자바는 DB를 다룰 때 각 DB별로 API를 만들지 않고 어떤 DB든 간에 JDBC라는 표준을 통해 접근할 수 있도록 인터페이스를 제공하고 있습니다. 아무래도 저는 학창 시절에는 JPA를 잠깐 사용하고, 현재 회사에서는 MyBatis를 사용하면서 DB 접근 기술의 근간에 위치하고 있는 JDBC만을 사용해서 DB를 다뤄본 적은 없는데요. 자바와 스프링 환경에 대한 공부를 하면서 JPA나 MyBatis가 추상화하고 있는 '내부적인 동작 방식'이 궁금해져서 공부를 했었고, 그 내용을 공유하고자 합니다.
먼저 JDBC가 어떤 계층 구조를 가지고 애플리케이션과 DB 사이를 연결하는지에 대한 구조도입니다.
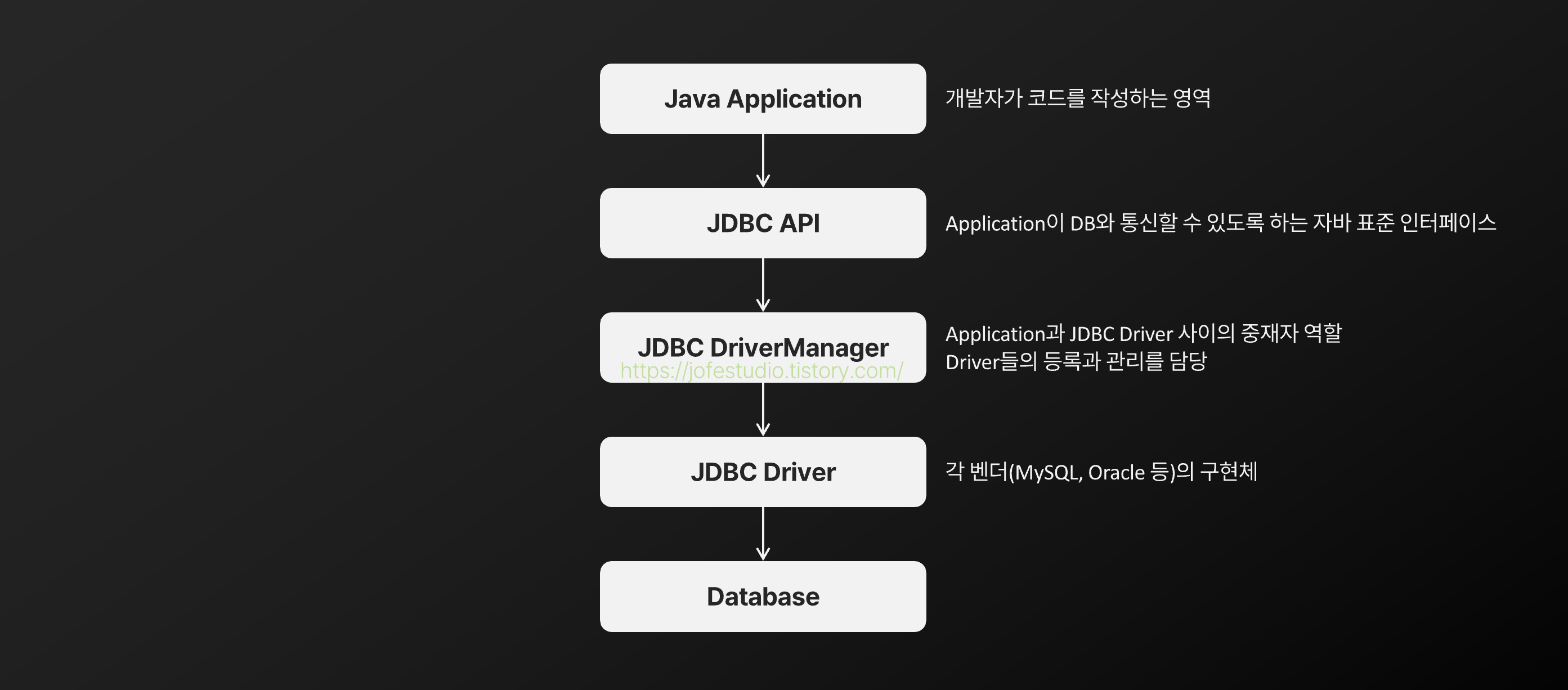
우리가 비즈니스 로직을 짜는 애플리케이션 레이어에서 JDBC API를 호출해서 DB에 접근하게 되는데요. 이렇게 JDBC를 통해 DB를 접근하게 되면 다음 절차를 따르게 됩니다.
