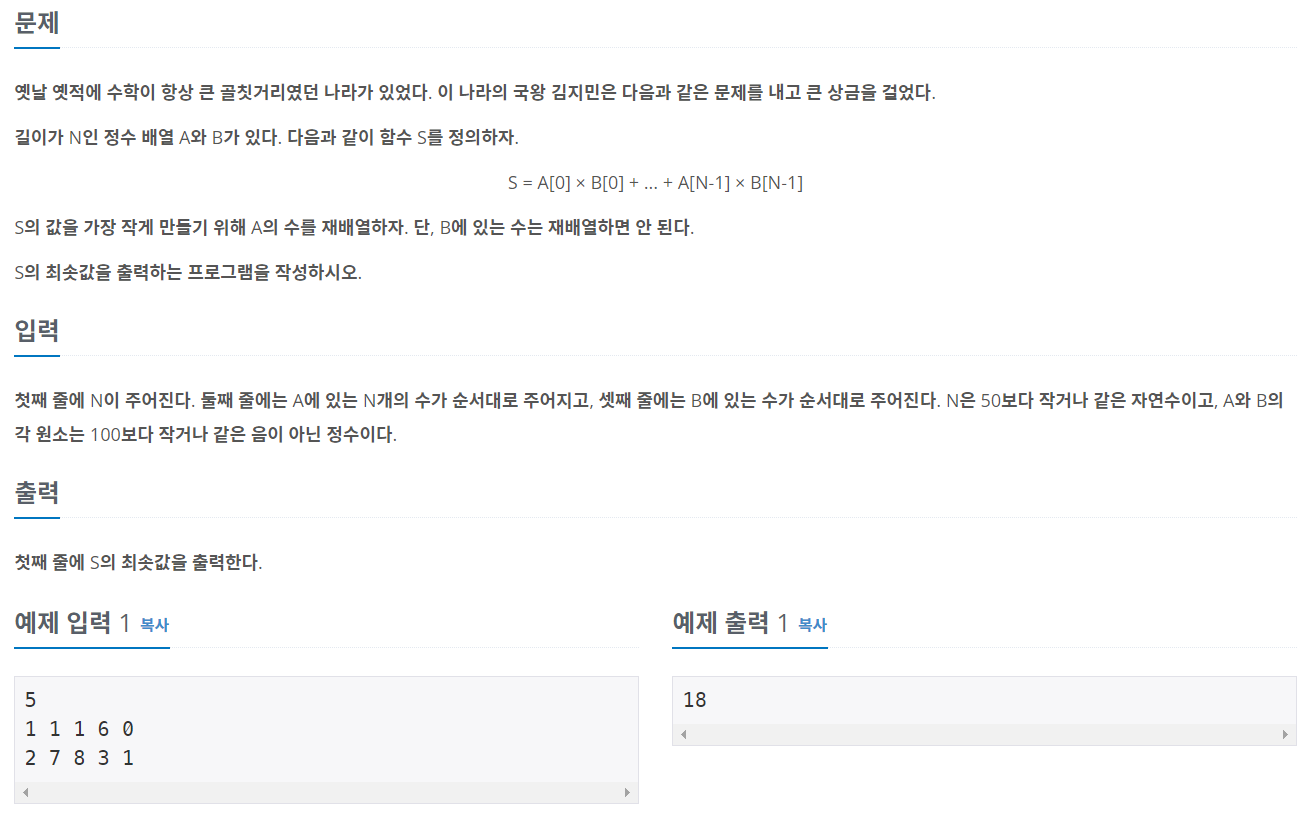
https://www.acmicpc.net/problem/2504
2504번: 괄호의 값
4개의 기호 ‘(’, ‘)’, ‘[’, ‘]’를 이용해서 만들어지는 괄호열 중에서 올바른 괄호열이란 다음과 같이 정의된다. 한 쌍의 괄호로만 이루어진 ‘()’와 ‘[]’는 올바른 괄호열이다. 만일 X
www.acmicpc.net
구현방법에서 낑낑댔다. 괄호는 스택을 사용해서 매칭시킬 수 있다는 것은 스택을 공부해봤다면 알고 가게 되는 기본 지식이지만, 중간값들을 어떻게 처리할 것인지에 대해서 계속 고민이 됐다.
어떻게 처리할지 고민하다 분할정복 기법으로 풀어봤다. 다 풀고 다른 사람들 풀이를 봤는데, 음.. 내가 좀 어렵게 푼 편이구나 싶기도 하고. 그래도 문제 푸는 방법이 1가지만 있는 게 아니니까 뭐.
def solution(parenthesis, s, e):
# base case : 바로 답을 구할 수 있는 경우
if e == s + 1:
if parenthesis[s] == "(":
return 2
else:
return 3
# recursive case : 문제가 너무 커서 바로 답 못 구하는 경우 -> 그룹별로 쪼갠다
group, stack = [], []
little_s, little_e = 0, 0
for i in range(s + 1, e):
if parenthesis[i] in ("(", "["):
if not stack:
little_s = i
stack.append(parenthesis[i])
continue
if len(stack) == 1:
little_e = i
group.append([little_s, little_e])
stack.pop()
continue
result = 0
for ns, ne in group:
result += solution(parenthesis, ns, ne)
return 2 * result if parenthesis[s] == "(" else 3 * result
parenthesis = "(" + input().strip() + ")"
stack = []
for i in range(len(parenthesis)):
if parenthesis[i] in ("(", "["):
stack.append(parenthesis[i])
continue
if not stack:
print(0)
exit()
if (parenthesis[i] == ")" and stack[-1] == "[") or (parenthesis[i] == "]" and stack[-1] == "("):
print(0)
exit()
stack.pop()
print(solution(parenthesis, 0, len(parenthesis) - 1) // 2)
기본적인 컨셉은 괄호 문자열을 그룹별로 나눌 수 있다는 점을 이용한 거다. ([])[[]]라는 문자열은 ([])과 [[]]라는 두 개의 그룹으로 구성되는 것을 이용하는 것. 그룹별로 계속 쪼개주다가 ()나 []이라는 base case를 만나게 되는데, 그 때는 2나 3을 리턴하도록 만들었다. 각 그룹에 대해 solution메서드가 동작하며, 이 놈이 파라미터로 받은 그룹을 쪼개서 쪼개진 그룹의 결과들을 더해가도록 만들면 됐다.
분할정복은 다음 영상을 참고하면 된다(본인 유튜브 홍보..ㅋㅋㅋㅋ)
https://www.youtube.com/watch?v=qDEKiNzAH1U&t=144s
'ALGORITHM > 백준BOJ풀이' 카테고리의 다른 글
| [백준] 17142 - 연구소 3 오답노트 (0) | 2023.03.03 |
|---|---|
| [백준] 14890 - 경사로 (by 파이썬) (1) | 2023.02.28 |
| [백준] 2075 - N번째 큰 수 (0) | 2023.01.27 |
| [백준] 1026 - 보물 풀이 및 그리디 정당성 검증 (0) | 2022.03.17 |
| [백준] 11726 - 2 x n 타일링 파이썬 풀이 (0) | 2022.02.12 |