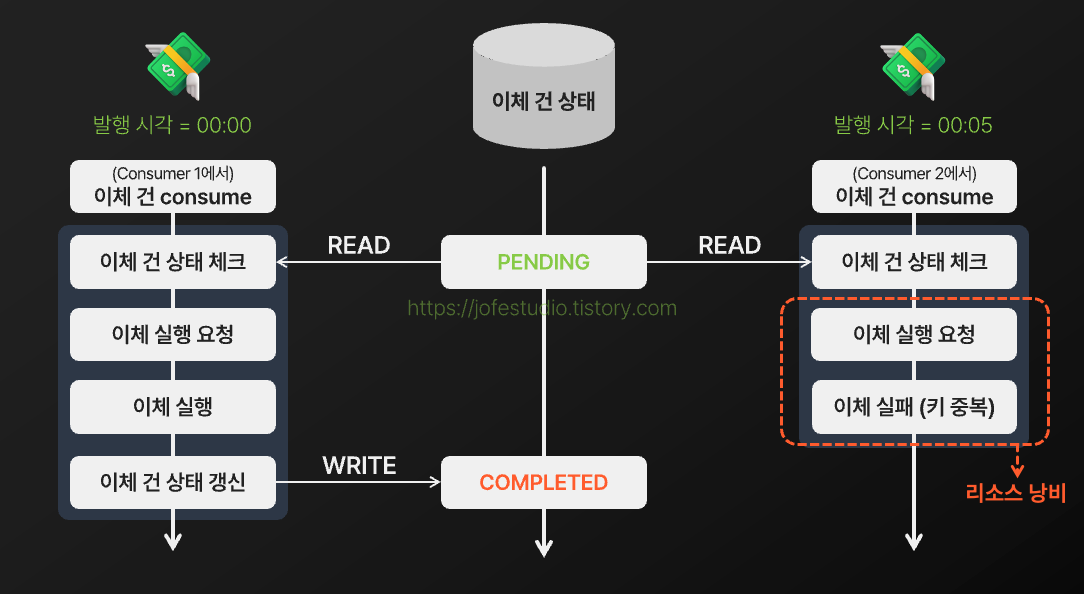
위 그림에선 코어뱅킹 서버에서의 멱등 처리로 인해 한 쪽에서는 이체가 실패하여 리소스 낭비에서 끝나게 됐지만, 앞서 설명했듯 만약 코어뱅킹 서버에서 멱등 처리가 제대로 기능하지 않게 된다면 리소스 낭비에서 끝나지 않고 중복 이체 발생으로 이어질 수 있습니다. 이 문제를 해결하려면 동일한 예약 이체 건 여러 개가 동시에 실행되는 것을 제어할 수 있어야 한다고 생각했습니다.
구체적인 방법으로는 다음 방법들을 구상했습니다.
방법 1. 하나의 예약 이체 건을 정확히 한 번만 Kafka로 발행하자
애당초 동일한 예약 이체 건이 Kafka에 여러 번 중복으로 발행되지 않는다면 동일한 예약 이체 건들이 동시에 실행되는 상황 자체가 벌어지지 않는다는 점을 활용한 해결 방법입니다. 대표적인 구현 방법으로는 스케쥴러가 PENDING 상태인 예약 이체 건들을 조회해서 Kafka에 발행해줄 때, 해당 예약 이체 건들의 상태를 PUBLISHED로 바꿔주는 방법이 있습니다.
이 방법은
- 스케쥴러가 DB에 해당 예약 이체 건의 상태를 PUBLISHED로 갱신하는 작업
- 스케쥴러가 Kafka에 해당 예약 이체 건을 발행하는 작업
으로 구분할 수 있으며, 하나의 예약 이체 건을 정확히 한 번만 Kafka로 발행한다는 제약을 지키려면 두 작업의 원자성이 보장되어야 합니다. DB 트랜잭션을 통해 예약 이체 건의 상태를 PUBLISHED로 갱신한 다음 Kafka로 예약 이체 건을 발행하는 작업의 성공/실패 여부에 따라 트랜잭션을 커밋 or 롤백하면 된다고 생각했으나, 다음과 같은 상황도 충분히 발생할 수 있었습니다.