1) 커넥션 생성
2) 구문(Statement) 생성 및 컴파일
3) 구문 실행
4) 실행 결과 처리
5) 커넥션 해제
이제 각 절차들을 조금 더 자세히 알아보고, JDBC를 통해 DB를 다뤄보는 예시를 보겠습니다.
참고) 공식 문서 상에서 커넥션을 맺게 되는 target DB를 'data source'라고 표현하는데요. 아무래도 자바 표준 스펙에서 정의하고 있고 이 글에서도 자주 쓰이는 'DataSource'와 헷갈릴 소지가 있어 이 글에서는 'data source'를 '데이터 원천'으로 작성했습니다.
1. 커넥션 생성 (Establishing Connection)
커넥션 생성은 특정한 데이터 원천과 커넥션(연결)을 맺는 것을 의미합니다. 데이터 원천은 DBMS가 될 수도 파일시스템이 될 수도 있습니다. 커넥션은 JDBC 인터페이스에서 Connection 객체로 표현되는데요, 일반적으로 JDBC를 사용하는 애플리케이션은 커넥션 생성 시 다음 두 클래스 중 하나를 사용하여 커넥션을 생성합니다.
1) DriverManager
여러 JDBC Driver들을 등록하고 관리하는 역할을 하는 매니저 클래스입니다. DriverManager를 사용해 커넥션을 얻을 경우, 데이터베이스 URL을 사용해 애플리케이션을 데이터 원천에 연결합니다.
2) DataSource
DriverManager보다 개선된 기능(커넥션 풀링 등)을 제공하는 인터페이스입니다. 벤더사(MySQL, Oracle 등)마다 DataSource 구현체 클래스를 제공하며, DataSource 객체의 속성(properties)들은 특정한 데이터 원천을 나타내도록 설정됩니다. DataSource 사용 시 아무래도 애플리케이션 입장에서는 인터페이스에 의존하게 되는 것이므로, 내부적인 연결 정보(properties 등으로 표현되는)나 구현체가 바뀌어도 영향을 받지 않게 된다는 장점이 있습니다.
참고) 커넥션 풀링 : DB Connection 객체를 미리 생성해 풀에 보관하고, 필요할 때마다 빌려 쓴 뒤 반납하는 관리 기법을 말합니다.
1 - 1.DriverManager를 통한 커넥션 생성
참고) dbms는 mysql을 쓴다고 가정합니다.
public Connection getConnectionByDriverManager(String username, String password) throws SQLException {
Properties connectionProps = new Properties();
connectionProps.put("user", username);
connectionProps.put("password", password);
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/bank_demo",
connectionProps
);
System.out.println("Connected to database successfully.");
return conn;
}
DriverManager의 getConnection 메서드가 커넥션을 생성하며, 코드에 드러나있는 것처럼 데이터베이스URL을 사용하여 커넥션을 생성합니다.
1 - 2. DataSource를 통한 커넥션 생성
앞서 말했듯 DataSource는 인터페이스로, 벤더사마다 DataSource 인터페이스의 구현체 클래스를 제공합니다. 보통 시스템 관리자가 Tomcat 등을 사용해서 DataSource를 배포(등록)한 뒤 애플리케이션 개발자가 등록된 DataSource를 사용해 커넥션을 얻는 식으로 사용합니다. 참고로 DataSource는 커넥션 풀링과 분산 트랜잭션을 제공할 수 있다는 장점도 가집니다.
DataSource는 다음 3가지 방식으로 구현될 수 있습니다. (1번 선택지는 무조건 포함해야 하고, 대개 분산 트랜잭션을 지원하는 DataSource는 커넥션 풀링도 지원합니다.)
