
MySQL, 그리고 InnoDB의 Index
인덱스(Index)는 DB에서 테이블의 데이터를 빠르게 검색하기 위해 사용되는 보조적인 자료구조로, 인덱스와 실제 데이터는 따로 보관 및 관리된다. 전통적으로 인덱스를 위해 가장 많이 사용되는 자료구조는 B-tree (Balanced Tree)로, Leaf Node는 실제 데이터 레코드를 찾아갈 수 있는 주솟값을 가지고 있다.

MySQL 역시 B-tree 기반 인덱스를 사용하며, InnoDB 엔진의 경우 클러스터링 인덱스(클러스터링 테이블이라고도 부름)를 사용하는데 이는 테이블에서 PK(Primary Key)값이 비슷한 레코드들끼리 묶어 저장하는 걸 의미한다. 즉 스토리지 엔진으로 InnoDB를 사용한다면 아무 것도 하지 않아도 알아서 PK값들에 의해 B-tree 구조로 테이블의 데이터가 저장된다(각 Leaf Node가 레코드의 모든 컬럼 값을 가짐). 즉 PK값에 따라 레코드의 저장 위치가 결정되는 것이며, 만약 PK값이 변경된다면 해당 레코드가 저장되는 물리적 위치 또한 바뀌게 됨을 의미한다. 따라서 이렇게 클러스터링 인덱스로 저장되는 테이블은 PK 기반의 검색이 매우 빠르나 레코드의 저장이나 PK 변경은 상대적으로 느리다.
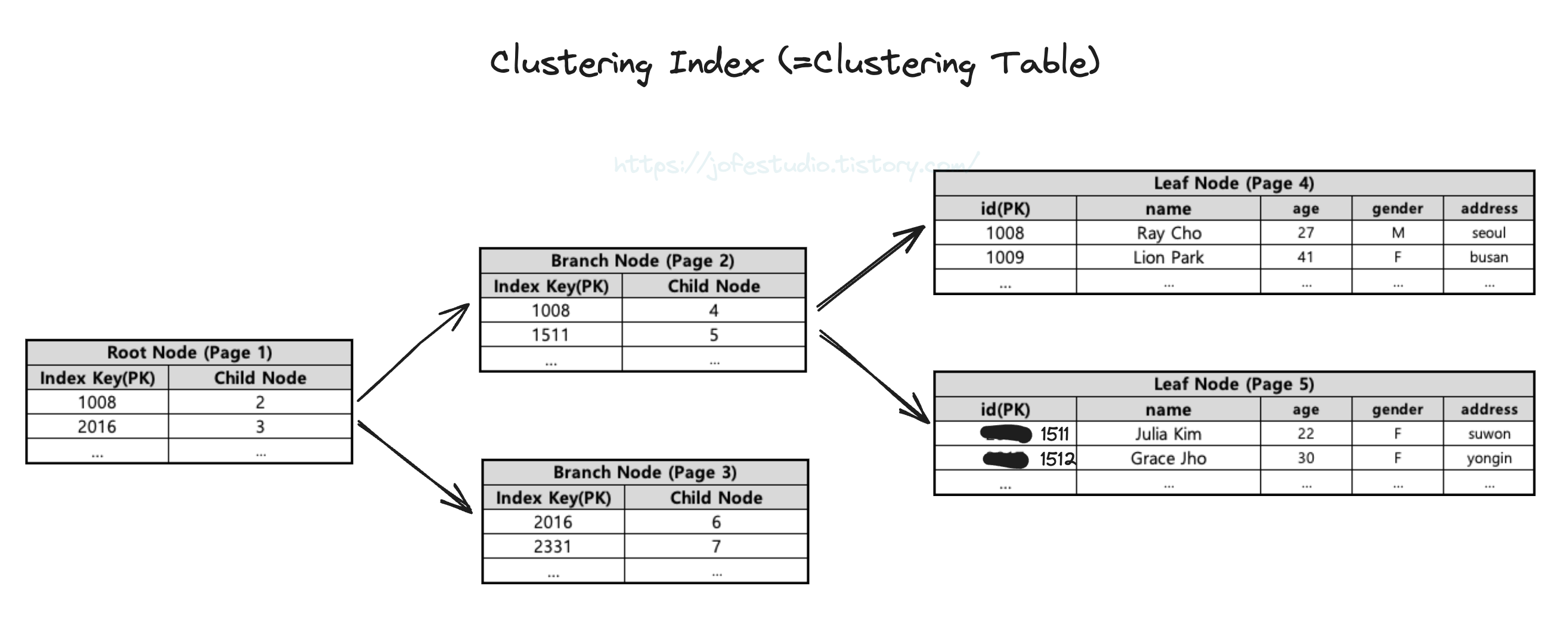
이 특성 때문에, 세컨더리 인덱스에 대한 B-tree를 기준으로 볼 때 스토리지 엔진으로 MyISAM을 사용할 경우 Leaf Node가 실제 레코드의 물리적인 주소들을 가지는 반면 InnoDB 는 Leaf Node가 PK를 가진다. 즉 InnoDB를 사용할 경우 세컨더리 인덱스를 통해 데이터를 읽을 때 데이터를 바로 찾아가는 게 아니라, Leaf Node에 저장된 PK를 이용해 클러스터링 인덱스에서 찾아가게 된다.