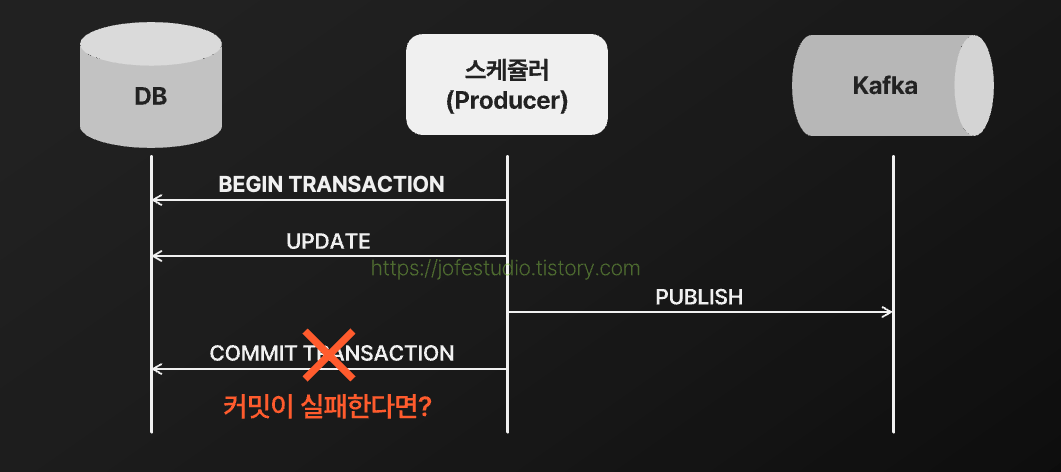
즉 하나의 DB 트랜잭션만으로는 두 작업의 원자성을 완벽하게 보장할 수 없었습니다. 2 Phase Commit이나 트랜잭셔널 아웃박스 등을 활용하는 방법이 있겠지만, 결국 "어떤 상황이 닥쳐도 하나의 예약 이체 건을 정확히 한 번만 발행해준다"라는 것을 구현하기는 굉장히 어렵겠다는 생각이 들었습니다. 또한 어찌저찌 해서 정확히 한 번 발행에 성공한다고 해도 다음과 같은 상황들을 고려해야 했습니다.
- 정확히 한 번 발행된 예약 이체 건을 실행하다가 중간에 실패하면 재시도는 어떻게 할 것인가? 다시 예약 이체 건의 상태를 PENDING으로 바꾸게 할 것인가?
- 정확히 한 번 발행된 예약 이체 건을 Consumer에서 중복으로 consume하게 되는 상황이 오면 어떻게 할 것인가? 정확히 한 번 발행됐어도, 해당 예약 이체 건을 실행하는 것도 정확히 한 번만 실행되는 것을 어떻게 처리해줄 것인가?
- 등등..
즉 정확히 한 번 발행에 성공해도 논리적인 관점 등에서 데이터의 일관성이 깨질 수 있는 여러 샛길들이 많다고 생각했습니다. 따라서 하나의 예약 이체 건을 정확히 한 번만 발행한다는 제약 조건을 지키기 위해 그런 샛길들을 모두 고려하며 구현하는 것보다는, 같은 이체 건 여러 개가 동시에 실행되는 것을 제어할 수 있는 다른 방법을 적용하는 것이 더 낫다고 판단했습니다.
방법 2. 계좌 락을 걸어보자
두 번째로 구상한 방법은 동시성 제어에 보편적으로 많이 활용되는 "락"을 활용하는 것이었습니다. Consumer에서 예약 이체 건의 상태를 체크하는 부분부터 Consumer에서 예약 이체 건의 상태를 갱신하는 부분에 락을 걸어 같은 이체 건이 동시에 실행하는 것을 제어하자는 아이디어였습니다. 예약 이체 건의 상태 체크와 상태 갱신 모두 Consumer에서 수행되고 있기 때문에, Consumer에서 예약 이체 테이블(scheduled-transfer)에 SELECT FOR UPDATE를 통해 배타 락을 거는 방법을 우선적으로 고려했습니다. 그러나 이 방법은 락을 걸고 코어뱅킹 서버로 요청한 이체 실행의 응답이 오기까지 DB 커넥션이 늘어질 여지가 있었기 때문에, 다른 형태로 락을 걸어보자고 생각했습니다. 그 결과 예약 이체 건에 계좌 락을 거는 형태를 고려하게 됐습니다.

계좌 락을 얻는 방법으론 계좌 락을 위한 테이블을 별도로 만들어 활용하는 방법과 분산 락을 활용하는 방법이 있었습니다. 전자의 경우 예약 이체 테이블(scheduled-transfer)에 배타 락을 거는 방법과 동일하게 락을 걸고 코어뱅킹 서버로 요청한 이체 실행의 응답이 오기까지 DB 커넥션이 늘어질 여지가 있다고 판단했습니다. 또한 출금계좌에 락을 거는 것은 결국 전체 시스템에서 해당 계좌로 접근하는 스레드를 하나로 제한하기 위함이기도 한데, 실무에서는 계좌 정보를 하나의 DB에서 관리하지 않고 여러 시스템 또는 모듈들이 독립적인 DB를 사용 중일 수 있고 하나의 서버가 여러 서버로 분리될 수도 있기 때문에 테이블 기반의 계좌 락은 전체 시스템에서 해당 계좌로 접근하는 스레드를 하나로 제한하기엔 확장성이 낮다는 생각이 들었습니다. 따라서 분산 락을 활용해 계좌 락을 구현하는 것으로 결정했습니다.