1) 풀링되지 않거나 분산 트랜잭션에서 쓰이지 않는 심플한 커넥션을 제공하는 Basic한 DataSource
2) 커넥션 풀링을 지원하는 DataSource (즉 여기서 쓰이는 Connection 객체는 재사용될 수 있는 Connection 객체)
3) 분산 트랜잭션을 지원하는 DataSource (즉 여기서 쓰이는 Connection 객체는 분산 트랜잭션에서 사용될 수 있는 Connection 객체)
1 - 2 - 1. DataSource 객체 배포(등록)
시스템 관리자가 애플리케이션 개발자들이 사용 가능하도록 DataSource 객체를 배포(등록)하는 과정이며, 보통 다음과 같은 형식의 3단계로 구성됩니다.
1) DataSource 객체 생성
2) 해당 객체의 properties 세팅
3) JNDI(Java Naming and Directory Interface) API 등의 방법을 통해 해당 객체를 등록
참고) 과거 WAS 환경에서는 이러한 DataSource를 JNDI라는 디렉토리 서비스에 등록해두고 찾아 쓰는 방식을 주로 사용했습니다. 현대 스프링 기반 환경에서는 빈으로 등록해서 많이 활용합니다.
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setServerName("localhost");
dataSource.setPortNumber(3306);
dataSource.setDatabaseName("bank_demo");
dataSource.setUser(username);
dataSource.setPassword(password);
Context ctx = new InitialContext();
ctx.bind("jdbc/BankDemoDS", dataSource);
1 - 2 - 2. DataSource 객체 사용 (애플리케이션 개발자 역할)
애플리케이션 개발자는 시스템 관리자가 등록한 DataSource를 다음과 같이 활용합니다.
1) JNDI를 통해 DataSource 조회 (lookup)
2) 반환된 DataSource의 getConnection() 메서드를 호출하여 커넥션 획득
3) 커넥션 풀링 사용 시 커넥션을 다 쓰고 나면 커넥션 반환 (close 호출)
Context ctx = new InitialContext();
DataSource dataSource = (DataSource) ctx.lookup("jdbc/BankDemoDS");
Connection conn = dataSource.getConnection();
2. 쿼리문 생성 및 작성 (Create Statements)
JDBC 인터페이스에서 쿼리문(구문)을 표현하는 인터페이스는 Statement입니다. 해당 객체를 '실행'하게 되면 실행결과로 ResultSet 객체(데이터베이스 결과 집합을 의미하는 JDBC 인터페이스 상에서의 객체)를 만들어줍니다. Statement 객체를 만들려면 Connection 객체가 필요하며 생성 예시는 다음과 같습니다.
stmt = con.createStatement();
Statement에는 다음 3종류가 있습니다.
1) Statement
파라미터가 없는 간단한 SQL문 생성에 쓰입니다.
2) PreparedStatement
Statement를 상속하며, 파라미터가 존재하는 SQL문을 미리 컴파일하는데 쓰입니다.
3) CallableStatement
PreparedStatement를 상속하며, 파라미터가 존재할 수 있는 프로시저들을 실행할 때 쓰입니다.
2 - 1. PreparedStatement
Statement를 상속하는 클래스로, PreparedStatement의 주요 특징은 Statement와는 다르게 생성될 때 SQL문을 받는다는 점입니다. 이렇게 되면 대부분 해당 SQL문이 DBMS로 즉시 보내져 컴파일되는데요, 이를 통해 PreparedStatement가 실행되면 DBMS는 컴파일 과정 없이 SQL문을 바로 실행할 수 있게 된다는 장점을 얻을 수 있습니다.
참고) JDBC는 JVM과 DBMS 사이의 연결을 표준화한 스펙인 거고, 미리 컴파일된 쿼리를 저장하는 건 JDBC 쪽이 아니라 MySQL 등이 PREPARE 등을 통해 제공하는 기능입니다. 저희 회사에서 쓰고 있는 SingleStore의 경우는 PREPARE 기능을 제공하지 않는데, 이런 경우는 클라이언트(JDBC 쪽) 수준에서 최적화를 진행합니다. 또한 JDBC Driver 별로 특정 설정들을 통해 DB의 PREPARE를 사용할지 안 할지도 고를 수 있습니다. 이렇게 DB의 기능을 활용하는 PreparedStatement를 ServerPreparedStatement, 클라이언트 수준에서 최적화하는 PreparedStatement를 ClientPreparedStatement라고 부릅니다.