본 포스트에서는 Index를 사용하지 않는 Full Table Scan방법과 Index를 사용하는 4가지 Scan 방법에 대해 다룬다.
Full Table Scan (=Table Full Scan)
말 그대로 테이블 전체 데이터를 순차적으로 scan하는 방식이다(배열에서 모든 데이터를 선형탐색으로 읽는 것에 비유할 수 있다). InnoDB가 데이터(인덱스도 포함)들을 저장하는 기본적인 단위는 "페이지"인데, Full Table Scan은 테이블의 데이터가 담긴 페이지들을 모두 읽어와서 읽게 된다. 레코드가 많은 테이블의 경우, Full Table Scan은 성능 저하의 주범이 되는 경우가 많다. 일반적으로 인덱스가 없거나, 또는 인덱스를 활용할 수 없거나, 아니면 테이블의 레코드가 너무 적어서 인덱스를 사용하지 않고 테이블 전체를 읽는 게 더 빠를 경우 이 방법이 사용된다.
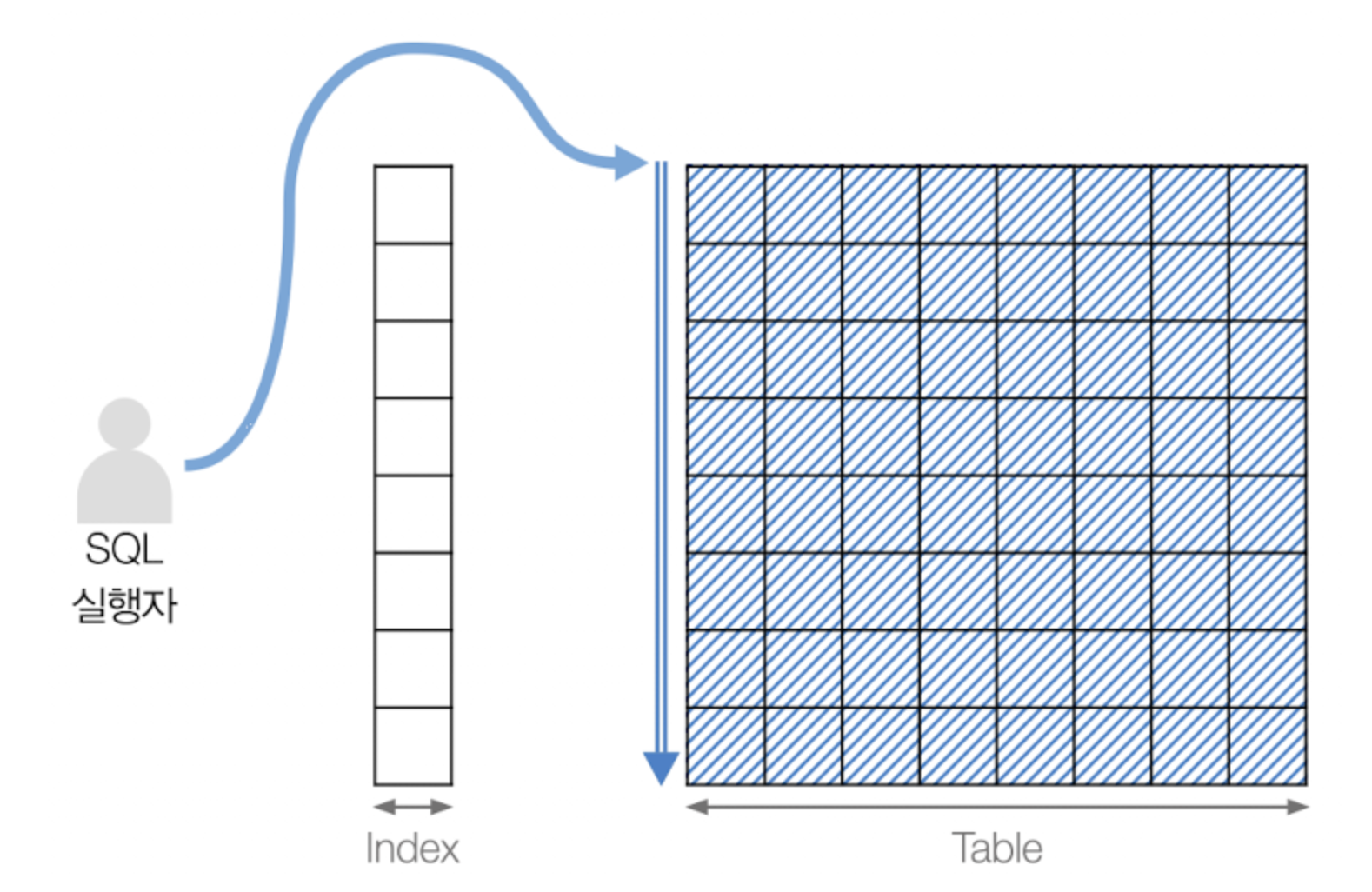
Index Full Scan
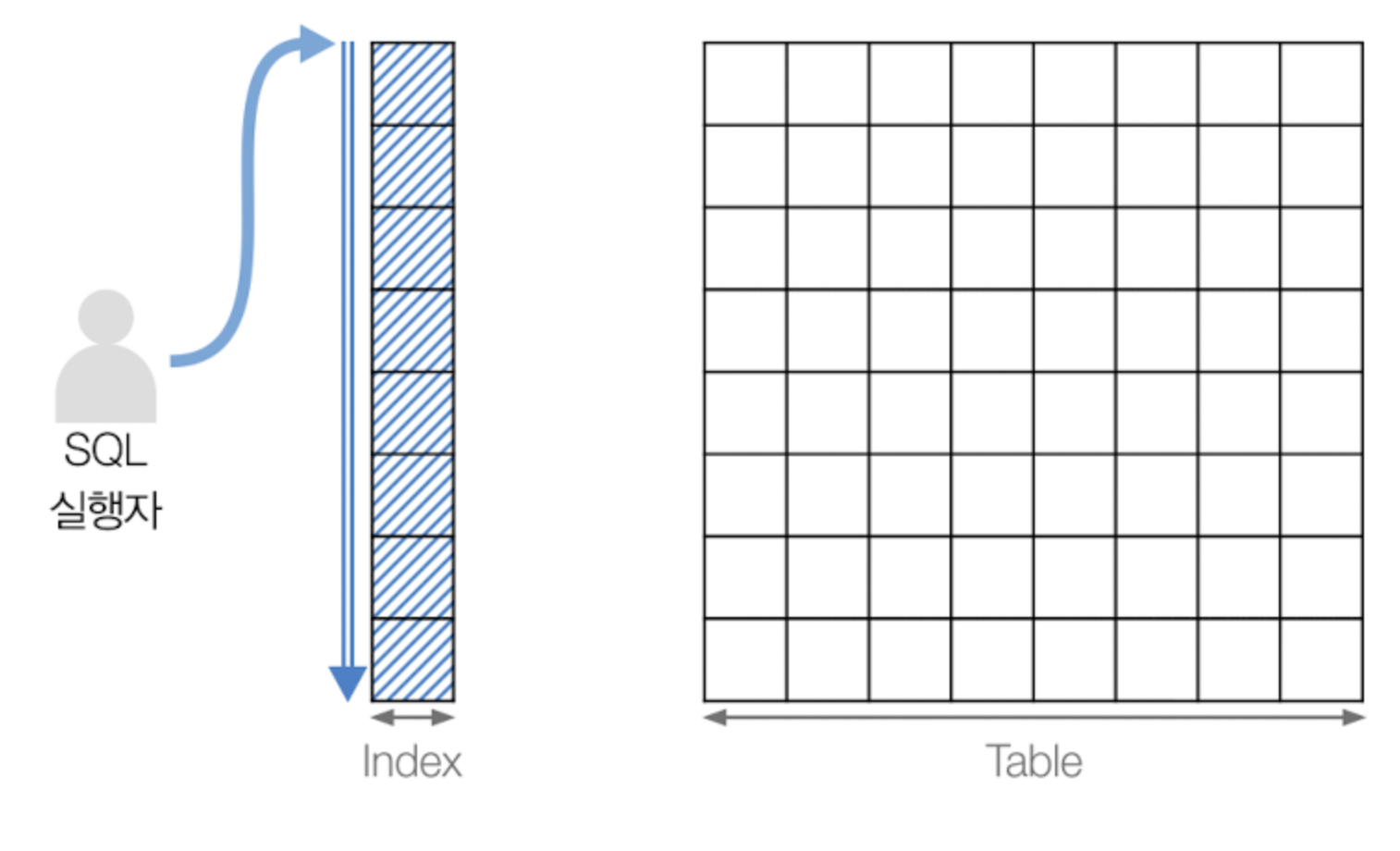
