HTTPS : Http + Secure. 기존의 HTTP에 "안전"을 더한 형태. 그럼 뭘 안전하게 하는 것인가? 크게 2가지로 볼 수 있다
내가 사이트에 보내는 정보들을 제 3자가 못 보게 한다
내가 접속하는 사이트가 신뢰할 수 있는 사이트인지 알려준다
그러면 이 두 가지 내용이 어떤 원리로 구현되는가?
1은 비대칭키를 사용한 암호화로 가능하다. 서버가 가진 "공개키"로 암호화해서 보내면, 해당 암호문은 "개인키"를 가진 서버만이 해독 가능하다. 따라서 제 3자가 내가 보내는 트래픽을 엿봐도 해독(복호화)할 수 없다. (제 3자도 서버의 공개키를 알 수는 있겠지만, 비대칭키의 특성상 공개키로 암호화한 내용을 공개키로 복호화할 수 없기 때문)
2도 마찬가지로 비대칭키 특성을 통해 가능하다. 서버에서 보내는 정보는 서버의 "개인키"로 일부가 암호화돼있다. 그러나 내가 가진 서버의 "공개키"로는 오직 해당 서버의 "개인키"로 암호화한 것만 복호화가 가능하다. 즉 해당 서버가 아닌 다른 서버에서 온 내용은 내가 가진 공개키로는 복호화가 안 된다는 거다. 이 때 신뢰가능한, 즉 공인된 특정 기관에서 내가 가진 공개키가 해당 서버의 공개키가 맞다는 인증만 받는다면 해당 서버를 신뢰할 수 있게 되는 것.
그럼 프로그래머의 영역에서, HTTPS는 실제로 어떻게 구현될까?
우선 jofe라는 사이트가 공개키들을 뿌렸다고 가정하자. 난 이 공개키가 jofe란 사이트의 공개키인지(즉 정품인지)를 확인할 수 있어야 한다. 이를 인증해주는(보장해주는) 공인된 기관들이 존재하며, 이들을 CA(Certificate Authority)라고 부른다. 우리가 사용중인 브라우저들엔 이 CA들의 목록이 저장돼있다.
이런 상황에서, 내(client)가 jofe(server)에 접속할려고 한다. 랜덤한 데이터나 만들어서 서버에게 주면, 서버는 그에 대한 답변으로 랜덤한 데이터와 "CA에서 발급해준 해당 서버의 인증서"를 만들어서 내게 준다. (클라이언트 서버가 악수했다고 표현)
그럼 클라이언트는 해당 인증서가 진품인지를 판단하는데, 이 때 브라우저에 내장된 CA들의 정보를 통해 확인한다. CA의 인증을 받은 인증서들은 해당 CA의 개인키로 암호화돼있기 때문에 그 CA의 공개키로 복호화가 가능하다. 즉 받은 인증서가 진품이라면 브라우저에 있는 C의 공개키로 해당 인증서를 복호화 가능한 것이다.
성공적으로 복호화된 인증서에는 인증서를 보낸 서버(jofe)의 "공개키"가 들어있다. 하지만 그렇다고 이제부터 바로 내가 서버로 보낼 메시지들을 공개키로 암호화해서 보낼 수 있는 건 아니다. 왜냐하면 비대칭키는 대칭키 방식보다 컴퓨터에 주는 부담이 크기 때문. (주고받을 다량의 데이터를 하나하나 비대칭키로 암호화하는 건 부담이 된다는 것)
따라서 주고받을 데이터를 "대칭키"로 암호화한다. 대칭키를 사용하는 경우의 가장 큰 단점은 양쪽이 똑같은 키를 가져야 하므로 어쨌거나 한 번은 서로 통신을 해서 키를 주고받아야 하는데, 이 때 탈취당할 위험이 있다는 거다. 이 때 클라이언트는 아까 악수할 때 만들어진 데이터들을 이용해 임의의 대칭키를 만든 다음, 서버로 이를 공유할 때 "비대칭키"를 사용한다. 즉 서버의 "공개키"로 임의로 만든 대칭키를 암호화하여 보낸다는 말. 서버는 이를 자신의 "개인키"로 복호화하여 클라이언트가 만든 대칭키를 그대로 쓸 수 있게 되는 거고, 이제 양쪽이 서로 대칭키를 갖게 됐으니 이를 통해 서로 데이터들을 암호화하여 통신할 수 있게 된다.
그림으로 나타내면 다음과 같다
우선 클라이언트가 랜덤한 데이터를 만들어 서버로 보낸다
그러면 서버도 랜덤한 데이터와 함께 CA에서 발급해준 인증서를 보낸다(이 인증서는 해당 CA의 개인키로 암호화돼있다)
클라이언트는 브라우저에 내장된 CA목록들을 통해 해당 CA의 공개키로 인증서를 복호화한다. 어떤 공개키로도 복호화가 안되면 당연히 서버 쪽을 신뢰할 수 없는 거고, 복호화됐다면 인증서를 보낸 서버를 공인된 서버라고 신뢰할 수 있게 된다.
또한 해당 인증서는 서버의 공개키를 가지고 있어서, 복호화에 성공했다면 요로코롬 서버의 공개키를 얻게 되는 거다.
이제 클라이언트는 아까 만들었던 클라이언트쪽의 랜덤데이터와 서버로부터 받은 서버쪽 랜덤데이터를 활용해 대칭키를 만들고, 이를 인증서에 들어있던 서버의 공개키로 암호화하여 서버에게 보낸다.
