1. 트리거란?
RDB에서 특정 테이블에 이벤트(CREATE or UPDATE or DELETE)가 발생했을 때 수행할 작업들을 정의할 수 있는데, 이를 트리거라고 부릅니다. 즉 DB 테이블에 어떠한 변경이 일어날 때 이를 방아쇠(Trigger)삼아 미리 정의된 SQL 코드가 자동으로 실행되는 것으로 이해할 수 있습니다.
트리거는 실행 시점을 기준으로 크게 다음과 같이 2종류로 구분할 수 있습니다.
1) BEFORE 트리거
UPDATE, INSERT, DELETE 실행 전에 실행되는 트리거입니다. 애플리케이션으로부터 온 잘못된 요청을 거부하는 방식으로 활용 가능하며, UPDATE와 INSERT의 경우 실제 값이 수정/삭제되기 전 그 값을 가공할 수도 있습니다.
2) AFTER 트리거
UPDATE, INSERT, DELETE 실행 후에 실행되는 트리거입니다. 주로 변경된 데이터를 기반으로 다른 테이블을 업데이트하는 후속 조치를 남기는 식으로 많이 활용합니다.
참고) BEFORE 트리거든 AFTER 트리거든, 트리거에 정의된 작업들은 트리거를 실행시킨 작업과 같은 트랜잭션에서 수행됩니다. 즉 트리거가 실패하면 트리거를 실행시킨 작업도 실패합니다. (https://dev.mysql.com/doc/refman/8.0/en/trigger-syntax.html)
만약 트리거를 적용 범위 수준으로 구분하면 다음과 같이 2종류로 구분 가능합니다.
1) Row-level 트리거
이벤트가 발생된 행별로 수행되는 트리거입니다. 예를 들어 UPDATE절에 의해 10개의 행이 바뀌면, 이 트리거는 10번 실행됩니다.
2) Statement-level 트리거
변경된 행 수에 관련없이 조작되는 전체 문장(statement)단위로 실행되는 트리거입니다. 전체 배치 작업 전/후 하나의 로직만 실행하면 되는 경우 등에 사용할 수 있습니다. (MySQL의 경우 지원하지 않습니다)
참고) SQL Server나 Oracle의 경우 DDL에도 트리거를 만들 수 있습니다.
2. 트리거 생성 방법 (MySQL 기준)
트리거 생성은 CREATE TRIGGER를 통해 수행할 수 있고, 해당 테이블에 대한 Trigger 권한이 필요합니다. 세부적인 생성 문법은 다음과 같습니다.
-- 대괄호는 Optional을 의미합니다.
CREATE
[DEFINER = user]
TRIGGER [IF NOT EXISTS] trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
-- 각 필드
-- 1. trigger_time: { BEFORE | AFTER }
-- 2. trigger_event: { INSERT | UPDATE | DELETE }
-- 3. trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
- DEFINER : 트리거 정의자를 어떤 계정으로 할 것인지 지정합니다. 트리거는 실행되면 트리거를 실행시킨 계정의 권한이 아니라 트리거를 정의한 사람의 권한으로 실행되는데, 그때의 트리거 정의자 계정을 지정하는 것으로 이해할 수 있습니다. 이 필드를 따로 작성하지 않으면 트리거를 생성한 사람이 자동으로 DEFINER가 됩니다. DEFINER로 지정되는 계정에는 해당 테이블(트리거가 붙는 테이블)에 대한 TRIGGER 권한이 필요하며, trigger_body에서 참조되는 테이블들에는 TRIGGER 권한은 필요없으나 적절한 DML 권한이 필요합니다.
- trigger_name : 트리거의 이름으로, 같은 스키마 내에서 트리거 이름은 유일해야 합니다.
- trigger_time : 트리거의 실행시점을 지정합니다.
- trigger_event : 트리거를 발생시킬 이벤트 종류를 지정합니다.
- trigger_order : 같은 테이블의 동일한 이벤트에 대한 트리거가 여러 개일때, 각각의 실행 순서를 지정합니다. FOLLOWS 사용시 지정한 트리거 실행 후에 실행되고, PRECEDES 사용시 지정한 트리거 실행 전에 실행됩니다. 참고로 MySQL 5.7버전부터만 동일 이벤트에 대한 복수의 트리거 정의가 가능합니다.
