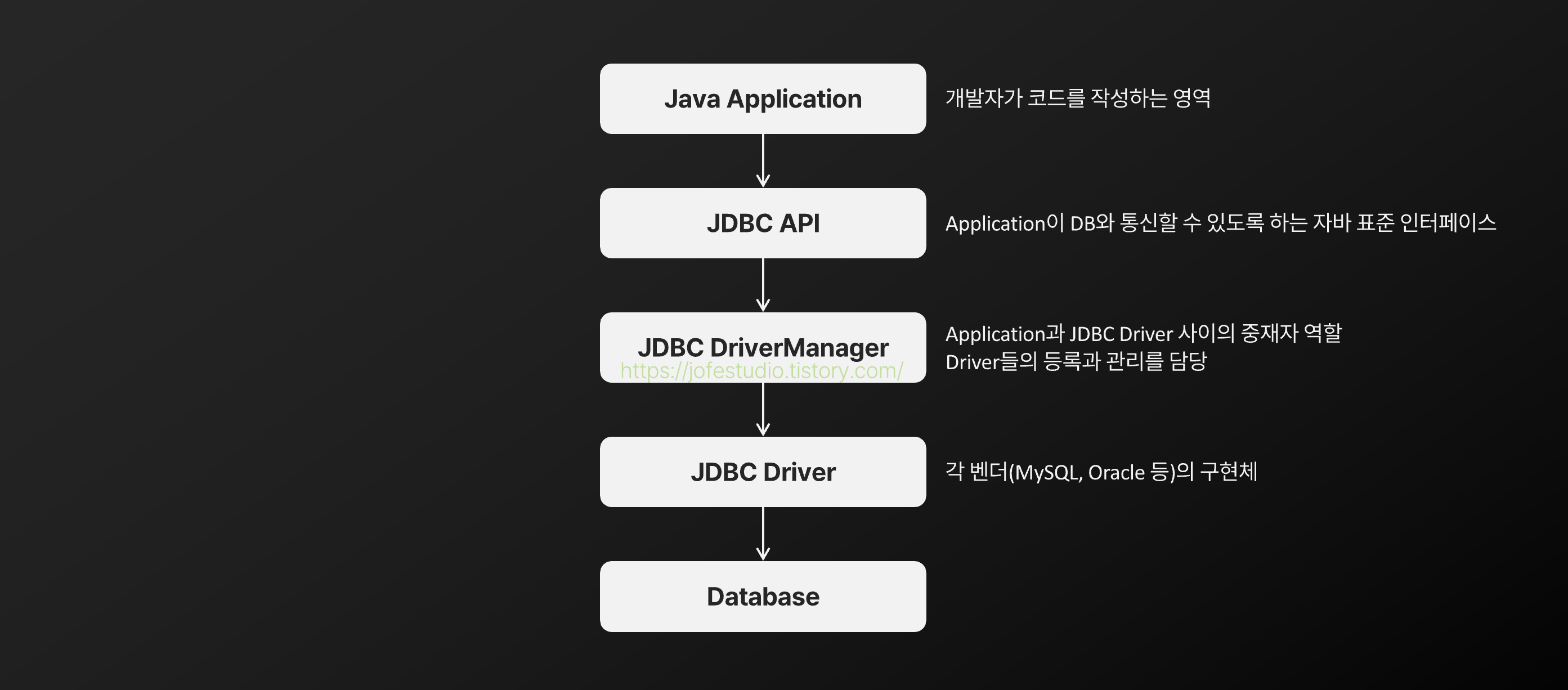
이전 글들에서, JDBC 기반으로 직접 DB를 다루는 방법들을 살펴봤었습니다.
[JDBC] (1편) MyBatis, JPA 없이 JDBC로만 DB를 다루는 세상이었다면
[JDBC] (2편) JDBC 기반으로 직접 트랜잭션을 처리해보고, JDBC 스펙에서의 커넥션풀 알아보기
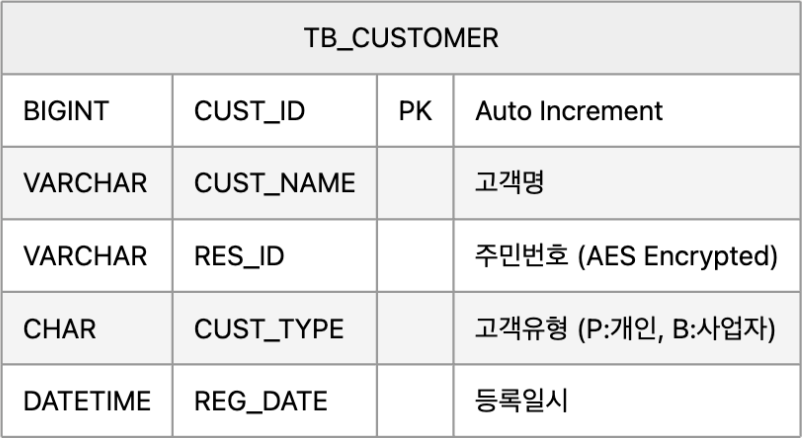
JDBC만으로 DB에서 데이터들을 가져와서 다루는 예시 코드를 다시 살펴보면 다음과 같습니다.