서버는 이를 자신의 개인키로 복호화할 수 있고, 이를 통해 클라이언트와 서버가 동일한 대칭키를 갖게 되는 것이며 이를 통해 데이터를 서로 암호화하고 복호화하며 통신할 수 있게 된다.
우리가 만든 서비스가 유저를 대신해서 구글에서 제공하는 서비스에 뭔가를 하고 싶은 일들이 생겼던 거다. 가령 구글 캘린더에 일정등록을 우리가 만든 서비스가 해준다든가, 등등.. 이를 위해서는 유저로부터 그가 사용하는 구글에 대해 접근할 수 있다는 허락을 받아야 한다.
가장 쉬운 방법은 당연히 유저로부터 구글ID와 PW를 받는 것. 우리가 만든 서비스가 유저가 준 ID, PW를 기억하면서 적재적소에 써먹으면 된다. 상당히 쉽고 강력한 방법이다.
하지만 당연히 이걸 실제로 써먹을 수는 없다. 유저입장에선 우리가 만든 서비스를 신뢰할 수 없을 것이며, 구글 입장에서도 유저가 아니라 제 3자인 우리 앱이 유저의 ID와 PW를 가지게 되니 여간 골치아픈게 아니다. 결국 보안적으로 가당치도 않은 상황이 된다.
이런 문제에 대한 해결책으로 등장한 것이 본 포스트에서 다룰 OAuth다.
OAuth?
Open Authorization의 줄임말. 사용자(user)와 구글과 같은 플랫폼 사이에서 제 3자에 해당하는 우리의 서비스가 해당 플랫폼에 있는 사용자의 데이터에 접근할 수 있는 권한을 위임받을 수 있는 표준 프로토콜이다. 이 프로토콜을 통해 사용자는 우리가 만드는 서비스에 ID, PW를 맡길(?) 필요가 없고, 구글 등에 있는 사용자의 데이터에 대해 접근할 수 있는 권한을 우리 서비스가 부여받을 수 있게 된다.
OAuth의 원리
한 문장으로 요약하자면
사용자의 요청을 통해 구글이 access token을 발급해주고, 그 토큰을 통해서 우리가 구글에 존재하는 사용자의 데이터에 접근이 가능해지는 것
이다. 이제 이 페이지를 닫으셔도 됩니다
좀만 더 원리를 디테일하게 설명하기 전, 용어 정리를 한 번 하고 가야 한다.
Resouce Owner
우리가 만든 서비스를 이용하면서 구글 등에 데이터를 가지고 있는 사람. 즉 사용자를 말한다
Resouce Server
구글과 같이 사용자의 리소스를 가지고 있는 서버, 즉 우리가 만든 서비스가 제어하고자 하는 리소스를 가지고 있는 애를 말한다. 인증 관련된 서버와 자원 관련된 서버로 구분하기 위해 Authorization Server와 Resource Server 2개로 분리하기도 하는데, 본 포스트에선 Resource Server 하나로 뭉탕치도록(?) 하겠다.
Client
Resource Server의 리소스를 이용하고자 하는 서비스. 즉 우리가 만든 서비스를 말한다
그럼 이제 본격적으로 OAuth의 동작순서 및 원리에 대해 좀 더 알아보자.
동작순서는 다음과 같다
Resource Owner(사용자)가 Client(우리가 만든 서비스)의 [구글 계정으로 로그인] 과 같은 버튼을 누른다
Client는 이를 접수(?)하고 Resource Server(구글 등)에게 전달
Resource Server는 Resource Owner에게 로그인 페이지를 보여주고, Resource Owner가 로그인한다
Resouce Server는 인증이 성공되면 Resource Owner에게 Client가 특정 리소스에 접근해도 되냐는 질의를 한다
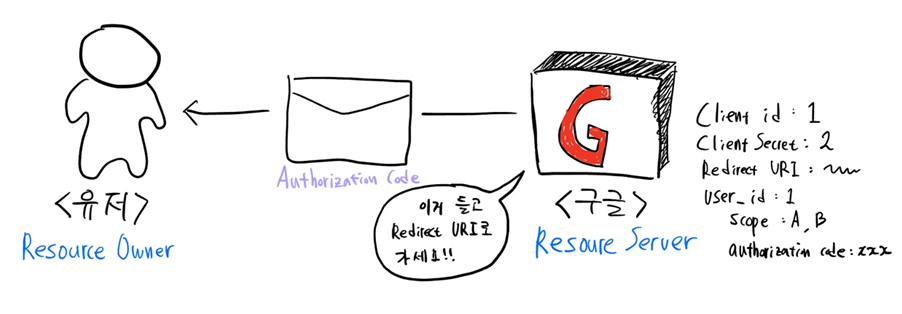
Resouce Owner가 허락한다면, Resouce Owner가 Authorization code를 Resource Owner에게 전달하면서 Resource Owner를 사전에 약속(Client와 Resource Server가 사전에 약속한 것임)된 Redirect URI로 리다이렉트시킴 (Authorization code: 일종의 임시 암호)
이를 통해 Client도 Resouce Owner가 Resource Server로부터 전달받은 Authorization code를 알게 됨
Client는 사전에 Resource Server와 합의해서 가지고 있던 client secret이란 걸 가지고 있음. 이걸 Authorization code와 함께 Resource Server에게 전달.
Resoruce Server가 이에 대한 인증이 끝나면, Client에게 access token(허가증)을 발급!