- trigger_body : 실행할 작업을 정의합니다. BEGIN ... END를 작성하면 여러 작업을 정의할 수 있습니다.
trigger_body에서는 OLD와 NEW라는 키워드를 통해 변경 전후의 데이터에 접근할 수 있습니다.
- OLD : UPDATE 또는 DELETE 문에서 변경/삭제 전의 기존 데이터를 가리킵니다. OLD.column_name을 통해 해당 데이터의 컬럼값에 접근할 수 있습니다.
- NEW: INSERT 또는 UPDATE 문에서 새로 추가되거나 변경될 행의 데이터를 가리킵니다. NEW.column_name을 통해 해당 데이터의 컬럼값에 접근할 수 있습니다.
UPDATE 문에서는 OLD & NEW를 둘 다 접근할 수 있는데, 당연히 BEFORE 트리거에서는 NEW만 수정 가능합니다.
위 내용들을 토대로 트리거 생성 예제를 보면 다음과 같습니다. employees 테이블에 있는 직원 연봉(salary)가 변경될 때마다 변경내용을 salary_audit 테이블에 기록하는 AFTER 트리거입니다.
-- 트리거 생성도 세미콜론으로 끝나는데, trigger_body 내에서 사용되는 세미콜론이 트리거 종료로 인식되는걸 방지
DELIMITER $$
CREATE DEFINER = 'admin_user'@'localhost'