public List<Customer> getCustomers() {
List<Customer> customers = new ArrayList<>();
String selectSql = "SELECT CUST_ID, CUST_NAME, RES_ID, CUST_TYPE FROM TB_CUSTOMER LIMIT ?";
try (Connection conn = JdbcSample.getConnectionByDriverManager();
PreparedStatement pstmt = conn.prepareStatement(selectSql)) {
pstmt.setInt(1, 10);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
Long custId = rs.getLong("CUST_ID");
String custName = rs.getString("CUST_NAME");
String resId = rs.getString("RES_ID");
String custType = rs.getString("CUST_TYPE");
customers.add(new Customer(custId, custName, resId, custType));
}
}
} catch (SQLException e) {
System.out.println("Database error: " + e.getMessage());
}
return customers;
}
보시다시피 이렇게 JDBC만으로 DB를 접근하게 되면,
- SQL 문자열을 작성하는 코드
- Connection 얻어오고, PreparedStatement 생성하고, 파라미터를 설정하는 코드
- ResultSet을 객체(Customer)로 매핑시키는 코드
를 매번 반복해서 작성해야 합니다. Connection, Statement, ResultSet 등을 close하는 것도 계속 신경써줘야 하기도 하구요. 이런 코드에서 중요한 것은 결국 SQL인데, 매번 부수적인 작업들도 직접 반복(보일러플레이트라고도 합니다)해서 해주는건 힘들 수밖에 없습니다. 또한 SQL문과 자바 코드가 강결합되어 있어 유지보수성이 안 좋아지는 문제도 생기게 됐습니다. 자연스럽게 SQL은 개발자가 작성하도록 냅두되 나머지 작업들을 자동화하여 보일러플레이트를 제거하자는 니즈가 생기게 됐고, SQL문을 자바 코드로부터 분리하여 보관하자는 니즈도 생기게 됐습니다.
이런 흐름 속에서 나온 기술이 SQL Mapper입니다. 이번 글에서는 SQL Mapper의 대표 주자인 MyBatis의 동작 원리를 살펴보며, 어떻게 이 문제들을 해결했는지 알아본 것을 공유하고자 합니다.
목차는 다음과 같습니다.
- Mybatis란
- Mybatis가 실행할 SQL들을 찾는 방법
- Mybatis가 SQL을 실행하는 방법 (1) - 메서드 호출이 PreparedStatement가 되기까지
- Mybatis가 SQL을 실행하는 방법 (2) - MyBatis는 파라미터를 어떻게 자동으로 바인딩하는가
- Mybatis가 SQL을 실행하는 방법 (3) - ResultSet이 객체가 되기까지
- 전체 흐름 정리
- Mybatis가 포기한 것
1. Mybatis란
Mybatis는 앞서 설명했듯 SQL mapper 기술의 일종으로, JDBC로 처리하던 상당 부분을 대신 해주는 프레임워크입니다. 핵심 컨셉은 다음과 같이 이해해볼 수 있습니다.
SQL문을 자바 코드에서 분리 보관한다.
SQL문이 문자열로 자바 코드에서 함께 관리가 된다면, 관련 코드가 지저분해지고 DBA와의 협업도 어려워진다는(ex: 개발자와 DBA가 동일한 파일을 수정하게 되는 상황 등) 문제가 생길 수 있습니다. Mybatis는 SQL문을 자바 코드에서 분리해서 다음과 같이 xml파일에 보관하도록 합니다.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example.TestMapper" >
<select id="getCustomers" resultType="org.example.Customer" parameterType="int">
SELECT CUST_ID, CUST_NAME, RES_ID, CUST_TYPE
FROM TB_CUSTOMER
LIMIT #{limit}
</select>
</mapper>
※ 이 글에서는 Mybatis의 사용법이 아닌 원리를 다루려고 하기 때문에, resultType 등이 무슨 문법인지 등에 대한 설명은 하지 않으려고 합니다.