아래는 MySQL의 PREPARE를 사용하는 예제이며, 이 글 하단 레퍼런스 탭에 있는 카카오페이 테크블로그를 참고했습니다.
-- prepared statement 생성
PREPARE pstmt FROM 'SELECT * FROM TB_CUSTOMER WHERE id = ?';
-- 파라미터를 지정하여 prepared statement 실행
SET @a = 1;
EXECUTE pstmt USING @a;
-- prepared statement 제거
DEALLOCATE PREPARE pstmt;
PreparedStatement는 파라미터가 없는 SQL문의 실행에도 쓰일 수 있지만, 대개 파라미터가 있는 SQL문의 실행에 자주 쓰입니다. 이때 PreparedStatement는 클라이언트가 제공한 데이터를 SQL문장의 일부로서가 아니라 파라미터로만 취급하기 때문에 악의적인 입력이 코드로 해석되지 않아서, SQL Injection을 자연스럽게 예방하는 효과도 얻을 수 있습니다.
참고) 조금 더 풀어서 설명해보면, PreparedStatement는 SQL문 생성시 파라미터가 들어가는 위치들은 ?(Question Mark)를 두고, 이 구조를 컴파일한 뒤 나중에 ?가 있던 위치에 setter메서드를 통해 파라미터들을 세팅하게 되는데요. 이때 파라미터 값들을 코드가 아니라 '단순한 문자열 값'이나 숫자 데이터로만 처리하게 되어 SQL Injection이 예방되는 효과를 얻게 됩니다.
PreparedStatement의 생성과 파라미터 세팅, 실행 예시는 다음과 같습니다. SQL문에서 파라미터가 들어갈 곳은 ?(Question Mark)로 표시하며, 파라미터 설정은 PreparedStatement의 setter 메서드 중 적절한 것을 골라 사용합니다. setter 메서드의 파라미터로는 인덱스 번호와 설정할 값을 넘기며 인덱스는 1부터 시작합니다. 참고로 한 번 설정된 파라미터는 해당 인덱스 번호에 대한 setter 메서드를 호출하거나, PreparedStatement의 clearParameters()를 호출하기 전에는 설정된 값을 유지합니다.
String updateSql = "UPDATE account SET balance = balance + ? WHERE id = ?";
PreparedStatement pstmt = conn.prepareStatement(updateSql);
pstmt.setLong(1, 10000L);
pstmt.setString(2, "00000001029301");
pstmt.executeUpdate();
3. 쿼리 실행 (Executing Queries)
Statement 객체에서 execute 계열 메서드를 호출하여 쿼리를 실행 가능하며, execute 계열 메서드는 다음 3종류가 있습니다.
1) execute
두 개 이상의 ResultSet 객체를 리턴하는 SELECT 수행 시 사용하며, 쿼리가 반환하는 첫 번째 결과가 ResultSet객체면 true를 리턴합니다. Statement객체의 getResultSet 메서드를 반복 호출하여 ResultSet객체들을 하나하나 가져올 수 있습니다.
2) executeQuery
하나의 ResultSet 객체를 리턴하는 SELECT 수행 시 사용합니다.
3) executeUpdate
DML 수행 시 사용하며, 작성된 쿼리를 통해 영향을 받은 row의 수를 리턴합니다.
예를 들면 다음처럼 사용합니다.
ResultSet rs = stmt.executeQuery(query);
4. 실행 결과 처리 (Processing ResultSet Objects)
4 - 1. ResultSet?