TRIGGER after_salary_update
AFTER UPDATE ON employees
FOR EACH ROW
BEGIN
-- 연봉이 변경되었을 때만 로그를 남김
IF OLD.salary <> NEW.salary THEN
INSERT INTO salary_audit (emp_no, old_salary, new_salary, changed_by)
VALUES (OLD.emp_no, OLD.salary, NEW.salary, USER());
END IF;
END$$
DELIMITER ;
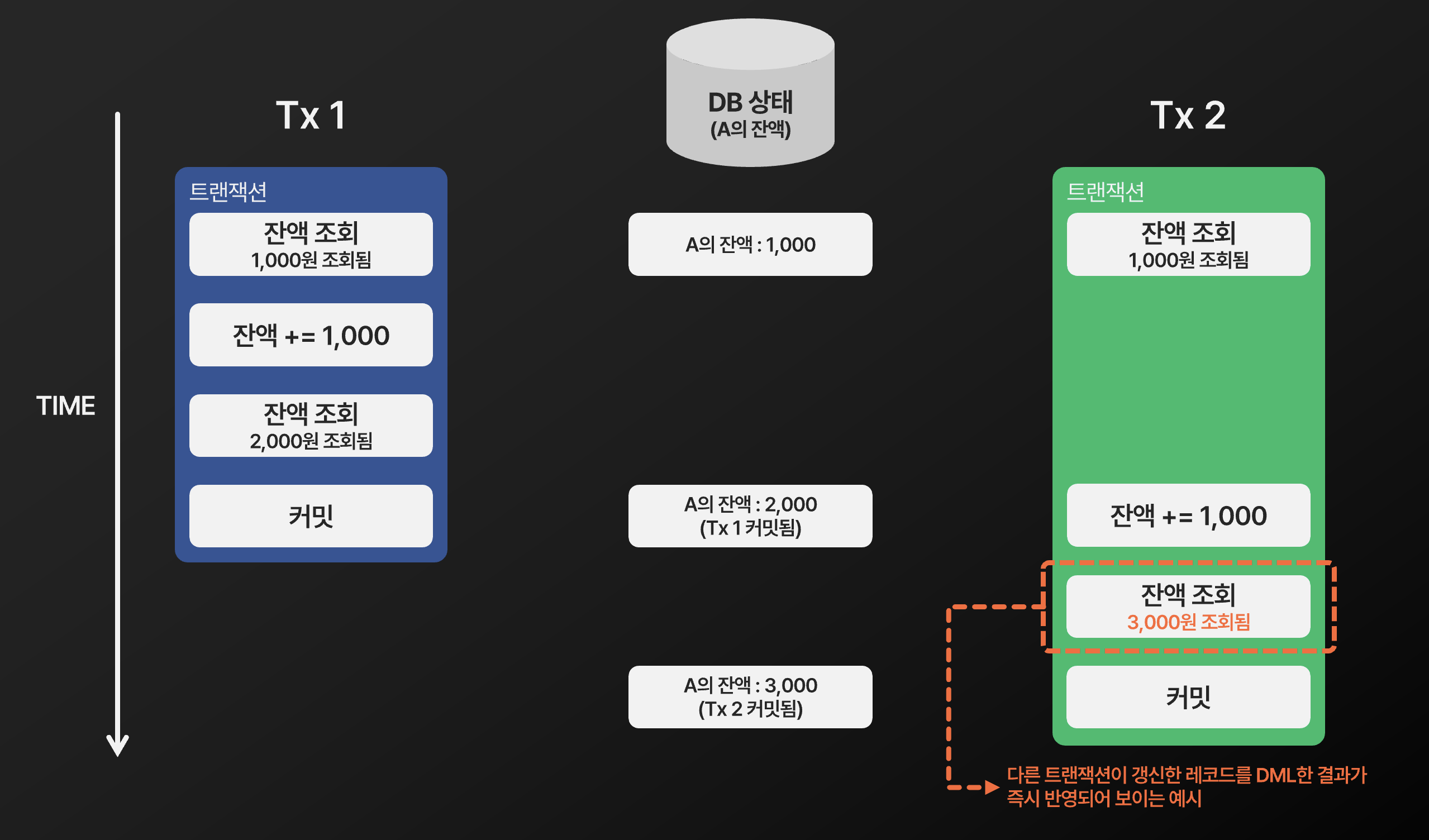
여기서 질문. USER()를 통해 변경을 실행한 DB 계정을 기록하는 건 알겠는데, 트리거를 실행시킨 DB 계정이 기록될까요 아니면 DEFINER로 정의된 DB계정이 기록될까요?
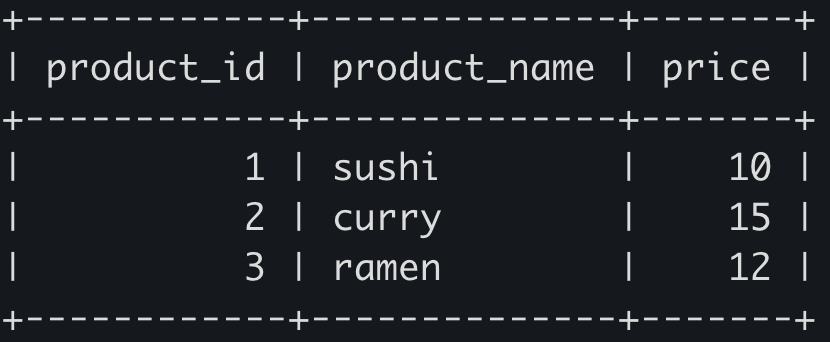
실제 예제를 통해 보겠습니다. 현재 employees 테이블에 다음과 같은 레코드가 있습니다.
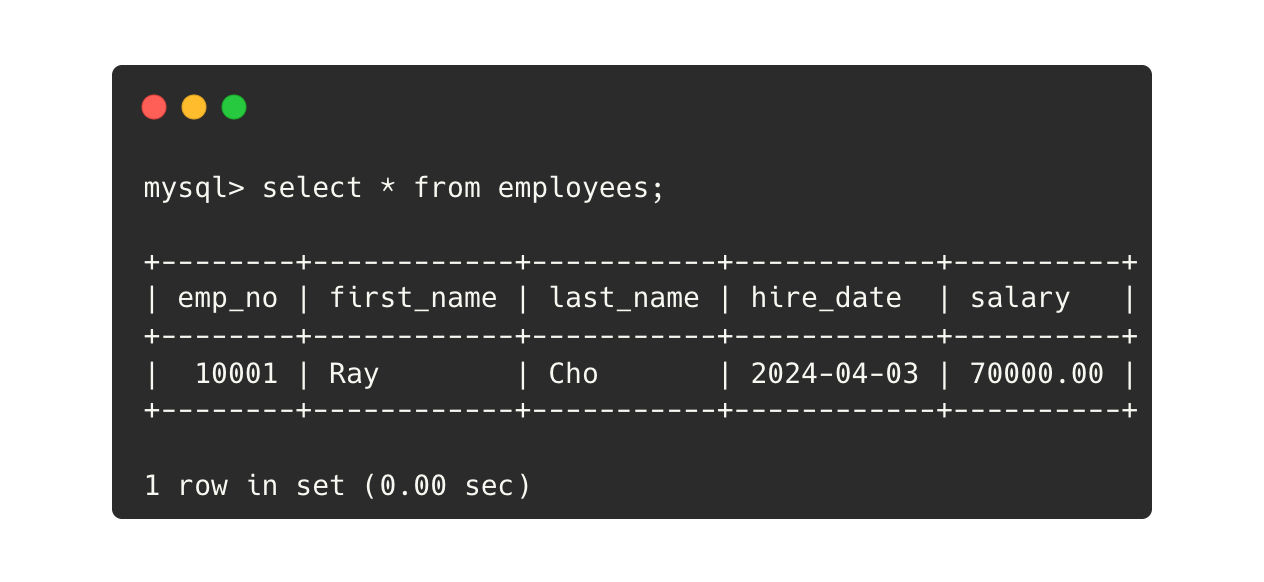
그리고 admin_user, app_user 계정을 만든 뒤 다음처럼 권한을 부여했습니다.