인덱스의 Leaf 노드 전체(즉 인덱스의 처음부터 끝까지)를 순차적으로 scan하지만 실제 테이블을 참조하지는 않는 방식을 말한다. 쿼리가 인덱스에 명시된 컬럼들만으로 조건을 처리가능한 경우에 주로 이 방법이 사용된다.(B-tree의 각 노드가 인덱스로 명시된 컬럼값과 child node의 위치를 키-값 형태로 가지고 있음을 상기할 것) 인덱스 뿐만이 아닌 레코드까지 읽어야 한다면 절대 이 방식을 사용하지 않으며, 실제 테이블을 참조하지는 않으니 Full Table Scan보다는 효율적(왜냐면 인덱스의 전체 크기가 테이블 자체의 사이즈보다 작아서 Disk I/O가 줄어들기 때문)이다.
참고로 이렇게 쿼리가 인덱스에 존재하는 컬럼만으로 처리 가능할 때 "커버링 인덱스"라고 부른다.
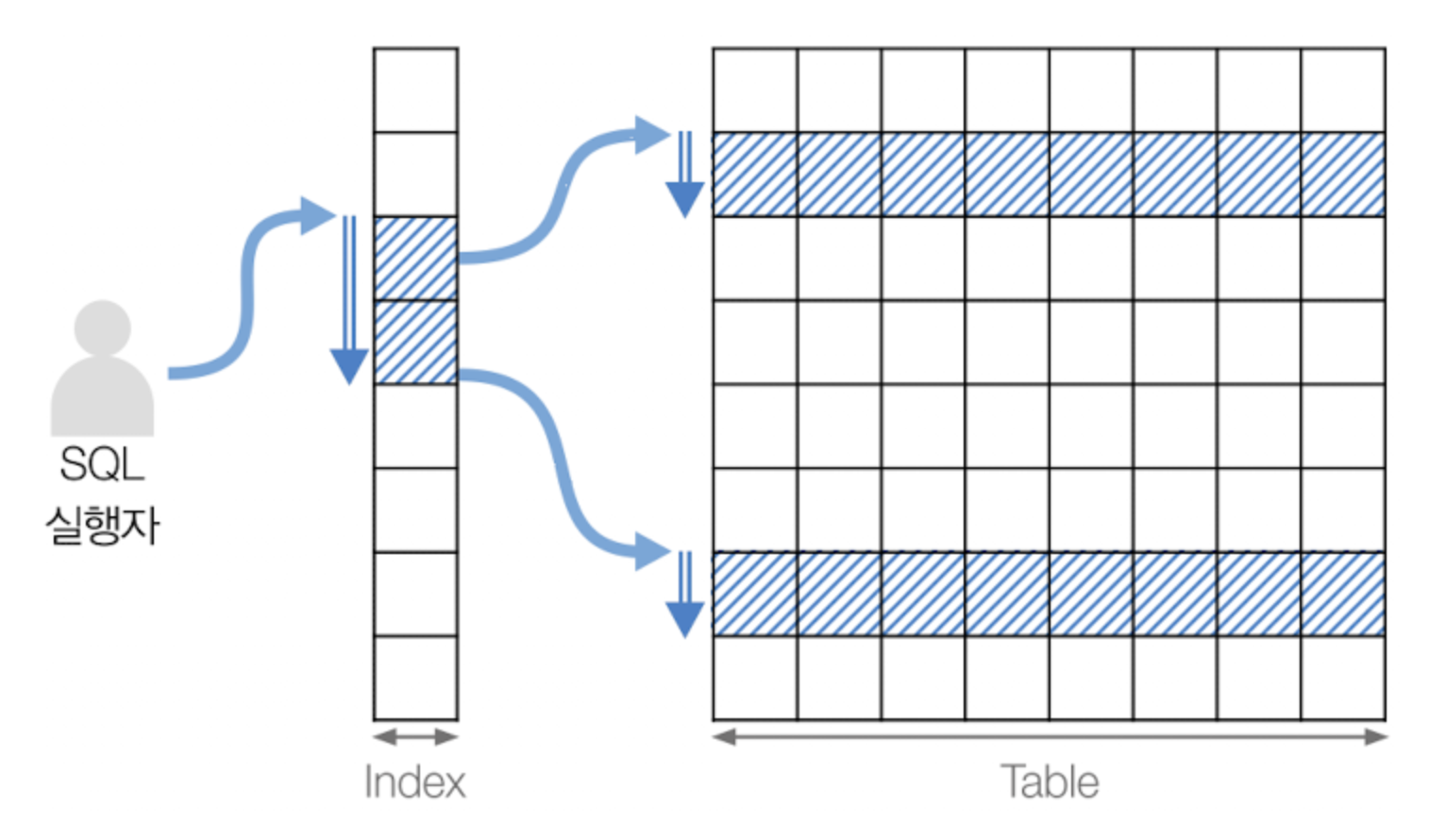
Index Range Scan
특정 범위만큼의 인덱스를 스캔한 뒤 이에 대응하는 레코드들을 읽는 방식이다. 쿼리에서 BETWEEN이나 부등호 등이 사용되어 검색해야 할 인덱스의 범위(range)가 결정됐을 때 사용된다. 