이후 Client는 Resource Server에 존재하는 Resource Owner의 리소스에 접근할 때는 아까 받았던 access token을 활용
그럼 각 단계를 좀 더 뜯어보자. 그 전에, 위 순서에서 보면 사전에 약속된, 합의된 이런 말이 나온다. 그것도 포함해서 각 단계를 뜯어보자.
0. 일단 우리가 만든 서비스를 등록
우선 Client, 즉 우리가 만드는 서비스가 구글 즉 Resource Server를 이용하기 위해선 Resource Server에 우리가 널 쓸거라고 사전에 등록을 해야 한다. 이 방법은 구글, 카카오, 애플 등 플랫폼별로 조금씩 다르다.
플랫폼 별로 방법이야 당연히 다른데 공통적으로 수행하는 작업이 있다. 바로 Redirection URI를 등록하는 것! 이 URI는 구글과 같은 플랫폼이 인증이 성공한 사용자(구글로 로그인을 눌러서 자신의 구글 계정으로 로그인한..위 순서에서 3 ~ 5번 참조)를 리다이렉트 즉 이동시킬 URI다. 위 순서에서 알 수 있듯, 이는 Resource Server로부터 Authorization code를 받은 Resource Owner가 오게 되는 URI다. (CallBack URL로도 부르는 듯)
(음 내가 이해한 대로 설명하자면..유저한테 "유저야, 우리 서비스를 통해 구글에 접근하고 싶지? 그럼 너가 구글에 들러서 걔네한테 받은 임시 허가증을 우리 집 창문으로 들고 와!" 라고 하는 상황이다. 구글이 Resource Server고, 임시 허가증이 Authorization Code다. 그리고 우리 집 창문이 Redirect URI, 즉 사용자가 구글에서 임시 허가증을 받은 뒤 와야 하는 "지정된 장소"인 것. 근데 구글이 친절하게도 직접 택시를 태워서 사용자를 우리 집 창문 앞으로 보내주는 것, 즉 리다이렉트 시켜주는 거다)
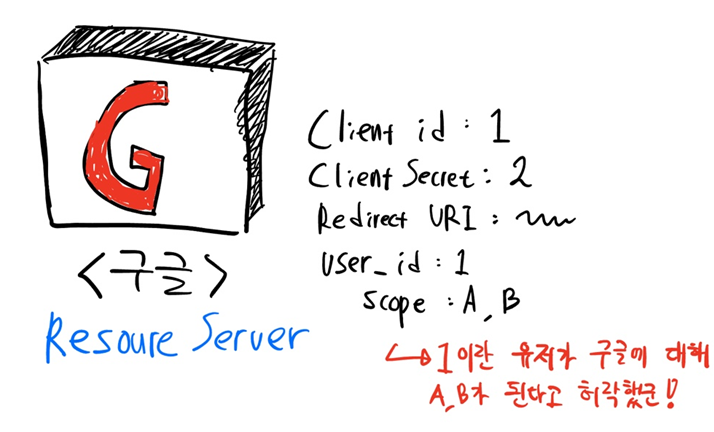
암튼 이렇게 등록이 끝나면 Client Id와 Client Secret(위 순서에서 7번을 참조)를 발급받는다.
Client Id : 등록된 우리 서비스를 Resource Server가 식별할 수 있는 식별자.
Client Secret : Client Id에 대한 비밀번호. 외부에 노출되면 절대 안 된다
즉 이런 등록과정, 즉 사전협의를 통해 client와 resource server는 client id 및 client secret, 그리고 redirect uri를 아는 상태에서 시작한다.
1. Resource Owner가 Client의 [구글 계정으로 로그인] 과 같은 버튼을 누른다
걍 이거 말하는 거임
ChatGPT 로그인 화면
여기서 구글로 로그인 이런걸 유저가 누른다는 말!
2. Client가 이를 Resource Server로 전달
이때 전달하는 주소는 다음과 같은 형식이다 (물론 플랫폼 별로 조금씩 차이가 있을 수도..?)
아까 사전 협의를 통해 Client가 Client Id와 Redirect URI를 알고 있음을 상기하자. scope는 client가 resource server로부터 인가받을 권한의 범위를 말한다고 생각하면 된다(구글의 모든 리소스에 접근할 수 있는 것보단 딱 필요한 것에만 접근할 수 있게끔 하는 것이 당연히 좋다)
3. Resource Server가 로그인 페이지를 보여주고 Resource Owner가 로그인한다
인증이 성공(즉 Resource Owner가 로그인에 성공하면)하면, Resource Server는 쿼리스트링 형식으로 넘어온 파라미터들을 보며 Client가 본인이 아는 그 놈이 맞는지 검사한다(즉 사전에 협의된 녀석이 맞는지 검사). Resource Server 역시 Client Id와 Redirect URI를 알고 있음을 다시 한 번 상기하자.
검사하는 내용은,
파라미터로 전달된 client id값과 동일한 값을 내가(Resource Server가) 가지고 있는가?
가지고 있다면 그에 대한 redirect uri가 파라미터로 전달된 redirect uri와 동일한가?