- admin_user
- employees 테이블에 대한 SELECT, TRIGGER 권한
- salary_audit 테이블에 대한 INSERT 권한
- app_user
- employees 테이블에 대한 SELECT, INSERT 권한
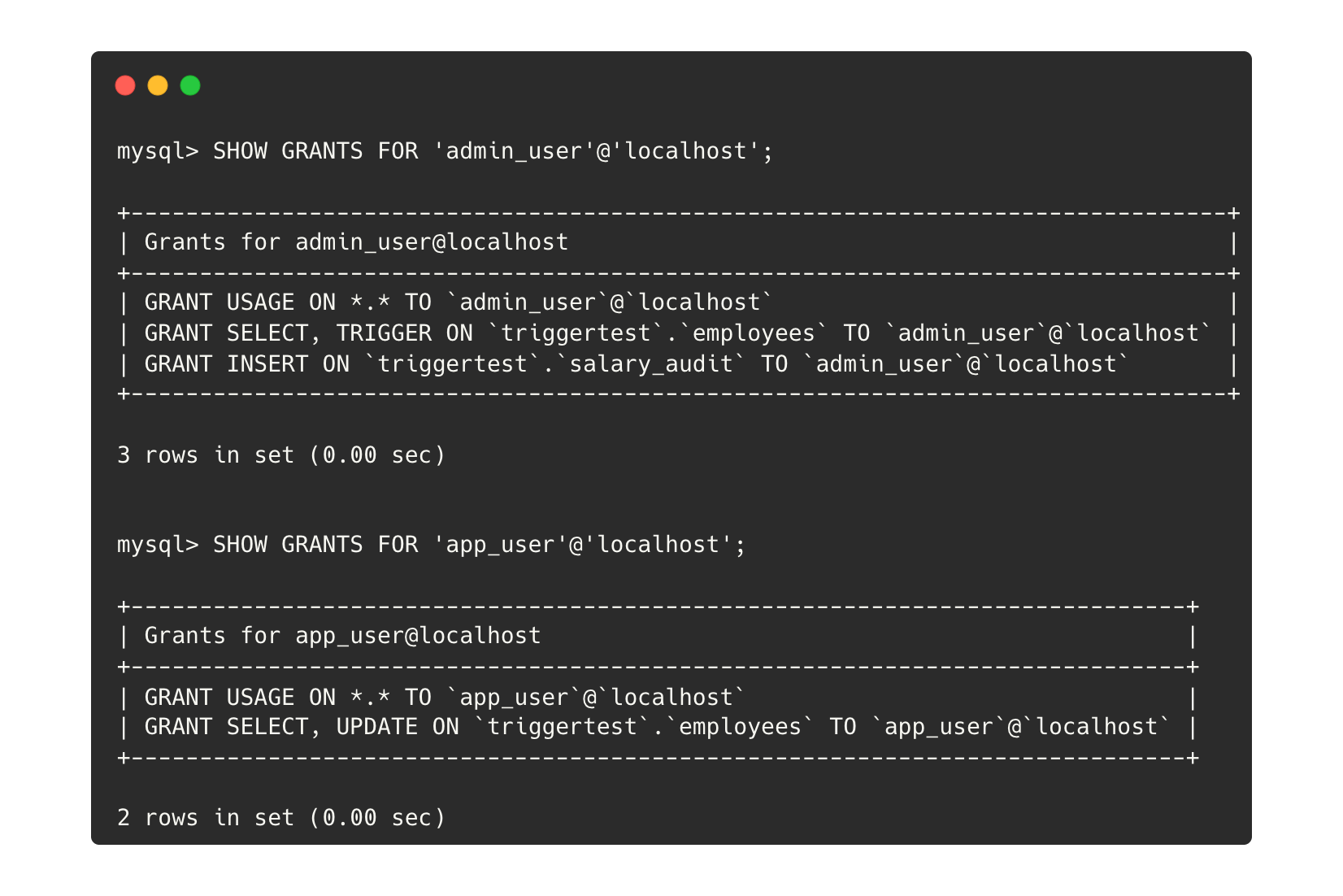
그리고 app_user 계정으로 접속하여 salary를 20000으로 바꿔주었습니다.