분산 락을 통해 같은 이체 건들이 동시에 실행되는 것을 제어하게 되는 과정을 나타내면 다음과 같게 됩니다.
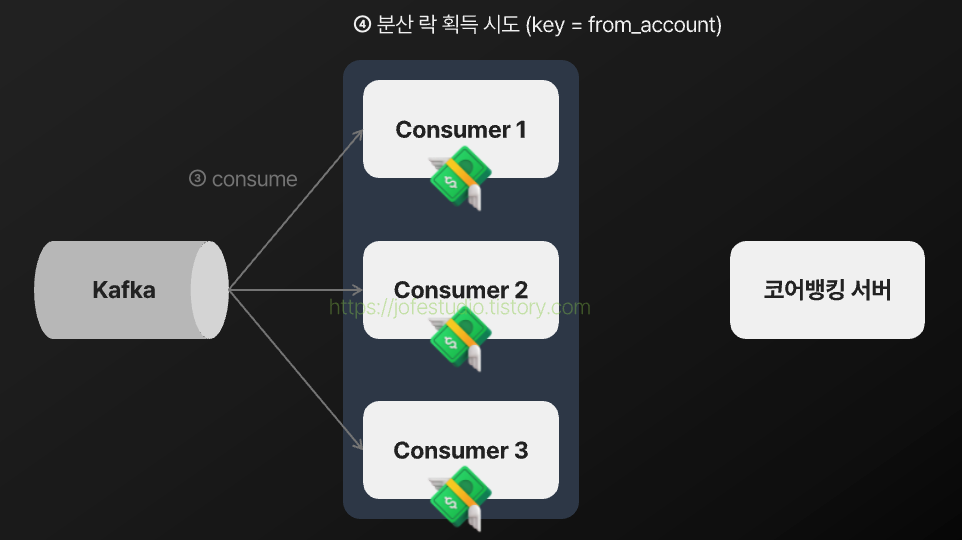
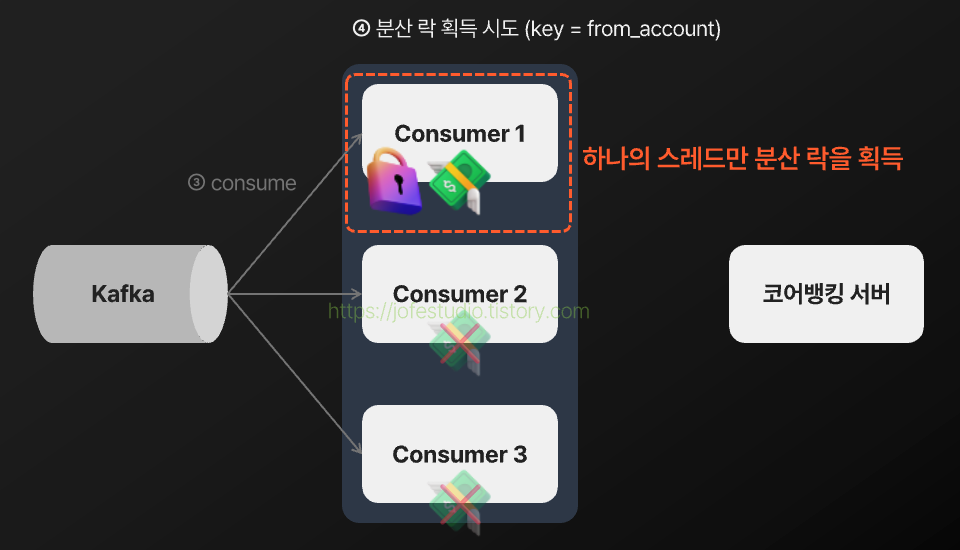
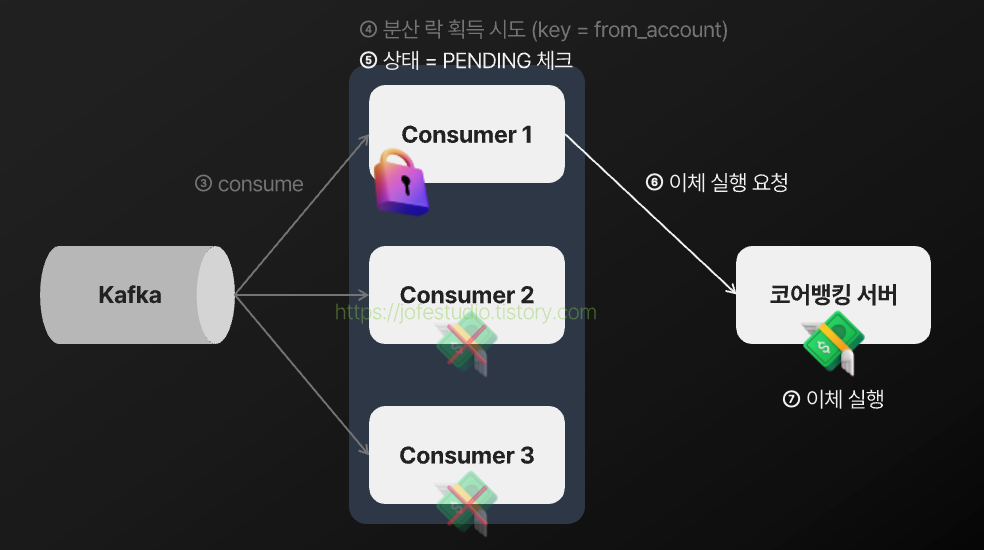
2) 예약 이체 건이 송금가능일시가 지나도 장기간동안 실행되지 않는 이슈가 발생
하지만 이렇게까지 해놓고 테스트를 돌려보니, 특정 예약 이체 건들이 송금가능일시가 지나도 1 ~ 2시간 이상 실행되지 않는 이슈가 발생했습니다.