Statement를 실행하여 ResultSet을 얻었다면, Cursor를 통해 ResultSet 객체의 데이터들에 접근할 수 있습니다. ResultSet은 데이터베이스 결과 집합을 나타내는 데이터 테이블로, 일반적으로 SELECT문을 실행하여 생성됩니다. PreparedStatement 등 Statement 인터페이스를 구현하는 모든 객체를 통해 생성 가능하며, 실행된 쿼리 결과를 조작하고 검색하는 다양한 메서드를 제공합니다.
Cursor를 통해 ResultSet 객체의 데이터들에 접근할 수 있는데요, 여기서의 Cursor는 DB Cursor의 개념이 아니라, ResultSet 객체의 데이터 하나하나를 가리키는 포인터를 말합니다. 최초에 Cursor는 첫 번째 row 앞에 위치하고 있고, ResultSet객체가 가지는 여러 메서드들을 통해 Cursor가 가리키는 위치(= 가리키는 row)를 바꿀 수 있습니다. 대표적으로 ResultSet의 next메서드는 Cursor를 다음 행으로 이동시키는데, Cursor가 마지막 행 뒤에 위치하게 되면 false를 리턴하는 점을 활용해 while루프를 통하여 ResultSet의 모든 데이터를 순회할 수 있습니다. 그 외에 next말고도 previos, first 등등 Cursor를 움직일 수 있는 방법은 다양합니다.
4 - 2. ResultSet에서 행의 특정 컬럼값 가져오기
ResultSet은 현재 Cursor가 가리키는 행에서 원하는 컬럼값을 가져올 수 있는 getter메서드들을 제공합니다. 컬럼의 인덱스 번호(1부터 시작)를 사용하거나 컬럼이름을 사용하여 값을 가져올 수 있습니다.
String selectSql = "SELECT * FROM TB_CUSTOMER WHERE CUST_ID = ?";
PreparedStatement pstmt = conn.prepareStatement(selectSql);
pstmt.setLong(1, 1L);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
Long custId = rs.getLong(1); // CUST_ID. 1은 컬럼의 인덱스
String custName = rs.getString("CUST_NAME"); // CUST_NAME
System.out.println("custId: " + custId + ", custName: " + custName);
}
5. 커넥션 해제 (반납)
Connection객체와 Statement객체, ResultSet객체들을 다 사용했다면 close메서드를 통해 리소스들을 해제합니다. 자바에서 제공하는 try-with-resources 문법을 사용하면 try 블록을 벗어날 때 자동으로 자원 해제를 할 수 있습니다.
예를 들면 다음과 같습니다.
String sql = "UPDATE account SET balance = balance + ? WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setLong(1, amount);
pstmt.setString(2, accountId);
pstmt.executeUpdate();
} catch (SQLException e) {
// 예외 처리 로직
log.error("Database error", e);
}
참고) SELECT 쿼리일 경우 ResultSet도 해제해야 합니다.
JDBC만을 사용한 DB 접근 실습
이제 JDBC만을 사용해 DB에 접근하는 것을 간단하게 실습해봤습니다. 실습 환경은 다음과 같았습니다
1) Java 21
2) mysql-connector-j 9.3.0
3) Mysql 8.0.33
테이블은 현재 제가 개인적으로 하는 토이 프로젝트에서 쓰고 있는 테이블 중 다음 테이블에 대해 SELECT하는 것으로 해봤습니다.