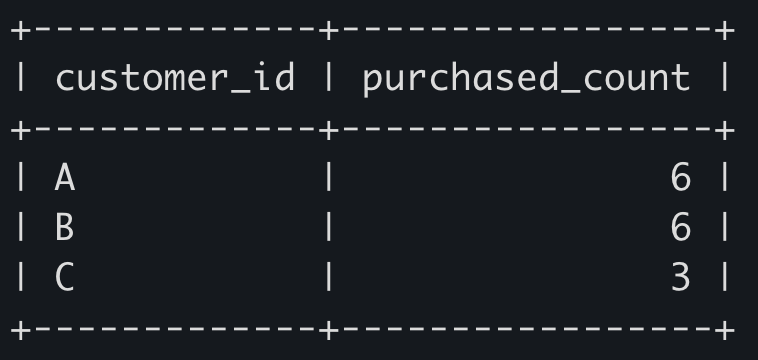
salary_audit 테이블에 적재된 결과는..
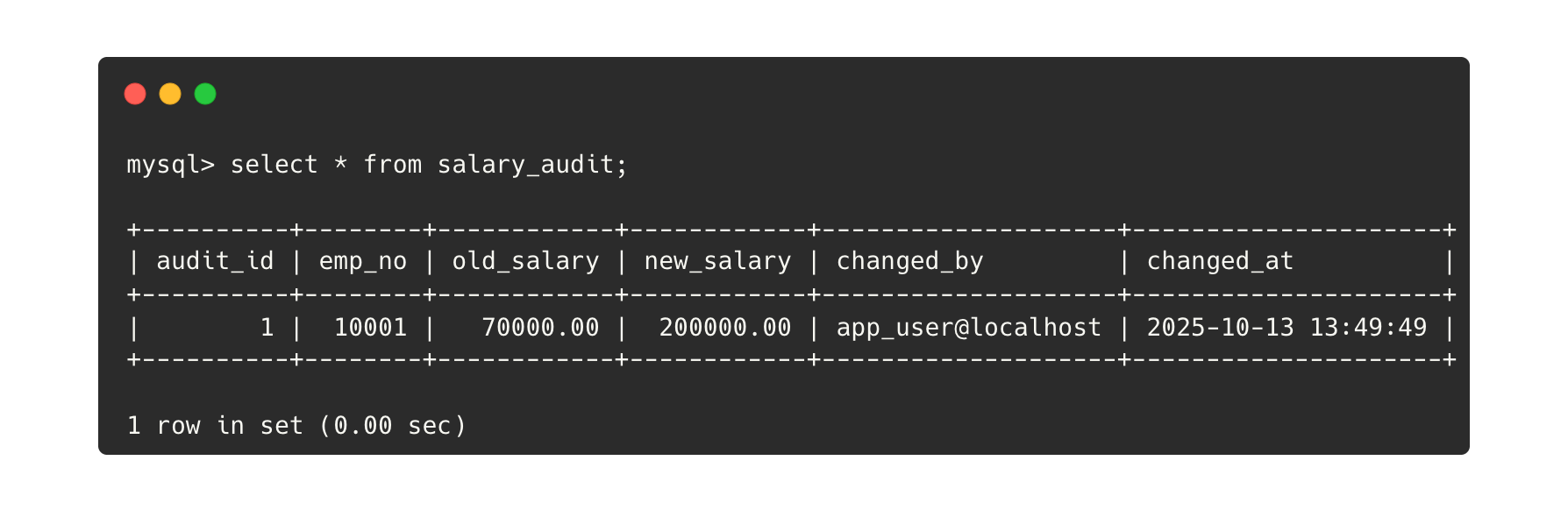
다음과 같이 트리거 정의자 계정이 아닌, 트리거를 실행시킨 DB 계정이 기록된 것을 볼 수 있었습니다.