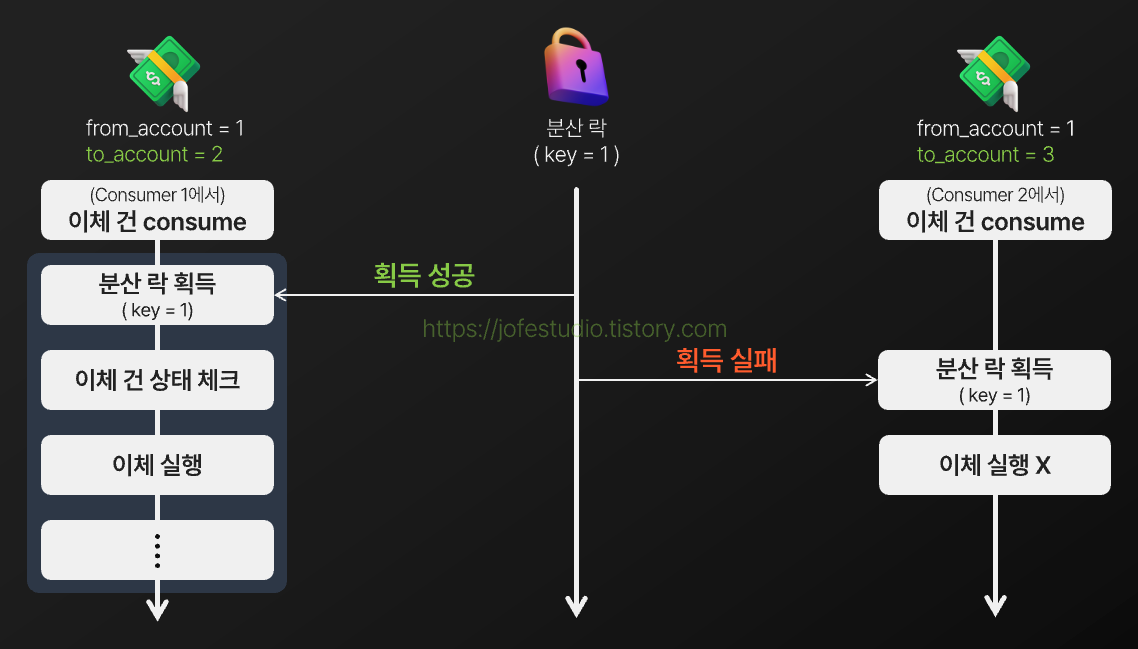
원인은 위 흐름도와 같이 출금계좌는 같지만 엄연히 서로 다른 이체 건들이 동시에 실행될 때 한 쪽에선 분산 락 획득을 실패하여 이체가 실행되지 않던 상황이 생길 수 있었다는 것이었습니다. 락을 획득할 때까지 대기시키기는 방법 등이 떠올랐으나 그렇게 되면 현재 구조에선 뒤에 쌓이는 예약 이체 건들이 밀릴 수 있었고, 대기시키는 방법도 이체 실행이 지연되는 건 마찬가지이니 근본적인 해결법은 아니라고 생각했습니다. 따라서 락 경합 자체를 줄일 수 있는 방법들을 고려하게 됐습니다.
방법 1. 분산 락 키를 바꾸자
현재는 출금계좌를 키로 해서 분산 락을 잡고 있었는데, 다른 값을 키로 잡으면 되지 않을까라는 아이디어였습니다.

