그래프같은 걸 탐색할 때, 너비를 우선으로 탐색을 진행하는 것을 너비우선탐색, 영어로는 Breadth First Search라고 하며 줄여서 BFS라고도 부른다. 어떠한 시작점이 있을 때, 그로부터 가까운 것들부터 탐색해나가는 방법으로 맹목적인 탐색을 할 때 사용가능한 방법이다. 이 녀석은 '최단 경로'를 찾아주기 때문에 최단길이를 보장해야 할 때 많이 쓰인다.
예시)
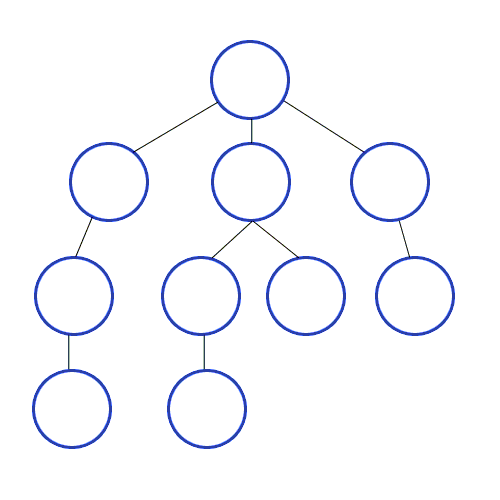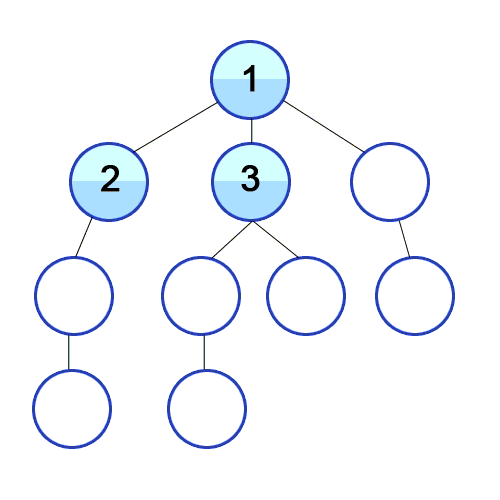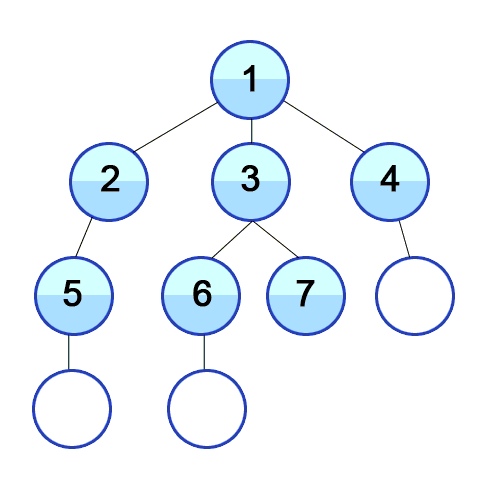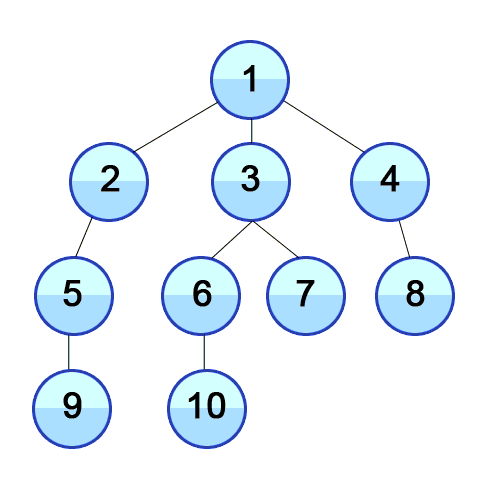
이 방법을 구현하려면, 큐(queue)가 필요하다.
Q . 왜 큐가 필요한가?
A. 큐가 선입선출 구조이기 때문에 너비 우선 탐색이 가능하도록 돕기 때문이다.
위 그림을 통해 설명하자면,
1) 시작점인 1을 큐에 넣는다.