이렇게 검사한 후에, 특정 리소스들에 접근해도 되냐는 질의를 하는데 그건 이런 거 말하는 거임
특정 리소스들에 대한 접근 질의에 Resource Owner가 허락한다면, Resource Server는 해당 Client Id에 대해 특정 user_id를 갖는 Resource Owner가 특정 scope에 대한 행동을 허가했다는 사실을 기록한다. (즉 특정 유저가 우리 서비스에 대해 A, B라는 행동을 해도 된다고 허락했다는 것을 기억하는 것)
그 후, Resource Owner에게 Authorization code라는 임시 암호를 발급해주면서 어떤 uesr에게 해당 Authorization code를 발급했는지 기록한다. 그와 동시에, 사전에 합의했던 Redirect URI로 Resource Owner를 리다이렉트시킨다.
6. 이를 통해 Client도 Resource Owner가 Resource Server로부터 발급받은 Authorization Code를 알게 됨
별도의 부연설명은 생략
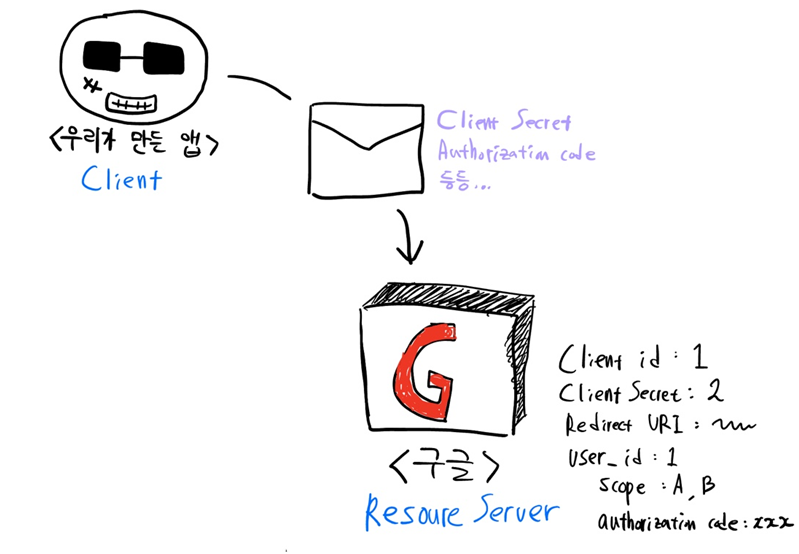
7. Client는 사전에 합의한 후 받았던 Client Secret과 함께 Authorization code를 Resource Server에게 전달
redrection_uri : 사전에 합의한 바로 그 redirection_uri 넣으면 됨
client_id : 사전에 합의하고 받은 바로 그 client id 넣으면 됨
client_secret : 사전에 합의하고 받은 바로 그 client secret 넣으면 됨
8. Resource Server가 이에 대한 인증이 끝나면, Client에게 access token을 발급함
Resource Server는 Client에게 전달받은 code(= authorization code)값과 자신이 아까 기록한(5번 참조) Authorization code를 대조하며 인증을 함. 이 과정이 성공적으로 끝나면, Resource Server는 아까 자신이 기록했던 Authorization code를 지우고 Client에게 Access Token을 발급하며 해당 토큰을 어떤 user_id에게 발급했는지를 기록한다.
9. 이후 Client는 발급받은 Access token을 이용해 활용
자세한 설명은 생략한다.
참고로, Refresh token을 발급해주기도 한다고 한다. Access token이 만료되면 Refresh token을 통해서 Access token을 재발급받는 것.
요즘 들어 많이 마주치는 단어 중 하나는 DI, Dependency Injection이다. 말 그대로 번역하면 "의존성 주입"이고, 좀 더 풀어서 해석하면 "의존관계를 외부에서 넣어주는"이라는 문장이 된다. 책이나 강의를 통한 예제를 통해서는 단순히 어떤 객체가 가지는 멤버변수가 있을 때, 자신 스스로 멤버변수를 만들어서 설정하는게 아니라 외부에서 이미 만들어진 녀석을 갖고 와서 쓰는 느낌으로만 알고 있었다. 그러나 DI를 나 스스로가 정말 무엇을 말하는지 알고 있는가?라고 물으면..음 글쎄다.
public class MemberService {
private final MemberRepository memberRepository;
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
}
내가 아는 DI는 단순히 이렇게 "외부에서 만들어진 녀석을 내부로 갖고 와서 쓰게 해주는 것" 이다
이번 기회에 의존성 관계가 뭔지 확실히 정리해보자.
의존성(의존 관계)란
public class MemberService {
private final MemberRepository memberRepository;
}
MemberService가 멤버변수로 MemberRepository를 가지는 모습이다. MemberService의 메서드들은 MemberRepository라는 멤버변수를 다루는 행동들을 할 것이다. 당연하게도, MemberRepository라는 놈이 변하면 그에 따라 MemberRepository를 다루는 MemberService에게도 영향이 미칠 것이다. 때문에 이런 관계에서, "MemberService는 MemberRepository에게 의존한다"라고 표현한다.
즉
MemberService가 MemberRepository를 가진다
→ 당연히 MemberService가 MemberRepository에 의한 영향을 받는다
→ MemberService가 MemberRepository에 의존한다
인 것이다. 하지만 나는 소프트웨어학과이므로 좀 더 추상적인 수준에서 "의존관계(의존성)"를 설명할 수 있어야 한다.