출금계좌는 각 예약 이체 건들의 고유값이 아니기 때문에 출금계좌를 분산 락 키로 잡으면 서로 다른 이체 건들끼리도 락 경합이 발생 가능합니다. 반면 예약 이체 건 식별자(scheduled_transfer_id)는 각 예약 이체 건들의 고유값이므로 여기에 분산 락 키를 잡아주게 되면 같은 예약 이체 건들이 동시에 실행되는 상황에 한해서만 락 경합이 발생됩니다. 따라서 락 경합을 줄이려는 목적을 달성할 수 있다는 생각이 들었습니다.
다만 앞서 말했듯 출금계좌에 락을 거는 것은 시스템 전체에서 해당 계좌로 접근하는 스레드를 하나로 제한하는 효과를 줍니다. 예약 이체 건 식별자에 대해 락을 걸면 락 경합은 분명 줄어들겠지만 해당 계좌로 접근하는 스레드가 여러 개가 될 수 있어 예상치 못한 동시성 관련 문제를 안겨줄 수 있습니다. 이체는 결국 오류없이 수행되는 것이 가장 중요하다고 생각했기 때문에 분산 락 키는 출금계좌를 그대로 쓰게 하여 해당 계좌로 접근하는 스레드를 하나로 제한시켜 안전성을 높이고, 대신 락 경합을 줄일 수 있는 다른 방법을 고려해보기로 했습니다.
방법 2. 예약 이체 건들을 출금계좌별로 파티셔닝하자
두 번째 방법은 예약 이체 건들을 출금계좌별로 같은 파티션에 가게끔 설정하는 아이디어입니다. 같은 출금계좌를 가진 서로 다른 예약 이체 건들이 동시에 실행되는 이유는 이들이 서로 다른 Consumer에서 실행될 수 있기 때문인데요. 현재 구조(3개 파티션, 3개 Consumer)에서는 각 Consumer들이 서로 다른 파티션을 담당하고 있기 때문(Kafka는 기본적으로 파티션 하나에 같은 Consumer 그룹 내에선 단일 Consumer 스레드가 할당됨)에 같은 출금계좌를 갖는 예약 이체 건들을 같은 파티션으로 발행하게 되면 하나의 Consumer에서만 예약 이체 건들을 처리하게 됩니다. 또한 현재 하나의 Consumer 스레드에서는 담당하는 파티션에 발행된 예약 이체 건들을 순서대로 처리 중이므로 이 경우 같은 출금계좌를 갖는 예약 이체 건들이 동시에 실행되는 것이 방지되는 효과를 가져올 수 있습니다.
Kafka Producer(스케쥴러)에서 메시지를 발행할 때 어떤 파티션으로 발행할지는 Partitioner라는 컴포넌트가 담당하는데요. kafka-clients 3.6.2 기준으로, 메시지 발행 시 키를 지정하지 않는다면 다음 그림과 같이 Sticky partitioning전략을 통해 메시지를 파티션으로 발행하게 됩니다.
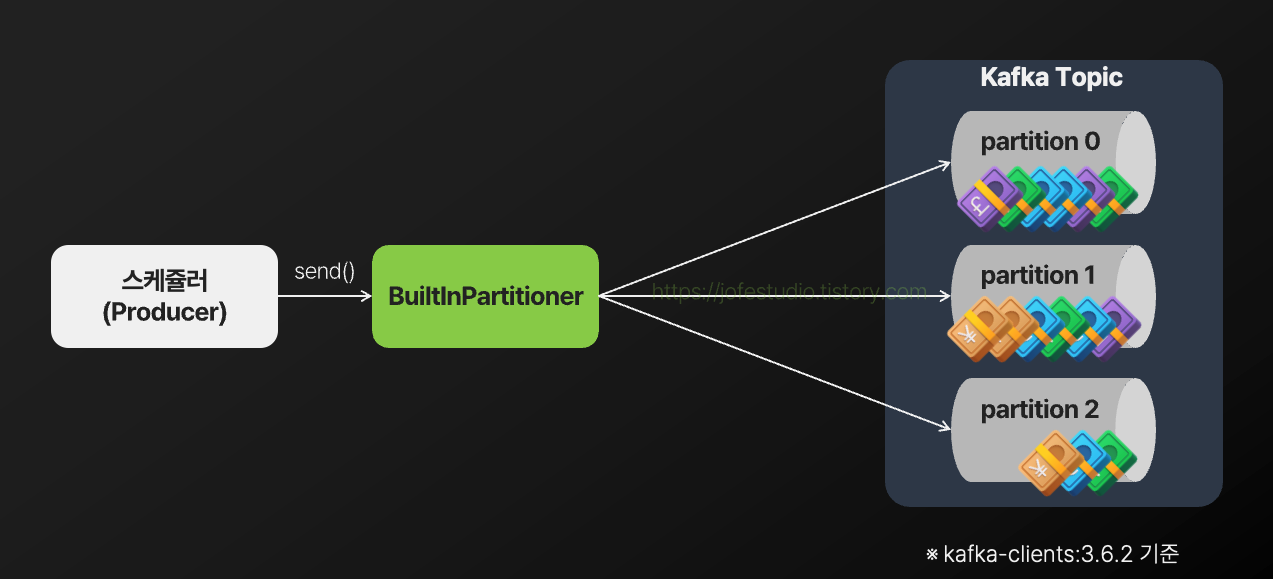
Sticky partitioning은 하나의 파티션을 유지하며 메시지를 발행하다가 특정 조건(배치 크기 초과, 시간 초과 등)이 충족되면 새로운 파티션을 선택하여 메시지를 발행하는 전략으로, 같은 파티션에 연속해서 메시지를 발행하므로 배치 최적화가 가능해지고 불필요한 파티션 변경을 줄여 네트워크 처리 비용 등을 감소할 수 있다는 장점이 있습니다. 다만 현재 설계 중인 예약 이체 시스템과 같이 동시에 실행되면 안 좋은 메시지들(ex: 같은 출금계좌를 가진 서로 다른 예약 이체 건들)이 각기 다른 파티션에 분배되어 동시에 실행되는 문제를 가져다 줄 수 있습니다.