스캔의 시작점이 되는 리프 노드만 찾으면 그때부터는 종료 지점까지의 리프 노드들을 쫙 스캔한 후(B+ tree는 리프 노드끼리도 서로 연결돼있음을 상기), 필요하다면 읽은 리프 노드들이 가리키는 레코드들을 읽어온다(따라서 Random I/O가 수반되게 된다). 쿼리가 인덱스에 명시된 컬럼들만으로 조건을 처리가능하다면(즉 커버링 인덱스) Index Full Scan처럼 테이블 레코드들을 읽어오는 과정은 없다.
Loose Index Scan
인덱스에서 필요한 부분만 선택적으로 스캔한 뒤 이에 대응하는 레코드들을 읽는 방식이다. Index Range Scan과 비슷하게 동작하나, 필요한 인덱스 키와 불필요한 인덱스 키를 구분한 뒤 불필요한 인덱스 키는 무시하는 식으로 동작한다. 보통 GROUP BY, MAX, MIN 등이 사용된 쿼리를 최적화할 때 사용된다.
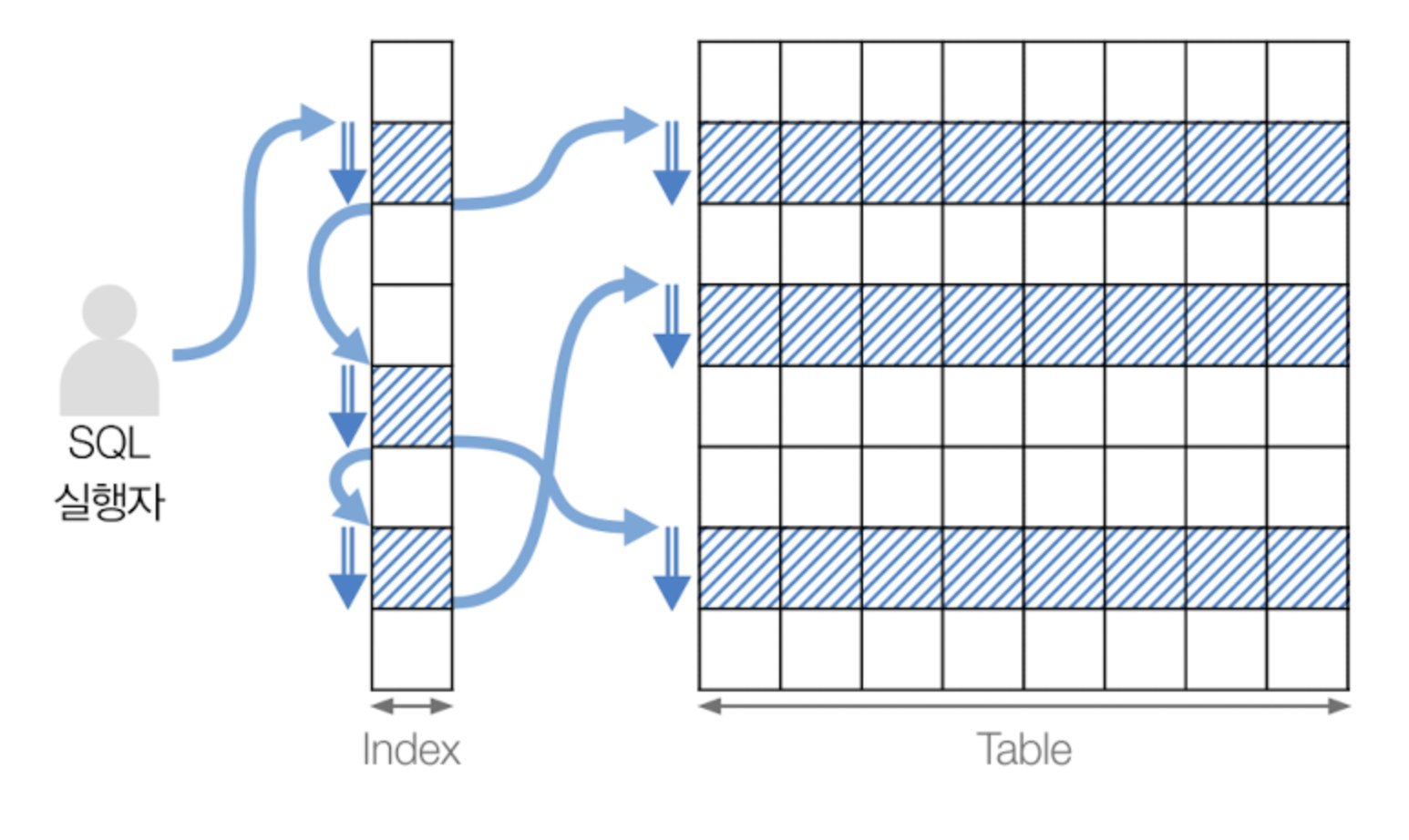
Index Skip Scan
인덱스는 두 개 이상의 컬럼에 대해서도 만들어줄 수 있는데(멀티 컬럼 인덱스 등으로 부름), 이 때 컬럼 순서에 따라 인덱스가 어떤 기준으로 정렬되는지가 결정된다.