추상적은 수준에서의 "의존관계"란,
"두 객체 사이에서 한 객체가 변하면 다른 객체에게 영향이 가는 관계, 즉 변경에 의한 영향을 받는 관계"
라고 표현할 수 있을 것이다. 영향을 받는 객체가 영향을 발생시키는 객체를 의존한다고 표현하는 것이고. 구체적인 설명으로는 한 객체가 다른 객체의 메서드를 쓰는 관계, A가 B를 사용해야만 A의 역할을 수행할 수 있는 관계..라고도 볼 수 있다.
주입(Injection)이란
이건 단어 그대로 보면 된다. 외부에서 꽂아넣는거다.
public class MemberService {
private final JofeMemberRepository memberRepository;
public MemberService() {
this.memberRepository = new JofeMemberRepository();
}
}
위 코드는 JofeMemberRepository필드를 클래스 내부에서 스스로 찍어내고(?) 있다.
public class MemberService {
private final JofeMemberRepository memberRepository;
public MemberService(JofeMemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
}
위 코드는 생성자를 통해(setter메서드 등으로 하는 것도 상관없음) 외부에서 JofeMemberRepository를 받아와서 자신의 필드로 세팅하는 모습이다. 외부에서 가져온다 → 외부에서 "주입"한다.
이것을 주입이라고 하는 것이다.
근데 굳이 왜 주입하는거지? 어차피 내부에서 찍어내나 외부에서 주입하나 어차피 다른 거 없지 않아?
그것에 대한 답은 "역할을 분리하기 위해서"이다.
생성과 사용에 대한 관심을 분리하여 생성에 대한 책임은 다른 누군가에게 위임하고, 나는 사용하는 역할을 맡겠다는 것. 쉽게 말해서
"만드는 건 너가 해. 쓰는 건 내가 할게"
라는 거다. 또한 이렇게 책임을 짬때리는위임하는 동시에 필요에 따라 객체가 생성되는 방식을 선택할 수 있게 된다! 결국엔 의존하는 관계에서 가지던 일종의 강한 결합을 느슨하게 만들게 되고 이것을 통해 설계의 유연성을 가질 수 있기 때문에 굳이 주입하는 식으로 만드는 것.
이렇게 의존관계를 주입하는 것, 즉 외부에서 끼워넣는 것을 의존성 주입이라고 한다. 그러나! 이렇게 단순히 의존관계를 주입하는 것은 진정한 의존성 주입(DI)이 아니다.
(아니 의존관계를 주입하는 것을 의존성 주입이라고 부르지 않는다니,,이게 뭔말일까?)
즉 단순히 외부에서 만들어진 녀석을 내부로 가져온다고 해서 죄다 DI라고 하진 않는 것.
하나 더 알아둬야 할 것이 있다. 바로, 의존성 분리다.
의존성 분리란
앞서 설명했듯, 의존성(의존관계)란 변경에 의한 영향을 받는 관계를 말한다. 이것을 분리한다는 것은, 한마디로 변경에 의한 영향을 안 받게 하겠다! 라는 거다.
물론 A가 B에게 의존하는 관계에서 B가 b라는 메서드를 가지고 있다고 할 때, b메서드의 기능을 바꾼다고 하면 당연히 A에게도 영향이 간다. 여기서 말하고자 하는 영향은 이런 영향이 아니라, 바로 A가 이제부터는 B가 아니라 C라는 모듈을 사용하기로 변경한 경우를 의미한다고 보면 된다. 이 경우 A는 B를 사용하던 코드를 싹 다 바꿔야 한다.
이는 A와 B가 강하게 결합돼있기 때문에 발생한다. 다르게 표현하자면 A가 B를 강하게 의존하기 때문, 즉 A가 B를 너무나도 잘 알기 때문에(?) 발생한다. 둘의 의존관계의 끈끈한 정도가 상당히 센 것이다.(너 없음 난 아무것도 못해~의 느낌..)
의존성을 분리한다는 것은 이러한 관계를 끊어낸다는 것으로, 아예 손절친다는게 아니라 그 관계의 끈끈한 정도(?)를 느슨~하게 만든다는 의미다. (강한 결합 느슨한 결합이 되게 추상적인 표현이라고는 생각하는데, 이 말 말고 더 느낌있는 말이 없는 것 같다)
이에 대한 전통적인 예시로 연극팀 예시가 있다. 어떠한 배역이 있고 그 배역을 맡은 배우가 있을 때, 내가 연극팀을 운영하는 입장이라면 배우가 아니라 배역에 집중해서 기획을 해야 한다. 배우에 집중한다고 하면(이 경우가 강한 결합!!) 그 배우가 아파서 연극에 못 온다고 하면 그냥 망하는거다. 그러나 특정 배우가 아닌 배역에 집중한다면(이 경우가 느슨한 결합!!) 실제로 이 일을 맡은 배우가 누군지 몰라도 "이걸 누가 하는지는 모르겠는데, 이 역할 맡은 배우는 이렇게 연기하면 돼!"를 알고 있는 거니까 상관없는거다. 즉 배우가 바뀌거나 아프거나 뭐 그런 것에 영향을 받지 않게 되는 것.
연극팀 인원들이 원래는 배우에게 의존하는 관계를 더 이상 배우가 아니라 배역에게 의존함으로써, 연극팀과 배우간의 사이가 상당히 느슨해진다! 라고 표현가능하다. 이렇게 의존관계가 느슨해지는 것을 다른 관점에서 보면 연극팀이 배우가 아닌 배역에 의존함으로써 기존에 가지던 배우에게 의존하던 관계가 분리되기 때문에 "의존성이 분리된다"라고 볼 수 있는 거다.