SQL문들은 개발자가 직접 작성하게 하되, 나머지는 프레임워크가 처리한다.
Mybatis를 통해 DB를 접근하는 간단한 예제 코드를 봐보면 다음과 같습니다.
// (1) SqlSession 요청
try (SqlSession sqlSession = sqlSessionFactory.openSession()) {
// (2) 쿼리 실행 요청
List<Customer> customers = sqlSession.selectList("org.example.TestMapper.getCustomers", 10);
for (Customer customer : customers) {
System.out.println(customer);
}
}
기존 JDBC만로 DB에 접근하던 것과는 다르게, Connection을 획득하거나 Statement를 생성하는 등의 코드가 없어진 것을 볼 수 있습니다. 다만 중요한 점은 Mybatis는 JDBC를 대체하여 보일러플레이트들을 없애는 기술이 아니라, JDBC 위에서 동작하면서 개발자 대신 Connection 획득이나 파라미터 설정 등의 작업을 대신 해주고 있는 기술이라는 점입니다. 위 코드에 나오는 SqlSession이라는 컴포넌트가 그 작업들을 대신 한다고 이해할 수 있습니다.
즉, Mybatis를 통해 DB를 접근할 때의 과정은 내부적으로 어떤 일들이 일어나는지는 아직까지는 모르나, 전체 흐름은 간단하게 다음처럼 도식화할 수 있습니다.

계속해서 Mybatis가 어떤 구성요소들을 어떻게 활용해 위 그림의 작업들을 개발자 대신 해주고 있는지 볼 텐데, 결국에는 이전에 살펴봤던 JDBC 스펙에서의 인터페이스들이 등장한다는 것을 미리 알아두면 흐름을 따라가는게 좀 더 편할 것 같습니다.
※ 다시 한 번 이전에 쓴 글들을 공유합니다. 위에서 나온 PreparedStatement 등의 용어가 낯설다면 1편을 봐보시는 걸 추천드립니다.
[JDBC] (1편) MyBatis, JPA 없이 JDBC로만 DB를 다루는 세상이었다면
[JDBC] (2편) JDBC 기반으로 직접 트랜잭션을 처리해보고, JDBC 스펙에서의 커넥션풀 알아보기
2. Mybatis가 실행할 SQL들을 찾는 방법
애플리케이션이 특정 SQL의 실행을 요청하면, Mybatis는 해당 SQL을 찾아서 실행해주게 됩니다. Mybatis의 핵심 컨셉 중 하나는 SQL문을 코드에서 분리해서 보관하는 것이었고, 그로 인해 xml파일에 따로 SQL들을 다음과 같이 가지고 있습니다.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example.TestMapper" >
<select id="getCustomers" resultType="org.example.Customer" parameterType="int">
SELECT CUST_ID, CUST_NAME, RES_ID, CUST_TYPE
FROM TB_CUSTOMER
LIMIT #{limit}
</select>
</mapper>
그러나 애플리케이션이 SQL 실행을 요청할 때마다 xml파일을 디스크에서 읽는다면, 매 요청마다 파일 I/O는 물론 xml을 파싱하는 비용 등이 들게 됩니다. 그래서 Mybatis는 애플리케이션이 시작될 때 xml파일을 딱 한 번 파싱하고, 그 결과를 메모리에 두는 방식을 사용하기로 했습니다. 다만 파싱한 결과로써 SQL문 하나만 가지고 있는 건 의미가 없습니다. 따라서
- 해당 SQL의 식별자(id값)이 뭔지
- 해당 SQL이 어떤 타입의 SQL인지(SELECT, INSERT 등)
- 해당 SQL에 어떤 파라미터들이 쓰이는지
- 해당 SQL의 결과를 어떤 DTO로 매핑해야 하는지
등 파싱하여 얻을 수 있는 다른 정보들도 가지고 있게 했고, Mybatis은 이 정보들을 MappedStatement라는 객체에 저장하게 했습니다. xml과 MappedStatement의 관계를 간단하게 도식화하면 다음과 같습니다.

