https://www.acmicpc.net/problem/13305
13305번: 주유소
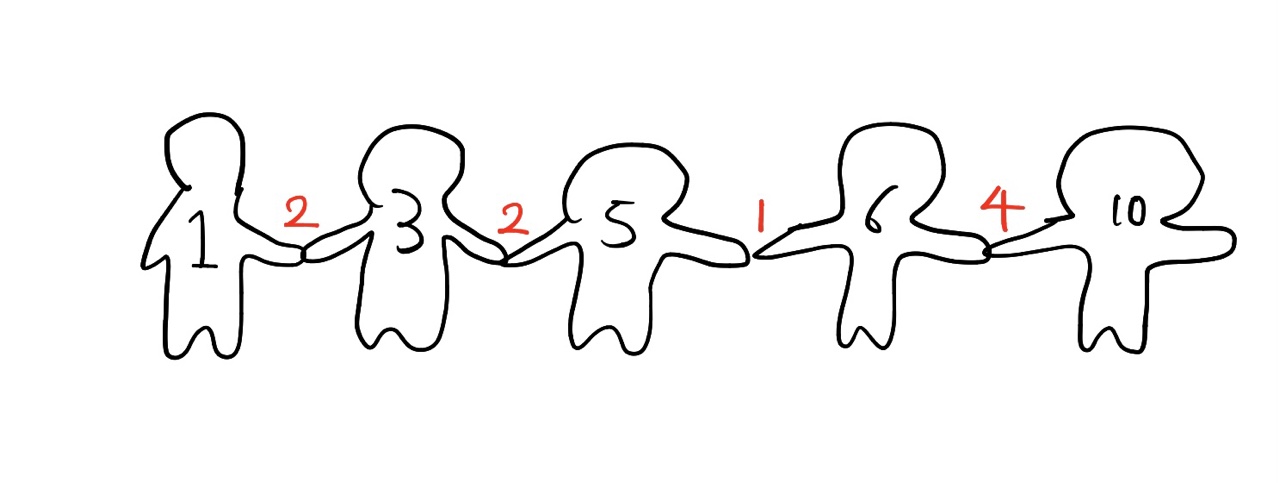
표준 입력으로 다음 정보가 주어진다. 첫 번째 줄에는 도시의 개수를 나타내는 정수 N(2 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 인접한 두 도시를 연결하는 도로의 길이가 제일 왼쪽 도로부터 N-1
www.acmicpc.net
1. 무식한 방법으로 접근한다면?
어떤 도시들에서 기름을 넣을 건지만 정하면 전체 비용이 정해진다. 첫 번째 도시에선 무조건 기름을 넣어야 하므로, 첫 번째 도시 빼고는 기름을 아예 안 넣을 수도 있다(즉 첫 번째 도시에서 마지막 도시로 갈 수 있을 만큼의 기름을 빵빵하게 넣고 가는 경우에 해당)
이는 첫 도시에서 시작해서 그 다음 도시를 선택할지 안 할건지, 그 다음 도시 역시 선택할지 안 할건지,...각 도시에 대해 두 개의 선택지가 있는 것으로, 이 경우 전체 2^(n-2)개의 방법이 나온다. 이 방법 중 최소비용이 나오는 걸 고르면 됨. 그러나 n은 문제에서 10만까지 주어지므로 이 방법으론 시간 내에 풀 수 없다는 결론
2. 부분문제로 쪼개기 가능?
가능. 마지막 도시로 가는 것은
N - 1번째 도시까지 오고, N-1번째에서 기름 넣고 N번째 도시로 한 번에 가는 경우
N - 2번째 도시까지 오고, N-2번째에서 기름 넣고 N번째 도시로 한 번에 가는 경우
N - 3번째 도시까지 오고, N-3번째에서 기름 넣고 N번째 도시로 한 번에 가는 경우
...
중에서 min값을 찾으면 됨. N - 1번째 도시까지 오는 부분문제, N - 2번째 도시까지 오는 부분문제들이 생기는 것이다.
3. 중복되는 구조 있음? 있으면 DP로 일단 가능할텐데
있음. N - 1번째 도시로 오는 부분문제도 쪼개면 N - 2번째 도시로 오는 경우 등을 구해야 하는데 이것들이 중복되는 것을 관찰가능.
그러나 DP로 풀기엔 애매한게, 이러면 시간복잡도가 O(n^2)정도가 걸리는데 n이 10만까지주어지니까 시간복잡도가 너무 크다. 다른 방법을 모색해야 함.