이렇게 특정 구현체(배우)가 아니라 인터페이스(배역)에 의존함으로써 의존성 분리가 가능하다. 이를 "의존관계 역전 원칙(의존성 뒤집기 원칙, Dependency Inversion Principle)"을 적용함으로써 의존성을 분리한다고 표현한다.
의존관계 역전 원칙
일단 이름은 간지난다. 처음부터 직접적으로 와닿게 설명하자면 "구상 클래스가 아닌 추상 클래스에 의존하게 만드는" 원칙을 말한다. 조금 더 파헤치면, 고수준 모듈이 저수준 모듈에 의존하면 안 된다는 뜻이 담겨 있다.
구상 클래스가 아닌 추상 클래스에 의존하게 함으로써, 고수준 모듈가 저수준 모듈에게 의존하는 전통적인 의존관계를 뒤집히고 고수준 모듈이 저수준 모듈의 구현체들로부터 독립되게 할 수 있게 된다. 즉 의존성을 분리시킬 수 있다!
한마디로 저수준 모듈이 고수준 모듈에게 의존하도록 뒤집으라는건데..이걸 바로 구상 클래스가 아닌 추상 클래스에 의존하게 함으로써 뒤집으라는 얘기다.
원래 이랬던 거를이렇게 역전, 즉 뒤집으라는 거
※ 여기서 고수준/저수준은 프로그래밍 언어를 말할 때의 고수준(사람에 가까운)/저수준(컴퓨터에 가까운)과 같은 의미다. 고수준 모듈이 어떤 의미있는 기능을 제공하는 모듈이라 한다면, 저수준 모듈은 고수준 모듈의 그 기능을 구현하는 실제적인 역할을 맡는 애들이라고 보면 된다. MemberService의 기능이 실제적으론 MemberRepository의 기능들을 통해 이루어진다면 MemberService가 고수준, MemberRepository가 저수준이 된다. 반대로 MemberRepository의 메서드들은 실제적으로 그들을 구현하는 구현체(ex: JofeMemberRepository)에서 구현되므로 이들사이는 MemberRepository가 고수준, JofeMemberRepository가 저수준이 된다.
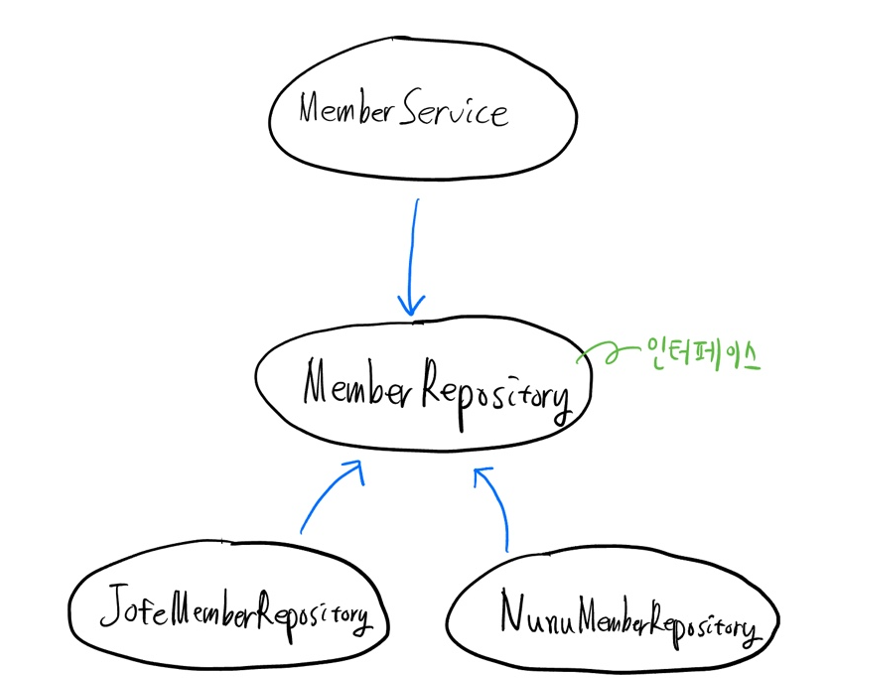
MemberService는 이제 추상화된 MemberRepository에만 의존한다. 뿐만 아니라 다양한 MemberRepository구현체들도 역시 추상화된 MemberRepositiry클래스에 의존하게 된다. MemberService입장에서는 MemberRepository가 저수준 모듈들이지만, 기존에 의존하던 JofeMemberRepository입장에서는 MemberRepository라는 추상 클래스가 자신보다 고수준이다. 왜냐하면 그 놈의 인터페이스를 실제로 구현하는 역할을 JofeMemberRepository가 하니까.
public class MemberService {
private final MemberRepository memberRepository;
public MemberService(MemberRepository concreteMemberRepository) {
this.memberRepository = concreteMemberRepository;
}
}
실제 memberRepository필드(= 배우)로 어떤 놈이 들어올지는(= 주입될지는) 모른다. 그래도 그 놈이 MemberRepository(= 배역)라는 역할을 맡은 것은 알고 있다. 때문에 실제 배우가 누가 되든 나는 상관없다.
이렇게 의존성 분리를 해주면서, 외부에서 의존관계를 주입받는 것. 이게 진정한 Dependency Injection이다. 단순히 외부에서 때려넣는다고 죄다 dependency injection이 아님!!
마지막으로 이 DI의 장점을 훑고 가면 다음과 같다.