그러면 자연스럽게 xml파일들을 파싱해서 MappedStatement를 생성하는 작업은 언제 어떻게 누가 하는지에 대한 의문이 생깁니다. Mybatis를 사용 시 Mybatis 설정 정보들을 mybatis-config.xml에 작성하고, SQL문들이 있는 xml들의 위치를 적어주는데요. Mybatis를 사용할 땐 이 정보들을 바탕으로 애플리케이션을 기동할 때 SqlSessionFactory라는 컴포넌트를 생성해야 하는데, 바로 이 과정에서 MappedStatement들이 생성됩니다.
※ mybatis-config.xml이 아닌 다른 이름을 써도 됩니다.
※ SQL문들이 있는 xml들을 mapper xml이라고도 부릅니다.
※ MappedStatement는 Map<String, MappedStatement> 형태로 메모리에 캐싱되며, id값이 해당 SQL을 찾는 키값이 됩니다.
SqlSessionFactory를 생성하는 예제 코드는 다음과 같습니다.
// mybatis-config.xml을 classpath에서 읽어서 사용
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// SqlSessionFactoryBuilder를 통해 sqlSessionFactory 생성 (이 과정에서 xml들을 파싱)
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
디버깅을 통해 실제 코드 흐름을 따라가보면 다음과 같이 mybatis-config.xml을 파싱한 뒤, 파싱 결과를 바탕으로 mapper xml들을 파싱하며 MappedStatement들을 생성하는 과정을 볼 수 있습니다.
// XMLConfigBuilder.class -> mybatis-config.xml을 파싱하는 역할
// 제가 임의로 간결하게 작성했습니다.
public Configuration parse() {
this.parseConfiguration(this.parser.evalNode("/configuration"));
return this.configuration;
}
// XMLMapperBuilder.class -> mapper xml을 파싱하는 역할
// 제가 임의로 간결하게 작성했습니다.
private void configurationElement(XNode context) {
this.parameterMapElement(context.evalNodes("/mapper/parameterMap"));
this.resultMapElements(context.evalNodes("/mapper/resultMap"));
this.sqlElement(context.evalNodes("/mapper/sql"));
this.buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
}
// MapperBuilderAssistant.class -> MappedStatement를 등록하는 역할
// 제가 임의로 간결하게 작성했습니다.
public MappedStatement addMappedStatement(String id, SqlSource sqlSource, ... 생략) {
MappedStatement statement = statementBuilder.build();
this.configuration.addMappedStatement(statement);
return statement;
}
즉 SqlSessionFactory가 생성되면서 MappedStatement를 만드는 과정을 간단히 도식화하면 다음과 같습니다.

실제로 SqlSessionFactory가 생성될 때 갖고 있게 되는 Configuration 객체를 보면, 다음과 같이 MappedStatement와 관련 메서드를 가지고 있는 것을 확인할 수 있습니다.
// Configuration.class
public class Configuration {
// ... 생략
protected final Map<String, MappedStatement> mappedStatements;
public void addMappedStatement(MappedStatement ms) {
// ... 생략
}
public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) {
// ... 생략
}
※ Configuration: MyBatis가 XML로부터 파싱한 모든 설정정보 등을 담고 있는 객체
3. Mybatis가 SQL을 실행하는 방법 (1) - 메서드 호출이 PreparedStatement가 되기까지
Mybatis를 통해 SQL을 실행하게 되면, 처음에 말씀드렸듯이 Connection을 획득하고 PrepatedStatement를 만든 뒤, 파라미터들을 설정하여 쿼리를 실행하고 ResultSet을 DTO로 변환하는 과정을 내부적으로 수행하게 됩니다. 앞서 살펴본 MappedStatement를 바탕으로 이 과정을 어떻게 하는건지 하나씩 살펴보려고 하며, 우선 Connection 획득과 PreparedStatement 생성을 어떻게 하는지부터 보도록 하겠습니다.
이를 위해, Mybatis가 사용하는 다음 구성 요소들을 알고 넘어가야 합니다.
SqlSession
- 애플리케이션과의 인터페이스 역할을 하는 요소입니다
- 애플리케이션으로부터 특정 SQL의 실행 요청을 받아, 내부적으론 Executor에게 실행을 위임하여 처리합니다
Executor
- Mybatis의 실행 엔진 역할을 하는 요소입니다.
- SqlSession에게 위임받은 작업을 처리하기 위해 StatementHandler를 생성하고 쿼리 실행 흐름을 조율합니다.
- SqlSessionFactory가 SqlSession을 만들어줄 때마다 SqlSession당 하나씩 Executor의 구현체를 만들어줍니다
- 이때 Configuration이 들고 있는 ExecutorType(SIMPLE, REUSE, BATCH)에 따라 서로 다른 구현체를 갖게 됩니다.