3. 그리디 의심
문제를 그대로 이해하면 k번째 도시에서 기름을 채우고 채운만큼 갈 수 있다. 그대~로 생각한다면 "나는 지금 이 도시에서 기름을 얼마나 채우고 가야 하는가?"로 생각하게 돼서 조금 시간이 걸렸다. 그러나 이 틀에서 벗어나서, 후불로 요금을 지불한다 생각해보자. 각 도시를 거치면서 그 도시에서 파는 기름을 살 때만 내가 이전에 쓰던 기름값을 낸다고 생각하자는 것이다. 즉 첫 도시에서 시작해(즉 첫 도시에서 기름을 사서) 두 번째 도시에 가면 두 번째 도시에서 파는 기름과 내가 지금 들고 있는 기름(첫 도시에서 산 기름) 중 어떤 기름을 쓸 건지를 선택할 수 있게 된다. 여기서 두 번째 도시에서 파는 기름을 쓰기로 했다면 그 도시까지 오는데 사용된 기름값을 그 때 낸다! 이렇게 되면 내가 지금 들고 있는 기름과 새로 방문한 도시에서 파는 기름 중 더 싼 기름만 선택해서 나가면 된다.
4. 코드
import sys
input = sys.stdin.readline
N = int(input())
length = list(map(int, input().split()))
cost = list(map(int, input().split()))
ans = cost[0] * length[0]
now_cost = cost[0]
for i in range(1, N - 1):
new_cost = cost[i]
now_cost = min(now_cost, cost[i])
ans += now_cost * length[i]
print(ans)5. 정당성 검증(그리디니까)
상식적으로 당연히 그 때 그 때 더 싼 기름을 사는게 제일 좋다. 굳이 엄밀한 증명이 필요없다고 생각됨.그래도 공부차원에서 귀류법을 사용해 정당성을 검증하자면
가정 : 매 번 가장 싼 기름을 선택해나가는게 답이다.
??? : 아니던데? ㅎㅎ
반박 :
1) 생각할 필요도 없다. 가장 싼 거 선택해나가면 그게 제일 싸잖아.
2) 그래 너 말이 맞다고 해보자.
그럼 최적해 집합 O = {o1, o2, o3, ..., ok, ..., o(n-1)}이 있고
가장 싼 기름을 선택한 집합 G = {g1, g2, g3, ..., gk, ..., g(n-1)}이 있어.
이 집합들이 합이 전체비용이겠지? 그럼 이 두 집합이 다른 집합이니까 1항부터 k항까지의 부분합이 달라지는 k가 어디엔가 존재하겠지. 그러나 생각할 수 있는 건 gk ~ g(n-1)의 합이 ok ~ o(n-1)보다 작다는 거야. 왜냐 G는 매번 가장 싼 기름을 선택한거니까!
이제 새 집합 N = {o1, o2, o3, ..., gk, ..., g(n-1)}을 만들었다고 해보자. O에서 k번째 항부터를 G의 항으로 바꾼거야. 근데 gk ~ g(n-1)까지의 합 < ok ~ o(n-1)까지의 합이니까 N의 전체합은 O보다 작겠지? 근데 O는 최적해니까 지보다 작은 전체합을 가지는 집합이 있으면 안되잖아? 이거 모순이네?
그래서 내 말이 맞아. 즉 매번 가장 싼 기름을 선택해나가야 한다는 거지.
느낀점
결국 그리디는 선택하는 과정이 있고, 그 과정에서 가장 작은/가장 큰 .. 뭐 이런 선택을 한다. 그러나 이 '선택'은 잘 보이지 않을 때가 있다. 이 문제도 단순하게 "계속 대체 지금 도시에서 얼마나 기름을 채워야 하지? 가장 많이 채워야 하나(?)"식으로 생각했다면 계속 헤멨을 것이다. 그러나 그리디가 의심될 때는 가장 작은 값 또는 가장 큰 값 이런 식으로 선택할 수 있게끔 생각을 전환할 필요가 있다. 브루트 포스로 풀 수 없다는 생각이 들고 DP로 풀기도 애매해서 그리디가 의심된다면 가장 ~~한 선택을 쉽게 할 수 있게끔 생각을 전환할 필요가 있다는 점을 알고 가자.
'ALGORITHM > 백준BOJ풀이' 카테고리의 다른 글
| [백준] 1026 - 보물 풀이 및 그리디 정당성 검증 (0) | 2022.03.17 |
|---|---|
| [백준] 11726 - 2 x n 타일링 파이썬 풀이 (0) | 2022.02.12 |
| [백준] 13164 - 행복 유치원 파이썬 풀이, 자세한 풀이와 함께 (0) | 2022.01.29 |
| [백준] 11660 - 구간 합 구하기 5 by python (0) | 2022.01.08 |
| [백준] 1715 - 카드 정렬하기 by python (0) | 2021.12.30 |