의존성이 줄어든다 : 의존성 분리를 해줬기 때문에, 의존대상이 바뀌어도 그로 인한 코드의 수정을 안 해도 된다. 즉 배우가 아닌 배역에 의존하니까 배우로 누가 들어오든 변하는 건 없다. 어차피 얘가 할 일은 정해져있으니까. 변경에 유연해진다고도 표현할 수 있겠다.
재사용성이 높아진다 : 의존관계를 가지는 객체를 내부에서 만드는게 아니라 외부에서 만들어진 애를 받는거니까, 다른 클래스에서도 이 놈을 쓸 수 있다
테스트하기 좋아진다 : 외부에서 주입받는 거니까, 주입되는 놈의 테스트를 주입받는 애의 테스트와 분리해서 가능하다.
가독성이 좋아진다 : DI를 하는 이유가 아까 말했듯 역할의 분리니까, 기능들이 분리되므로 자연스레 가독성이 높아진다.
이런 것들을 짚고 넘어가야 할 것 같다는 생각이 들었다. 야생으로 학습 중인 만큼 지금 당장 이해 안 돼도 넘어가야 하는 부분들이 있겠지만, 그렇다고 다 넘기는 건 아닌 것 같다... 일단 한 번 짚어보고, 지금 당장 다 짚일 것 같지 않으면 넘기고 오 좀 된다 싶으면 짚고 가는게 좋을 듯 함.
그래서 서블릿이란 놈을 한 번 패보기로 했다.
배경
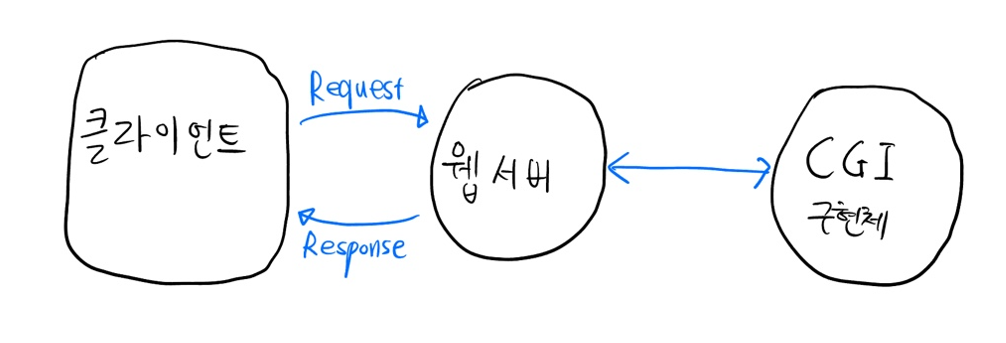
초창기 웹 프로그램은 정적 데이터만 전달 가능했다. 클라이언트가 어떤 걸 요청하면 웹서버가 정적데이터를 응답하는 식. 이게 끝
근데 이제 사용자 요청에 따라 다른 처리, 즉 동적인 처리를 해주고 싶었던 거다. 그걸 위해서 '웹 어플리케이션 프로그램'을 만들어 기존에 존재하던 웹 서버에 붙이고 싶은 거라고 보면 된다.
이걸 위해서 CGI가 등장했다. Common Gateway Interface약자로, 웹서버와 앞서 말한 웹 어플리케이션 프로그램 사이의 규약(인터풰이스)이다. C, PHP등으로 요놈의 구현체를 만든다. 이 구현체들은 결국 쉽게 말해서 동적 데이터를 처리해주는 놈, 즉 웹 어플리케이션 프로그램이다.
그래서 예전과 달리 '동적인 처리'를 해줄 수 있게 됐다. 사람들이 CGI를 많이 활용하게 됐으니까.
근데 문제가 많았던 거다. CGI가 많은 사용자를 처리하기엔 힘들었던 것.
클라이언트로부터 request가 들어올 때마다 그 놈들 하나하나마다 웹서버에서 프로세스를 만들어 처리. 프로세스니까 당연히 비용이 비쌌음
request들에 대해 같은 CGI 구현체를 써도 프로세스들이 다르면 여러 개의 구현체를 사용해야 됐음. 당연히 비효율적이었음
이를 해결하기 위해서 프로세스가 아니라 쓰레드를 만들었다. 그리고 같은 종류의 여러 CGI구현체를 만드는 몹쓸 상황을 막기 위해 CGI구현체를 싱글턴으로 만들었고.
이 싱글턴이 바로 서블릿!! 클라이언트로부터 request가 들어올 때마다 쓰레드가 생기고, 이 쓰레드를 통해 싱글턴 CGI구현체에게 동적인 처리를 해달라하는데 이걸 해주는 그 놈을 서블릿이라 부르는 것. 즉 서블릿은 자바로 구현된 CGI기도 한 거다.
결국 서블릿은
= 클라이언트의 요청을 동적으로 처리할 때 쓰이는 자바 기반의 웹 애플리케이션 프로그래밍 기술(인터페이스임)
= 동적 컨텐츠를 만드는데 사용되는 놈!
이라고 말할 수 있다
좀 더 뜯어보기 - 동작 방식
서블릿이 그래 동적인 컨텐츠를 만드는 데 쓰이는 놈이란 건 알겠다. 웹서버가 이 놈한테 말을 건네서 이 서블릿이란 놈이 동적인 처리를 해주는 거구나.
그 과정을 좀 더 뜯어본다.