StatementHandler
- JDBC Statement 계열의 객체를 준비하고, 파라미터를 설정과 실제 쿼리/업데이트를 실행하는 역할의 인터페이스입니다.
- Executor가 쿼리 실행시점에 내부적으로 생성하여 사용합니다.
(1) MappedStatement에서 실제로 실행할 SQL 가져오기 (BoundSql)
BoundSql
- MappedStatement가 가지고 있는 SQL문 정보로부터 동적콘텐츠들을 처리한 후 가져온 실제로 실행 예정인 "SQL 문자열"을 의미하는 객체입니다. (MappedStatement가 기본적으로 가지고 있는 SQL문은 동적콘텐츠(<if> 등..)을 가지고 있습니다)
- 파라미터 매핑 정보(ParameterMappings)도 함께 가지고 있습니다.
MappedStatement가 SQL문의 정보를 가지고 있는 건 맞습니다만, xml파일에는 SQL문을 다음처럼 동적콘텐츠들을 활용해 작성할 수도 있습니다.
<select id="getCustomersByCustomerType" resultType="org.example.Customer" parameterType="map">
SELECT CUST_ID, CUST_NAME, RES_ID, CUST_TYPE
FROM TB_CUSTOMER
<where>
<if test="customerType != null">
AND CUST_TYPE = #{customerType}
</if>
</where>
LIMIT #{limit}
</select>
이 경우 실행시점에 실질적으로 어떤 SQL이 수행되는건지 결정되어야 합니다만, MappedStatement를 만드는 시점 즉 애플리케이션 구동 시점에 이를 결정하는 건 불가능합니다. 따라서 MappedStatement는 런타임에 파라미터 정보를 바탕으로 실질적으로 실행되어야 하는 SQL문을 BoundSql이란 객체로 만들어서 리턴하는 메서드를 제공해주고 있습니다.
실제로 애플리케이션이 쿼리 실행 요청을 보내면, MappedStatement를 활용해 다음처럼 BoundSql을 가져와서 쿼리의 실행에 사용합니다.
// (1) 애플리케이션에서 쿼리 실행 요청
List<Customer> customers = sqlSession.selectList("org.example.TestMapper.getCustomers", 10);
// (2) DefaultSqlSession.class - MappedStatement를 찾아서 실행
// 제가 임의로 간결하게 작성했습니다
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
MappedStatement ms = this.configuration.getMappedStatement(statement);
this.executor.query(ms, this.wrapCollection(parameter), rowBounds, handler);
}
// (3) CachingExecutor.class - MappedStatement로부터 BoundSql 획득하여 실행
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = this.createCacheKey(ms, parameterObject, rowBounds, boundSql);
return this.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
참고로 CachingExecutor는 SimpleDecorator를 멤버변수로 갖고 있는 Executor로, 2차 캐싱 적용을 위한 일종의 데코레이터 패턴을 적용한 요소로 이해할 수 있습니다.
(2) Connection 획득 ~ PreparedStatement 생성
이후의 흐름을 살펴보면, 가져온 BoundSql을 활용하여 StatementHandler를 생성하여 쿼리를 실행하게 됩니다. 이 부분을 뜯어보면 다음과 같습니다.
// SimpleExecutor.class
// 제가 임의로 간결하게 작성했습니다.
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
// (1) StatementHandler 생성
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// (2) Connection 획득 + PreparedStatement 생성 + 파라미터 설정
Statement stmt = this.prepareStatement(handler, ms.getStatementLog());
// (3) 쿼리 실행
List var9 = handler.query(stmt, resultHandler);
return var9;
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
// Connection 획득
Connection connection = this.getConnection(statementLog);
// PreparedStatement 생성
Statement stmt = handler.prepare(connection, this.transaction.getTimeout());
// 파라미터 설정 (이 부분은 다음 섹션에서 설명합니다)
handler.parameterize(stmt);
return stmt;
}
Connection을 획득하는 코드를 따라가보면, 다음처럼 JDBC에서 쓰던 DataSource.getConnection을 통해 Connection을 획득하는 것을 볼 수 있습니다.
// JDBCTransaction.class
protected void openConnection() throws SQLException {
// ... 생략
this.connection = this.dataSource.getConnection();
// ... 생략
}
또한 PreparedStatment를 생성하는 코드를 따라가보면, BoundSql과 Connection을 활용해 PreparedStatement를 생성하는 것을 볼 수 있습니다.