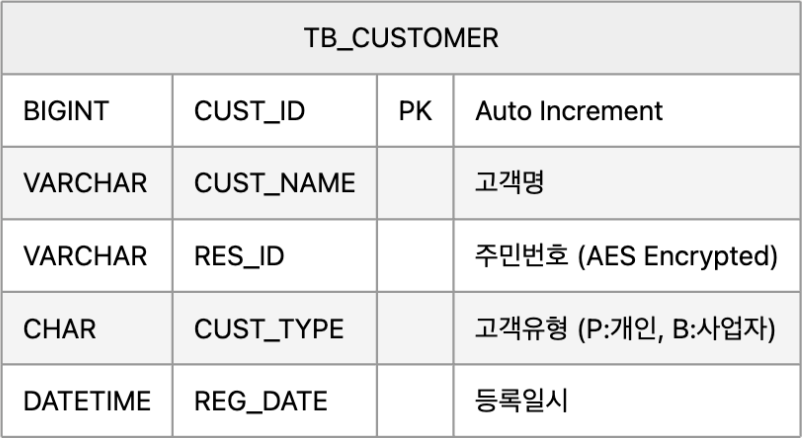
public static List<Customer> getCustomers() {
List<Customer> customers = new ArrayList<>();
String selectSql = "SELECT CUST_ID, CUST_NAME, RES_ID, CUST_TYPE FROM TB_CUSTOMER LIMIT ?";
try (Connection conn = JdbcSample.getConnectionByDriverManager();
PreparedStatement pstmt = conn.prepareStatement(selectSql)) {
pstmt.setInt(1, 10);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
Long custId = rs.getLong("CUST_ID");
String custName = rs.getString("CUST_NAME");
String resId = rs.getString("RES_ID");
String custType = rs.getString("CUST_TYPE");
customers.add(new Customer(custId, custName, resId, custType));
}
}
} catch (SQLException e) {
System.out.println("Database error: " + e.getMessage());
}
return customers;
}
개인적으론, PreparedStatement나 ResultSet 등 MyBatis나 JPA가 추상화해주고 있는 영역을 직접 공부도 해보고 처리도 해보니 애플리케이션과 DB가 어떻게 대화하고 있는지(?) 좀 더 잘 이해하게 된 것 같습니다. 역시 해보길 잘했다는 생각입니다. 다만 간단한 쿼리를 처리하고 있음에도 불구하고 리소스의 해제를 신경써야 한다거나 파라미터 세팅을 자꾸 해줘야 한다는 점, ResultSet을 매번 꺼내서 내가 사용할 객체의 값으로 세팅해줘야 하는 점들이 "아 이거 반복되면 번거롭겠다"라는게 느껴졌습니다.
이를 토대로 MyBatis와 JPA가 어떤 것들을 어떻게 추상화했는지 등도 공부할 수 있겠다는 생각이 듭니다. 또한 커넥션풀은 어떻게 활용되고 있는지에 대한 궁금증도 생기고 있습니다. 그래서 여기서 멈추지 않고, 커넥션풀을 사용하는 DataSource는 커넥션풀을 어떻게 활용하고 있는건지, 그리고 MyBatis와 JPA가 어떤 점들을 해결하려고 했고 어떤 것들을 포기한 기술인지도 공부를 해서 블로그에 올려보겠습니다!
글이 잘 읽힐 지 모르겠네요. 그래도 끝까지 봐주셔서 감사합니다.
레퍼런스
https://docs.oracle.com/javase/tutorial/jdbc/basics/index.html
Lesson: JDBC Basics (The Java™ Tutorials > JDBC Database Access)
The Java Tutorials have been written for JDK 8. Examples and practices described in this page don't take advantage of improvements introduced in later releases and might use technology no longer available. See Dev.java for updated tutorials taking advantag
docs.oracle.com
https://tech.kakaopay.com/post/how-preparedstatement-works-in-our-apps/
우리의 애플리케이션에서 PreparedStatement는 어떻게 동작하고 있는가 | 카카오페이 기술 블로그
JDBC를 직접 핸들링하지 않고, 다양한 추상화 계층 위에서 동작하는 우리의 애플리케이션에서 PreparedStatement는 어떻게 동작하는지 탐구한 결과를 공유합니다.
tech.kakaopay.com
'WEB > JAVA' 카테고리의 다른 글
| [MyBatis] (1편) MyBatis는 무엇을 해결해주는가? - MyBatis의 구성 요소와 동작 원리 (3) | 2026.03.17 |
|---|---|
| [JDBC] (2편) JDBC 기반으로 직접 트랜잭션을 처리해보고, JDBC 스펙에서의 커넥션풀 알아보기 (0) | 2026.02.23 |
| 한계를 뛰어넘는 자바의 마법, Virtual Thread 뜯어보기 (5) | 2024.10.09 |
| JNI(Java Native Interface)란? (feat. 자바 스레드 생성) (2) | 2024.09.15 |
| 이 함수형 인터페이스에는 추상메서드가 2개 이상인데요? (feat.Object) (1) | 2024.07.21 |