(예를 들어 A, B 순서로 인덱스를 만들었다면 A에 대해 먼저 정렬된 다음 B에 대해 정렬됨) 이때 WHERE절에 멀티 컬럼 인덱스의 첫 컬럼이 없으면 원래 인덱스를 사용할 수 없으나, 첫 컬럼이 없음에도 불구하고 인덱스를 사용할 수 있는 스캔 방식이 이 Index Skip Scan이다.
예로, student테이블에 대해 다음과 같이 gender, address에 대해 인덱스가 걸려있다고 해보자.
ALTER TABLE students ADD INDEX ix_gender_address (gender, address);
이때다음 쿼리는 원래는 Full Table Scan 또는 Index Full Scan(커버링 인덱스인 경우)으로 수행될 것이다.
SELECT gender, address
FROM students
WHERE address LIKE "경기도%";
하지만 Index Skip Scan을 사용하면 WHERE절에서 쓰이지 않은 인덱스의 선행 컬럼에 대해 가능한 값들을 구한 다음, 해당 컬럼의 조건을 추가해 쿼리를 다시 실행하는 형태로 처리하게 된다. 즉 여기서는 WHERE절에서 쓰이지 않은 gender라는 컬럼에 대해, 해당 컬럼에서 유니크한 값들을 모두 뽑은 다음 다음과 같은 형태의 쿼리를 다시 실행하게 된다.
SELECT gender, address
FROM students
WHERE gender = "M" AND address LIKE "경기도%";
SELECT gender, address
FROM students
WHERE gender = "F" AND address LIKE "경기도%";
참고로, Index Skip Scan은 WHERE절에서 쓰이지 않는 선행컬럼의 유니크한 값의 개수가 적어야 하고(많으면 오히려 쿼리를 처리하는 속도가 더 느려질 수 있기 때문), 커버링 인덱스를 만족해야 한다는 단점이 있다.
'DB > MySQL' 카테고리의 다른 글
| [MySQL] WITH ROLLUP을 활용한 그룹별 중간 집계 산출법 (0) | 2024.03.03 |
|---|---|
| PARTITION BY와 GROUP BY의 차이점 (1) | 2024.01.06 |
| mysqldump를 활용한 DB 백업 (0) | 2023.11.26 |