// PreparedStatementHandler.class
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = this.boundSql.getSql();
if (this.mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = this.mappedStatement.getKeyColumns();
return keyColumnNames == null ? connection.prepareStatement(sql, 1) : connection.prepareStatement(sql, keyColumnNames);
} else {
return this.mappedStatement.getResultSetType() == ResultSetType.DEFAULT ? connection.prepareStatement(sql) : connection.prepareStatement(sql, this.mappedStatement.getResultSetType().getValue(), 1007);
}
}
※ 파라미터를 설정하는 부분은 설명할 내용들이 조금 있어, 바로 아래에 별도 챕터로 기재합니다
4. Mybatis가 SQL을 실행하는 방법 (2) - MyBatis는 파라미터를 어떻게 자동으로 바인딩하는가
ParameterHandler
- StatementHandler가 멤버변수로 들고 있는 필드입니다.
- PreparedStatement의 파라미터를 설정하는 역할의 인터페이스입니다.
Executor가 StatementHandler의 parameterize 메서드를 호출하면 StatementHandler는 내부적으로 ParameterHandler에게 파라미터 바인딩를 위임합니다. ParameterHandler가 어떻게 바인딩하는지 살펴보려면 앞서 xml파일들을 스캔하며 MappedStatement들을 만들 때 해당 SQL의 파라미터 정보들을 어떻게 들고 있는지 봐야 합니다.

보시는 것처럼 SQL의 파라미터 부분(#{...}을 말합니다)들을 객체로 만들어서 MappedStatement에 담게 되는데요, 이 객체들을 ParameterMapping이라고 부릅니다. 이 객체는 여러 속성이 있겠으나 주요 속성들을 설명드리면 다음과 같습니다.
- property : 해당 파라미터의 이름을 의미합니다.
- javaType : 해당 파라미터의 java 클래스 타입을 의미합니다. 기본적으론 Object이나, parameterType으로 준 클래스에 해당 필드의 getter가 있다면 해당 getter의 리턴 타입으로 설정됩니다. 또한 SQL에서 파라미터를 작성할 때 #{customerType, javaType=string} 처럼 명시적으로 적어줄 수도 있습니다.
- jdbcType : JDBC는 자바 기반 프로그램이 어떤 DB와 붙어도 컬럼 타입들을 공통으로 가리킬 수 있는 표준 상수들을 java.sql.type에 정의하고 있는데요. Mybatis는 편한 사용을 위해 이 상수들을 감싸서 객체화했는데 이를 JDBC Type이라고 부릅니다. 즉 DB에서의 컬럼타입을 의미한다고 이해할 수 있습니다. ParameterMapping에서 이 속성은 기본적으론 null이나, SQL에서 파라미터를 작성할 때 #{customerType, jdbcType=VARCHAR} 처럼 적어주면 해당 값으로 세팅됩니다. 참고로 ParameterMapping에서의 jdbcType은 파라미터로 null값을 세팅하게 되는 경우 등에 활용됩니다
- typeHandler : PreparedStatement에 파라미터 세팅을 하려면 파라미터 타입에 따라 setInt, setString 등 어떤 메서드들을 호출해야 하는지 결정해줘야 하는데요, 그 역할을 TypeHandler가 해줍니다. 즉 PreparedStatement에 파라미터를 바인딩할 때, java 객체를 적절한 JDBC Type으로 변환해주는 역할로 이해할 수 있습니다. PameterMapping 생성 시 javaType속성값과 jdbcType속성값에 따라 Mybatis가 만들어둔 typeHandler들 중 하나가 선택되며, 개발자가 직접 커스텀한 typeHandler를 사용할 수도 있습니다.
즉 사용자가 쿼리 실행을 요청하게 되면, ParameterHandler가 각 ParameterMapping의 정보들을 활용해 사용자가 넘겨준 객체로부터 적절한 값들을 뽑아내서 PreparedStatement에 파라미터를 바인딩하게 됩니다. 사용자가 넘겨준 객체(자바빈 객체 또는 Map 등)에서 적절한 값을 빼오는 것은 리플렉션 등으로 구현되어 있으며, 파라미터를 바인딩하는 흐름을 코드로 살펴보면 다음과 같습니다.