사실 이 내용은 MySQL 공식 문서 내에서도 확인 가능합니다 (https://dev.mysql.com/doc/refman/8.0/en/create-trigger.html)
3. ⭐️ 어디에, 그리고 왜 트리거를 쓸까
우선 트리거는 특정 테이블에 이벤트가 발생됐을 때 수행하고 싶은 기능을 자동화하는 것으로 볼 수 있습니다. 애플리케이션에서 반복 작성해야 할 로직을 트리거를 쓰면 한 번만 구현하면 되고, 중요한 데이터에 대한 감사 로깅이 필요한 경우 트리거를 통해 별도의 로그 테이블에 자동으로 기록하게 하거나, 유저 테이블의 회원 상태가 '탈퇴'로 변경됐을 때 관련된 게시판 테이블의 게시물 상태들을 '비공개'로 변경하는 작업 등에 활용 가능합니다. 외부로의 이벤트/메시지 전파를 위해 같은 트랜잭션 내에서 비즈니스 테이블에 데이터를 연동하고 outbox 테이블에 발행할 이벤트를 적재하는 '트랜잭셔널 아웃박스 패턴'의 구현 방법으로 트리거를 채택할 수도 있습니다.
하지만 단순히 '자동화'를 넘어서 트리거의 핵심 역할을 DB 스스로가 데이터의 정합성과 일관성을 유지하도록 강제하는 것으로 바라볼 수 있습니다. 장애라고 하는 것은 트래픽으로 인해서 뿐만 아니라 여러 원인으로 인해 논리적으로 잘못된 형태의 데이터가 적재되면서도 발생할 수 있는데요. 물론 개발자가 애플리케이션 레벨에서 최대한 조심하며 개발할 수 있겠지만 결국 개발자 스스로도 휴먼 에러를 낼 수 있고(예상치 못하게 로직이 꼬인다든가.. 등) 이로 인해 잘못된 데이터가 들어올 수 있습니다. 물론 테이블에 CHECK 등의 제약 조건을 붙이며 최대한 데이터 무결성을 지킬 순 있겠으나, 'VIP 단계의 고객이 주문한 아이템들의 총액은 10,000원을 넘어야 한다' 등의 복잡한 비즈니스 제약들을 표현하고 지키기는 힘듭니다.
이럴 때 트리거를 사용해서 복잡한 데이터의 유효성 검사를 담당하게 할 수 있고, 단순 참조 무결성을 넘어서 복잡한 비즈니스 제약을 DB 스스로가 지키도록 강제할 수 있습니다. 또한 트리거 정의시 작성하는 DEFINER 계정에만 A 테이블에 대한 권한을 준다면, 해당 트리거 실행을 제외하고는 A 테이블에 데이터가 넣어질 수 없도록 아예 틀어막아 버릴 수도 있습니다. (개발자 실수 등이 생겨도 잘못된 데이터가 들어가는 일 자체가 안 생기게 됨)
그렇다고 트리거가 늘 좋냐!고 하면 당연히 아닙니다. 다음과 같은 단점들이 있습니다.
1) 성능 저하
애플리케이션에서 실행한 DB 작업 외에도 트리거를 통한 부가 작업이 수행되는 만큼, 성능 저하가 발생됩니다. 특히 MySQL은 Row-level 트리거이므로 1,000개의 행이 갱신되면 트리거가 1,000번 실행되므로.. 만약 트리거가 부착된 테이블의 변경이 잦다면 그만큼 성능 오버헤드도 비례해서 올라갑니다.