2) 1을 큐에서 빼고, 1을 방문한 지점이라 처리해준 다음 1과 연결된 2, 3, 4를 큐에 넣는다.
3) 먼저 들어온 2를 큐에서 빼며 방문한 지점이라 처리해주고, 연결된 요소 중 방문처리가 안된 5를 큐에 넣어준다.
4) 가장 앞에 있는 3을 큐에서 빼며 방문한 지점이라 처리해주고, 연결된 요소 중 방문처리가 안된 6, 7을 큐에 넣어준다.
...반복
그럼 이걸 파이썬으로 구현해보자.
우선 그래프는 다음과 같이 딕셔너리 형태로 표현해봤다.
graph = {
1 : [2, 3, 4],
2 : [1, 3],
3 : [1, 2, 4, 5],
4 : [1, 3],
5 : [3, 6],
6 : [5]
} # 키에 연결된 value에 있는 리스트가 그 key에 연결된 애들임그리고 BFS를 도와줄 큐는 다음과 같이 해보자.
queue = [] # 큐를 리스트 형태로 구현
queue.append(something) # 큐에 요소를 넣는 동작 : append ->큐의 뒤쪽에 추가
queue.pop(0) # 큐에 요소를 빼는 동작 : pop(0) ->큐의 앞쪽에 있는 걸 뺌그럼 BFS를 다음과 같이 만들 수 있다.
def BFS(graph, start_node):
visited = [] # 방문한 요소들이 이 리스트에 저장됨
queue = [start_node] # 큐
while queue: # 큐에 뭔가 있는 동안 이하 내용을 반복한다
node = queue.pop(0) # 큐의 제일 앞에 있는 놈을 빼와서
if node not in visited: # 만약 이 놈이 방문한 적이 없다면
visited.append(node) # 방문처리
print(node) # 그 녀석 출력
queue.extend(graph[node]) # 그 녀석과 연결된 요소들(graph[node])를 queue에 추가※ 참고
어떤 리스트(A라고 가정)의 append메소드의 파라미터로 리스트를 넘기면 리스트 자체가 A리스트의 마지막 요소로 추가되지만, extend메소드의 파라미터로 리스트를 넘기면 그 리스트 자체가 A리스트에 합쳐진다.
ex) A = [1, 2, 3]이고 B = [4, 5]일때,
A.append(B)를 하면 A = [1, 2, 3, [4, 5]]
A.extend(B)를 하면 A = [1, 2, 3, 4, 5]
근데 이 방법에는 문제점이 있다.
그것을 확인하기 위해 다음과 같이 코드 중간중간에 print를 써서 현재 queue와 visited에 있는 값들을 하나하나 확인해보고, 걸리는 시간까지 알아보자.
import time
def BFS(graph, start_node):
start = time.time()
visited = []
queue = [start_node]
while queue:
node = queue.pop(0)
if node not in visited:
visited.append(node)
print(node)
print(f'방문 처리 후 visited : {visited}')
queue.extend(graph[node])
print(f'큐에 연결된 요소 추가 후 queue : {queue}')
print("-"*10)
print(time.time()-start)
실행결과
1
방문 처리 후 visited : [1]
큐에 연결된 요소 추가 후 queue : [2, 3, 4]
----------
2
방문 처리 후 visited : [1, 2]
큐에 연결된 요소 추가 후 queue : [3, 4, 1, 3]
----------
3
방문 처리 후 visited : [1, 2, 3]
큐에 연결된 요소 추가 후 queue : [4, 1, 3, 1, 2, 4, 5]
----------
4
방문 처리 후 visited : [1, 2, 3, 4]
큐에 연결된 요소 추가 후 queue : [1, 3, 1, 2, 4, 5, 1, 3]
----------
----------
----------
----------
----------
----------
5
방문 처리 후 visited : [1, 2, 3, 4, 5]
큐에 연결된 요소 추가 후 queue : [1, 3, 3, 6]
----------
----------
----------
----------
6
방문 처리 후 visited : [1, 2, 3, 4, 5, 6]
큐에 연결된 요소 추가 후 queue : [5]
----------
----------
0.007978439331054688
대략 0.007초가 걸렸다.