// DefaultParameterHandler.class
// 제가 임의로 메서드를 간결화하여 작성했습니다
public void setParameters(PreparedStatement ps) {
List<ParameterMapping> parameterMappings = this.boundSql.getParameterMappings();
MetaObject metaObject = this.configuration.newMetaObject(this.parameterObject);
for (int i = 0; i < parameterMappings.size(); ++i) {
ParameterMapping parameterMapping = (ParameterMapping) parameterMappings.get(i);
String propertyName = parameterMapping.getProperty();
// 파라미터로 넣을 값. 리플렉션 등을 활용해 가져옴
Object value = metaObject.getValue(propertyName);
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
위 코드의 마지막 부분을 좀 더 따라가면, TypeHandler의 종류에 따라 최종적으로 PreparedStatement에 다음처럼 파라미터를 세팅하는 모습을 볼 수 있습니다. 예시 코드는 TypeHandler가 StringTypeHandler인 경우입니다.
// StringTypeHandler.class
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
5. Mybatis가 SQL을 실행하는 방법 (3) - ResultSet이 객체가 되기까지
ResultSetHandler
- StatementHandler가 멤버변수로 들고 있는 필드입니다.
- ResultSet를 읽어서 resultType, resultMap 기준으로 자바 객체로 변환하는 역할의 인터페이스입니다.
ResultSet을 DTO로 매핑하는 것은 ResultSetHandler라는 컴포넌트가 담당하며, 어떻게 매핑하는지 살펴보려면 앞서 xml파일들을 스캔하며 MappedStatement들을 만들 때 해당 SQL의 ResultSet 매핑 정보를 어떻게 들고 있는지 봐야 합니다.

보시는 것처럼 resultMap 태그에서 작성해준 정보들을 객체로 만들어서 MappedStatement에 담게 되는데요, 이 객체들을 ResultMapping이라고 부릅니다. 말 그대로 DB에서 가져온 데이터를 객체에 어떻게 매핑해줄지(어떤 컬럼을 어떤 필드에 매핑할지)를 정의하는 객체입니다. 여러 속성들이 있으나 주요 속성들을 설명드리면 다음과 같습니다. (ParameterMapping에서의 속성들과 매우 유사합니다)
- property : 해당 컬럼값이 매핑될 객체의 필드명을 의미합니다.
- column : DB에서의 컬럼명을 의미합니다.
- javaType : 해당 컬럼값이 어떤 java 클래스 타입으로 매핑될지를 의미합니다. DTO에서 해당 필드의 setter가 받는 파라미터 타입으로 설정되며 기본적으론 Object입니다. result 태그 등에서 <result property="customerName", javaType="String" ... /> 처럼 명시적으로 적어줄 수도 있습니다.
- jdbcType : ParameterMapping에서와 마찬가지로 DB에서의 컬럼타입을 의미한다고 이해할 수 있습니다. 기본적으론 null이나, <result property="customerName", jdbcType="VARCHAR" ... /> 처럼 명시적으로 적어줄 수도 있습니다. 참고로 ResultMapping에서의 jdbcType은 typeHandler 결정 시에 사용됩니다.
- typeHandler : ResultSet을 DTO에 매핑하려면 DB에서 가져온 컬럼의 타입에 따라 getInt, getString 등 어떤 메서드들을 호출해야 하는지 결정해줘야 하는데요, 그 역할을 TypeHandler가 해줍니다. ParameterMapping에서의 TypeHandler의 역할과 반대인 것으로 이해할 수 있습니다. ResultMapping 생성 시 javaType값과 jdbcType값에 따라 Mybatis가 만들어둔 typeHandler들 중 하나가 선택됩니다.
즉 사용자가 요청한 쿼리가 실행되고 나면, ResultSetHandler가 각 ResultMapping의 정보들을 활용해 ResultSet으로부터 적절한 값들을 뽑아내서 DTO 객체의 필드들에 매핑하게 됩니다.
// DefaultResultSetHandler.class
// 제가 임의로 메서드를 간결화하여 작성했습니다
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
// DTO 객체 생성
Object rowValue = this.createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
MetaObject metaObject = this.configuration.newMetaObject(rowValue);
// ResultMappings 순회하면서 DTO에 setter로 값 세팅
this.applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix);
return rowValue;
}
applyPropertyMappings 메서드 흐름을 좀 더 따라가보면, ResultMapping의 TypeHandler를 통해 ResultSet으로부터 적절한 getter를 사용하여 컬럼값을 빼내고, DTO의 setter를 호출하여 값을 세팅하는 모습을 볼 수 있습니다.