반면 Kafka Producer(스케쥴러)에서 메시지를 발행할 때 키를 지정하게 된다면, Partitioner는 다음과 같이 키를 기반으로 파티션을 지정하여 메시지를 발행하게 됩니다.
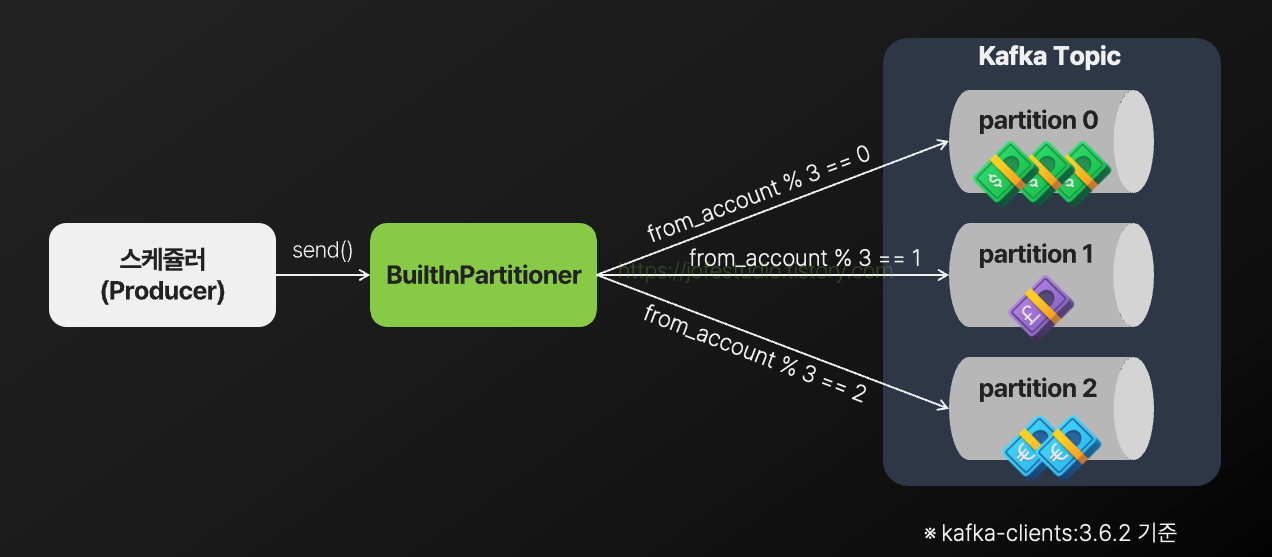
이 경우 같은 출금계좌를 갖는 예약 이체건들은 같은 파티션에 할당되므로, 이들이 동시에 실행되는 상황이 방지되게 됩니다.
이렇게 해두고 보니.. 스케쥴러에서 동일한 예약 이체 건을 발행해도 이들은 동일한 파티션으로 할당되고(물론 리밸런싱 등이 발생하면 다른 파티션에 발행될 순 있음), 앞서 말씀드렸듯이 현재 하나의 Consumer 스레드에서는 담당하는 파티션에 발행된 예약 이체 건들을 순서대로 처리 중이므로 동일한 예약 이체 건들이 서로 다른 Consumer에서 동시에 실행되는 상황도 없어지게 됩니다. 즉, 동시성 문제 해결을 위해 분산 락을 사용할 필요가 없어지게 됩니다. 분산 락을 획득하고 해제하는 것도 네트워크 I/O가 수반되는 것이므로 "그러면 이제 분산 락을 굳이 할 필요가 없어졌는데?"라고 생각했으나, 역시나 앞서 말씀드렸듯이 출금계좌에 락을 거는 것은 시스템 전체에서 해당 계좌로 접근하는 스레드를 하나로 제한하는 효과를 줍니다. 예약 이체 시스템이 아닌 다른 시스템에서도 해당 계좌에 접근하는 로직 등이 있을 수 있고, 이들도 분산 락을 통해 계좌 락을 걸어주고 있다면 예약 이체 시스템을 넘어서 시스템 전체에서 해당 계좌로 접근하는 스레드가 하나가 된다는 얘기입니다. 따라서 동시성 문제를 제어할 필요성이 없어지긴 했어도 시스템 전체에서의 안전성을 높이기 위해 여전히 분산 락을 잡아주는 것은 유효하다고 판단하고, 계속해서 분산 락을 사용해도 된다고 생각하게 됐습니다.