HTTP request, response를 서블릿(얘 자체는 역시나 인터페이스)의 메서드들을 통해 편하게 다룰 수 있다고 한다.
httpServletRequest = 서블릿 컨테이너가 서블릿에게 전달하는 때 담는 봉투
httpServletResponse = 서블릿이 서블릿 컨테이너에게 돌려줄 때 담아보내라고 지정하는 봉투
사용자가 url입력
HTTP request가 웹서버로 전달됨
웹서버는 이 요청이 정적 자원을 요청하는지 판단(정적 자원이면 그대로 정적 자원 주면 됨)
동적인 처리가 필요하면 그 요청을 그대로 was한테 짬때림.
was의 웹 컨테이너(= 서블릿 컨테이너)가 이를 받고, 처리하기 위한 쓰레드를 만듦
그리고 컨테이너가 HttpServletRequest, HttpServletResponse객체를 만듦. HttpServletRequest객체로는 사용자가 요청한 내용을 편하게 다루고, HttpServletResponse객체에는 응답할 내용을 편하게 작성 가능
컨테이너가 사용자가 입력했던 url이 어느 서블릿에 대한 요청인지 찾고(by web.xml ), 걔를 호출. 이 때 아까만든 두 객체를 서블릿에게 선물로 줌
그 서블릿의 service메서드를 통해 요청이 처리됨! 즉 service메서드에 작성한 코드들이 실행되는 것.
이 때 아까 받은 request객체를 사용하고, 응답할 내용은 아까 받은 response객체에 저장하는 것.
또한 service메서드를 호출한 후 클라이언트가 보낸 요청이 GET인지 POST인지에 따라 doGet() 또는 doPost() 호출
이를 다시 클라이언트에게 최종 결과 응답 후, HttpServletRequest, HttpServletResponse는 삭제
※ service메서드를 호출할 때 HttpServletRequest, HttpServletResponse객체를 넘기는 것임! 즉 서블릿이 만들어질때 이 두 놈을 넘기는게 아니라 service메서드를 호출할 때 두 놈을 선물로 주는 것임에 유의
※ 톰캣은 was면서 서블릿 컨테이너의 기능도 제공한다고 함!
나아가기 - 스프링 web MVC와 서블릿
그러나..서블릿 역시 문제가 있었던 것이었다.
앞서 설명했듯 사용자가 입력한 url별로 서블릿이 매핑된다. 10개의 각기 다른 url들이 들어오면 10개의 서블릿들이 매핑되는 것! 그럴 때마다 서블릿들이 가지는 "공통된 로직"이 반복돼서 실행된다는 문제점이 있었다. 즉 개발 측면에서 상당히 비효율적이었음.
이런 점을 해결하기 위해, 클라이언트로부터의 요청을 받는 서버의 앞쪽에 모든 요청을 받는 하나의 서블릿을 두기로 했다. 그 컨트롤러가 "공통된 로직"을 수행하게 하고, 핵심 비즈니스 로직을 다른 핸들러들에게 위임하는 구조로 바꾼 거다!
원래는 이렇게 했는데이렇게 바꿔줬다는 거!
이런 방식을 Front Controller Pattern이라고 한다. 하나의 서블릿(Dispatcher Servlet)으로 모든 요청을 받게 했으니, 요청의 진입점이 같아져 관리가 보다 더 수월해진다는 장점이 있다. 또한 각 서블릿마다 가지는 공통로직을 한 곳에서만 처리함으로써 중복되는 로직의 작성도 방지하게 된다.
(디테일하게 디스패처 서블릿이 요청을 처리하는 과정은 본 글에선 다루지 않음)
결국엔 이런 방식(디스패처 서블릿이 모든 요청을 받고 공통로직들을 처리하고..)을 스프링이 사용하는 덕분에, 개발자는 핸들러(즉 컨트롤러)에만 집중하면 되도록 발전해왔다..라고 이해하면 될 듯 하다.
영어로는 Encryption. 정보를 특정 알고리즘을 이용해 암호화된 형태로 변형하는 걸 말한다. 암호문을 평문(원래 정보)로 바꾸는 것은 복호화(Decryption)이라고 부른다. 개발에서의 함호화는 보안이 필요한 정보를 특정 알고리즘을 통해 의미없는 문자열(이진수 덩어리 등)으로 바꾸는 걸 말한다.
암호화의 종류
단방향 암호화
원래대로 돌이킬 수 없는 암호화, 즉 복호화가 불가능한 암호화를 말한다(정확한 표현은 '복호화가 거의 불가능한'이 맞을 듯). 대표적으로 Hash가 있으며, 암호화된 값으로부터 다시 돌아갈 수 없기 때문에 단방향이라고 표현한다. 주로 무결성 확인 등에 사용한다. (원본을 Hash멕인 것과 원본을 조작한 후 Hash멕인 결과값이 서로 다르면 뭔가 조작됐음을 유추할 수 있고.. 머 그런)
양방향 암호화
원래대로 돌이킬 수 있는 암호화, 즉 복호화가 가능한 암호화를 말한다. 대표적으로 대칭키 암호화 방식, 공개키 암호화 방식이 있다. 대칭키 방식의 경우 암/복호화 시 사용되는 키가 동일한 방식이고, 공개키 방식은 개인키는 각 사용자가 가지고 공개키는 모든 사람이 접근하게끔 한 방식이다(A의 공개키를 사용해 암호화한 문서는 A의 개인키로만 복호화할 수 있는..뭐 그런).