// DefaultResultSetHandler.class
// 제가 임의로 메서드를 간결화하여 작성했습니다
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
boolean foundValues = false;
for (ResultMapping propertyMapping : resultMap.getPropertyResultMappings()) {
// ResultMapping 정보 활용해 ResultSet으로부터 컬럼값 추출
Object value = this.getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
String property = propertyMapping.getProperty();
if (value != null) foundValues = true;
// DTO 객체의 setter를 호출하여 값 세팅
if (property != null && value != null) {
metaObject.setValue(property, value);
}
}
return foundValues;
}
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
String column = this.prependPrefix(propertyMapping.getColumn(), columnPrefix);
// ResultMapping의 타입핸들러를 꺼내서 ResultSet으로부터 컬럼값 추출
return typeHandler.getResult(rs, column);
}
// StringTypeHandler.class
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
6. 전체 흐름 정리
Mybatis를 통해 DB를 접근할 때의 과정은 간단하게 다음처럼 도식화할 수 있다고 말씀드렸습니다.
이제 Mybatis의 동작 원리를 살펴봤으니, 위 그림을 좀 더 세분화해서 다음처럼 나타낼 수 있습니다.

7. Mybatis가 포기한 것
지금까지 Mybatis가 기존에 JDBC로 DB에 접근할 때 발생하던 보일러 플레이트들을 어떻게 해결하는지 살펴봤습니다. 하지만 모든 기술이 그러하듯 장점만 있을 수는 없는데요, Mybatis도 포기한 문제(내지는 해결하지 못한 문제)가 존재합니다.
앞서 설명했듯 Mybatis의 핵심 컨셉은 "SQL문들은 개발자가 직접 작성하게 하되, 나머지는 프레임워크가 처리한다"입니다. 이 말은 개발자가 관계형 DB의 방식으로 사고해야 한다는 한 가지 전제를 포함하는 의미이기도 합니다. 데이터를 테이블로 보고, 관계를 JOIN으로 표현하고, 결과를 행과 컬럼으로 다뤄야 한다는 뜻입니다. 이는 Java라는 언어가 갖는 객체 지향적 관점과는 다른 패러다임을 갖는 것이기 때문에, 개발자가 두 언어의 차이점을 중간에서 메꿔주는 데 시간을 많이 쏟게 되는 문제가 남게 됩니다. 예를 들면 코드베이스가 커질수록 단순한 CRUD도 모든 엔티티마다 추가해줘야 하고, 연관관계가 복잡해질수록 resultMap도 복잡해지고, DB 스키마가 바뀌면 SQL도 직접 바꿔줘야 하는 것 등이 있습니다.
그래서 "SQL도 개발자가 직접 쓰지 않게 하는 건 어떨까?" 라는 생각이 나오게 됐고, 후에 객체와 객체 간의 관계만 정의하면, SQL 생성부터 연관 객체 로딩까지 프레임워크가 처리하는 ORM 기술들이 나오게 됩니다.
정리하면 MyBatis는 "JDBC를 통한 DB 직접 접근"의 보일러 플레이트를 제거하는 데 성공했지만, 여전히 SQL 중심으로 사고를 요구하게 됩니다. 복잡한 집계나 추출 등 SQL을 직접 제어해야 하는 요구사항이 있는 시스템들이 존재하므로, "SQL 중심의 사고를 요구"한다는 것은 단점이 아닌 패러다임으로 봐야 합니다. 다만 이는 객체 중심 사고와의 간극이 존재하는 것이므로, SQL 중심의 사고 및 제어가 필요하면 Mybatis같은 SQL Mapper를, 객체 중심의 사고가 필요하다면 ORM을 선택하는 것이 필요합니다.
레퍼런스
https://mybatis.org/mybatis-3/
https://mybatis.org/mybatis-3/apidocs/index.html
'WEB > JAVA' 카테고리의 다른 글
| [JDBC] (2편) JDBC 기반으로 직접 트랜잭션을 처리해보고, JDBC 스펙에서의 커넥션풀 알아보기 (0) | 2026.02.23 |
|---|---|
| [JDBC] (1편) MyBatis, JPA 없이 JDBC로만 DB를 다루는 세상이었다면 (1) | 2026.01.11 |
| 한계를 뛰어넘는 자바의 마법, Virtual Thread 뜯어보기 (5) | 2024.10.09 |
| JNI(Java Native Interface)란? (feat. 자바 스레드 생성) (2) | 2024.09.15 |
| 이 함수형 인터페이스에는 추상메서드가 2개 이상인데요? (feat.Object) (1) | 2024.07.21 |