4. 속도 높이기
1) Batch Read 설정
현재 설정은 Consumer들이 각자가 담당하는 파티션에 발행된 예약 이체 건들을 하나 하나 가져와서 처리하고 있는데요. 이런 상황에서 처리량을 높이고 싶을 땐 대표적으로 "일괄 처리"를 도입해볼 수 있고 Consumer에서도 Batch read를 설정하여 파티션에 발행된 예약 이체 건들을 일괄로 가져와서 처리할 수 있습니다.
다만 Consumer에서 특정 개수만큼 예약 이체 건들을 모을 때까지 기다렸다가 일괄로 가져가는 형태가 되기 때문에 각 예약 이체 건의 입장에서 보면 실시간성이 떨어질 수 있음을 고려해야 합니다. 예약 이체 시스템의 경우 송금 가능 일시가 되자마자 즉각적인 이체가 발생되어야 하는 서비스는 아니라고 판단하고 Batch Read를 도입해도 된다고 판단했습니다.
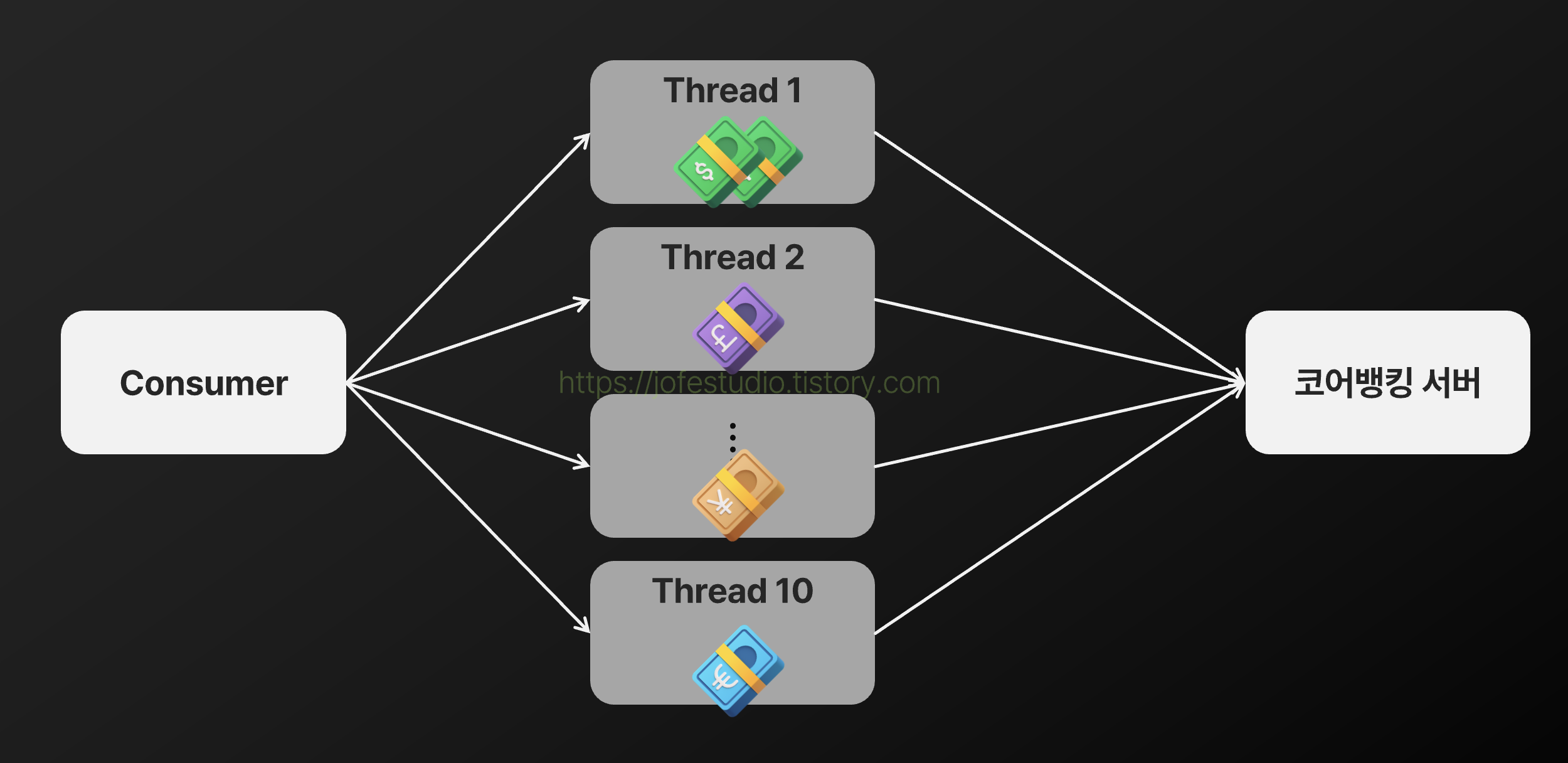
2) 병렬 처리 및 출금계좌별 스레드 지정
Batch Read로 예약 이체 여러 건을 한 번에 가져와도 기본적으로는 하나의 Consumer 스레드가 이들을 처리합니다. 따라서 처리량을 높이기 위해 복수의 스레드로 이들을 병렬 처리하는 방식을 도입할 수 있습니다.