이 코드의 문제점은 그럼 뭘까?
어떤 요소를 방문처리해주고(visited.append(node))
그 요소와 연결된 요소들(graph[node])를 큐에 추가해줄 때, 방문한 적 없는 요소들만 추가해야 한다.
근데 위 코드는 일단 연결된 요소들 전부 큐에 추가해주고, 나중에 큐에서 꺼낼 때 꺼낸 값이 방문한 적이 있는지 없는지를 판단하기 때문에 쓸데없이 시간을 낭비하는 꼴이 된다.
그래서 다음과 같이 바꿔줄 수 있다.
def BFS(graph, start_node):
visited = []
queue = [start_node]
while queue:
node = queue.pop(0)
if node not in visited:
visited.append(node)
print(node)
for nd in graph[node]: # 연결된 요소들에 대해 하나하나 따진다
if nd not in visited: # 방문한 적 없는 요소여야
queue.append(nd) # 큐에 추가그러나 이 방법도 문제점이 있다. 큐에 원소들을 추가해주는 작업을 하는 부분을 보면 graph[node]에 해당하는 리스트의 원소들을 루프문으로 돌기 때문에, 시간낭비가 역시 생길 수 있다!
이 문제점을, set이라는 자료형를 사용해 상당히 간편하게 해결할 수 있다.
※ set??
: 수학으로 치면 '집합'의 개념에 해당하는 자료형. set이란 키워드를 이용해 만들 수 있고, set()의 괄호 안에 리스트나 문자열을 넣어주어 만들 수 있다(ex : a = set([1, 2, 3], b = set("hello") → 참고로 집합 자료형은 중복을 허용하지 않고 때문에 b의 경우는 i가 2개가 아니라 1개만 있는 형태가 된다. 암튼 이를 통해 교집합/차집합/합집합을 구하는 듯한 연산을 할 수 있는데, 이를 통해 visited에 방문한 적 없는 친구들을 넣어주는 것이 가능!
예를 들어, a = set(1, 2, 3)이고 b = set(3, 4, 5)라 해보자. a와 b의 합집합 a|b = 1, 2, 3, 4, 5가 된다! 또한, 차집합 a - b = 1, 2가 된다. 이를 통해 graph[node]의 리스트 중에서 방문한 적 없는 요소들, 즉 visited리스트에 없는 요소들만 더하려면 queue에다가 set(graph[node]) - set(visited)를 더해주면 됨!
그래서 다음과 같이 해준다.
def BFS(graph, start_node):
visited = []
queue = [start_node]
while queue:
node = queue.pop(0)
if node not in visited:
visited.append(node)
print(node)
queue += (set(graph[node]) - set(visited))그러나 아직까지도 문제가 있다..ㅋㅋㅋㅋㅋㅋ
큐에서 제일 첫 번째 녀석을 빼주는 queue.pop(0)이 문젠데, 이 녀석의 시간복잡도가 O(n)이라는 것.
이는 collection 라이브러리에 있는 deque를 사용해 해결가능하다.
그리고 visited가 리스트로 되어있는데,
if in 또는 if not in방법은 리스트에서 하면 이 역시 시간복잡도가 O(n)이다.
따라서 visited를 딕셔너리 또는 집합(set)으로 해주는 게 더 빠르다!
그래서, 다음과 같이 해주자.
from collections import deque
def BFS(graph, start_node):
visited = {}
queue = deque([start_node])
while queue:
node = queue.popleft()
if node not in visited:
visited[node] = True
print(node)
queue += (set(graph[node]) - set(visited))'ALGORITHM > 알고리즘이론' 카테고리의 다른 글
| 크루스칼 알고리즘 - 최소 신장 트리 찾기 without codes (0) | 2023.02.03 |
|---|---|
| [알고리즘] 무식하게 풀기, 브루트포스(Brute Force) 그리고 어림짐작 (0) | 2021.11.15 |
| [알고리즘] 분리집합(Disjoint Set), a.k.a Union-Find알고리즘에 대해 (0) | 2021.10.02 |
| [알고리즘] 거듭제곱을 더 빠르게 구하는 방법 (0) | 2021.09.18 |