2) 불투명성
"A 테이블에 데이터를 넣으면 B 테이블에도 데이터를 추가한다" 라는 비즈니스 로직이 있다고 가정해보겠습니다. 이 비즈니스 로직이 애플리케이션 레벨에서 우리에게 친숙한 자바 코드 등으로 작성되어 있다면 처음 서비스를 접하는 개발자도 이런 로직이 있다고 쉽게 파악할 수 있습니다. 하지만 트리거를 통해 DB 레벨에서 이 비즈니스 로직이 구현되어 있다면, 개발자가 이런 비즈니스 로직이 있다고 인지하기도 어려울 뿐더러 문제 발생 시 디버깅도 어렵게 됩니다. 더 나아가 한 테이블에 부착된 트리거들이 FOLLOWS 등을 통해 여러 선후행 관계를 가진다면 골치가 더 아파지게 됩니다.
3) 작동 확인 방법의 번거로움
트리거는 작동을 확인하기 위해 명시적으로 실행해볼 수 있는 방법이 없어서, 잘 동작하는지 확인하려면 직접 부착된 테이블에 INSERT나 UPDATE, DELETE를 해줘야 합니다.
트리거 사용의 장단점을 표로 정리하면 다음과 같습니다.
| 장점 | 단점 |
| 1. 강력한 데이터 무결성 보장이 가능 2. 관련 작업을 자동화하여 개발 편의성 증가 3. 비즈니스 로직의 중앙화 (여러 앱이 같은 DB를 공유시, 모두에게 같은 규칙을 적용) |
1. 성능 저하 유발 가능 2. 비즈니스 로직이 드러나지 않게 됨 3. 디버깅 복잡도 증가 4. 작동 확인을 위해 명시적으로 실행하는 방법이 부재 |
그러면 트리거는 어떤 상황에 쓰면 좋고 어떤 상황에는 안 쓰는게 좋을까요? 개인적으로 생각해본 건 다음과 같습니다.
- 써도 괜찮을 때
- DB에 직접 접근해서 데이터를 수동으로 수정하는 경우가 많아, 휴먼 에러를 방지하고 데이터 무결성을 반드시 지켜주고 싶을 때 (앞서 말한 것처럼 DEFINER로 작성하는 계정에만 특정 테이블에 대한 권한을 주는 식으로 등..)
- 여러 애플리케이션이 하나의 DB를 공유하고 있어서 모두에게 동일한 규칙을 강제하고 싶을 때
- 쓰면 안 좋을 때
- 트리거를 부착하고 싶은 테이블의 데이터 변경이 잦아서 성능 저하가 예상될 때 (MySQL은 특히나 Row-level 트리거이므로)
- 비즈니스 로직이 자주 변경될 때 (대부분의 경우 애플리케이션 코드를 수정하는게 더 쉬울 것 같습니다)
- 서비스의 로직을 애플리케이션에서만 관리하는게 좋다고 판단될 때
4. 알아두면 좋은 트리거 주의사항
- "INSERT INTO ... ON DUPLICATE SET" 는 중복이 없다면 BEFORE INSERT와 AFTER INSERT 이벤트를 발생시키고, 중복이 있다면 BEFORE UPDATE와 AFTER UPDATE 이벤트를 발생시킵니다.
- 테이블에 외래키 관계에 의해 자동으로 변경된 경우는 트리거가 호출되지 않습니다.
- 트리거 작성 시 BEGIN .. END 블록 내에서는 ROLLBACK / COMMIT 등 트랜잭션을 명시적으로 시작하거나 종료하는 SQL 문장을 작성할 수 없습니다.
- mysql과 information_schema, performance_schema 데이터베이스에 존재하는 테이블들에는 트리거를 생성할 수 없습니다.
5. 레퍼런스
https://dev.mysql.com/doc/refman/8.4/en/trigger-syntax.html
https://dev.mysql.com/doc/refman/8.4/en/create-trigger.html
https://www.ibm.com/docs/en/ias?topic=triggers-types
'DB > MySQL' 카테고리의 다른 글
| 어설프게 알면 당신도 낚인다. MySQL REPEATABLE_READ의 함정 (1) | 2025.06.10 |
|---|---|
| [MySQL] WITH ROLLUP을 활용한 그룹별 중간 집계 산출법 (0) | 2024.03.03 |
| MySQL에서 데이터를 scan하는 대표적인 방법들 (feat. InnoDB 클러스터링 인덱스) (1) | 2024.02.18 |
| PARTITION BY와 GROUP BY의 차이점 (1) | 2024.01.06 |
| mysqldump를 활용한 DB 백업 (1) | 2023.11.26 |