다만 이 경우 같은 출금계좌를 가진 예약 이체 건들이 서로 다른 스레드에서 동시에 실행될 수 있고 이는 잦은 락 경합으로 이어질 수 있습니다. 이전에 출금계좌를 기준으로 특정 파티션에 발행되도록 설정했듯이, Consumer에서 출금계좌별로 처리할 스레드를 따로 지정주어 이 문제를 해결할 수 있습니다.
5. 소감
저랑 동기들이 설계했던 부분은 여기까지입니다. 막상 돌이켜보니 사실상 카카오페이 세미나에서 발표된 내용과 큰 차이가 없긴 합니다만.. 그래도 특정 문제(카카오페이에서 맞닥뜨린)가 생겼을 때 "이런 방법도 있었을 텐데 왜 이건 쓰지 않았을까?"라는 고민들이 드는 지점이 많았는데 직접 설계를 해보니 "아 이래서 그랬구나"라고 더 이해가 잘 되는 부분들이 많았던 것 같습니다. 예를 들면 "예약 이체 건들을 계좌별로 파티셔닝되게 했다면 분산 락이 필요없어진 것 같은데 왜 안 뺐을까? -> 아 안전성을 위해서였구나!" 등등.. 뭔가 다른 사람들이 설계하는 과정을 따라가보는 것은 처음이었는데 그 안에서 배운 것들이 굉장히 많네요. 또한 스스로 아직 많이 부족함을 느끼게 된 것 같기도 합니다.
준비하는 과정에서도 여러 레퍼런스(개인이 올린 블로그 글들은 다 비슷한 감들이 많아.. 테크블로그에서 발행한 컨텐츠들을 최대한 참고하려고 했습니다)들을 봤습니다. 신뢰성 보장을 위해 여러 고민 끝에 기술을 도입하고, 그 기술의 도입으로 인한 리스크들도 기술적인 고민들을 가미하며 해결하는 과정들이 상당히 흥미로웠습니다. 저도 그런 엔지니어가.. 그런 전문성을 가진 사람이 되고 싶다는 생각이 드네요. 더욱,, 정진해야겠습니다.
6. Reference
1. 지연이체 서비스 개발기 (카카오페이)
https://youtu.be/LECTNX8WDHo?si=8cn67Fbr4CbDtkaA
2. 분산 시스템에서 메시지 안전하게 처리하기 (강남언니)
https://blog.gangnamunni.com/post/transactional-outbox/
3. 풀필먼트 입고 서비스에서 분산락을 사용하는 방법 (컬리)
https://helloworld.kurly.com/blog/distributed-redisson-lock/
4. Kafka 메시지 중복 및 유실 케이스별 해결 방법 (올리브영)
https://oliveyoung.tech/2024-10-16/oliveyoung-scm-oms-kafka/
5. SLASH 22 - 애플 한 주가 고객에게 전달 되기까지 (토스증권)
https://youtu.be/UOWy6zdsD-c?si=iTtbPbEDpFaWdPt8
'PROJECT > 개발일지' 카테고리의 다른 글
| [회고] 출근길에 금융 포스트들을 보내주는 서비스 제작기 (4) | 2024.06.06 |
|---|---|
| private subnet에 spring boot, public subnet에 nginx 띄우고 연동하기 (0) | 2023.09.05 |
| Redis활용해 Refresh Token 관리하기 (spring boot, elastiCache) (0) | 2023.09.02 |
| 애플로그인 만들기 - id token(itentity token) 검증하기(java) (0) | 2023.08.24 |
| Oauth2 & JWT를 활용한 로그인&회원가입을 개발하며 마주하고 고민한 것들 (0) | 2023.08.12 |