지난 글에서는 MyBatis나 JPA없이 순수 JDBC만을 활용해 Connection, Statement, ResultSet 등을 사용하면서 DB에 접근하는 방법을 다뤘었습니다.
※지난 글 : https://jofestudio.tistory.com/153
애플리케이션을 개발하면서 @Transactional 어노테이션을 통해 트랜잭션을 편리하게 사용하기도 하고, 커넥션풀들도 이미 사용 중이기도 한데요. JDBC만으로는 트랜잭션을 어떻게 다루고, 또 JDBC 스펙에서는 커넥션풀을 어떻게 다루도록 설계했는지 그 원리가 궁금하여 이번에 공부를 했고, 그 내용을 공유하고자 합니다.
목차는 다음과 같습니다.
- JDBC로 트랜잭션 직접 다루기
- Auto Commit 모드 끄기
- rollback 메서드를 명시적으로 쓰지 않으면 어떻게 될까?
- SavePoint 인터페이스
- JDBC와 트랜잭션 격리 수준
- 커넥션 풀
- ConnectionPoolDataSource
- PooledConnection
- ⭐️ 하지만 실제로 이 설계들을 항상 지키진 않는다.
- 커넥션 풀 관련 속성
1. JDBC로 트랜잭션 직접 다루기
1 - 1. Auto Commit 모드 끄기
JDBC는 Connection 객체가 만들어지면, Auto Commit 모드가 켜진 채로 만들어지는 것을 디폴트로 하고 있습니다. 이는 각 SQL문들이 서로 독립적인 트랜잭션으로 실행되며 실행된 후에 곧바로 커밋된다는 것을 의미하는데요, 여러 SQL문들을 하나의 트랜잭션으로 처리하고 싶으면 Auto Commit 모드를 다음과 같이 직접 꺼줘야 합니다.
conn.setAutoCommit(false);
이렇게 하고 나면, 직접 명시적으로 Connection 객체의 commit 메서드를 호출해야만 트랜잭션이 커밋됩니다. 예외가 발생한 경우, rollback 메서드를 명시적으로 호출할 것을 권고하고 있습니다. 예시는 다음과 같습니다. (제가 토이 프로젝트로 하고 있는 프로젝트의 테이블을 사용해습니다.)
public void insertNewProduct() {
String insertProductSql = "INSERT INTO TB_PRODUCT (PROD_CODE, PROD_NAME, PROD_TYPE) values (?, ?, ?)";
String insertProductHistorySql = "INSERT INTO TB_PRODUCT_HISTORY " +
"(PROD_CODE, PROD_NAME, PROD_TYPE, PROCESSED_TYPE) VALUES (?, ?, ?, ?)";
try (Connection conn = JdbcSample.getConnectionByDriverManager()) {
conn.setAutoCommit(false); // 오토 커밋 꺼주기
try (PreparedStatement insertProductPstmt = conn.prepareStatement(insertProductSql);
PreparedStatement insertProductHistoryPstmt = conn.prepareStatement(insertProductHistorySql)) {
insertProductPstmt.setString(1, "600");
insertProductPstmt.setString(2, "테스트입출금통장");
insertProductPstmt.setString(3, "10");
insertProductPstmt.executeUpdate();
insertProductHistoryPstmt.setString(1, "600");
insertProductHistoryPstmt.setString(2, "테스트입출금통장");
insertProductHistoryPstmt.setString(3, "10");
insertProductHistoryPstmt.setString(4, "I");
insertProductHistoryPstmt.executeUpdate();
conn.commit(); // 커밋 메서드 명시
} catch (SQLException e) {
conn.rollback();
throw e;
}
} catch (SQLException e) {
System.out.println("Database error: " + e.getMessage());
}
}
참고) MySQL JDBC Driver 기준, Connection 생성 시 SET autocommit=1이 DB로 날아가고, Auto Commit 모드를 끄면 SET autocommit=0이 DB로 날아갑니다 .
1 - 2. rollback 메서드를 명시적으로 쓰지 않으면 어떻게 될까?
예외가 발생하면 rollback 메서드를 호출해야 한다고 하지만, 그럼 만약 예외 발생 시 rollback 메서드를 명시적으로 사용하지 않으면 롤백이 안 되는 걸까요? 뜯어보니 MySQL JDBC Driver가 제공하는 Connection 구현체 중 ConnectionImpl은 close될 때 Auto Commit 모드를 꺼둔 상태라면 롤백을 해주도록 되어있었습니다.
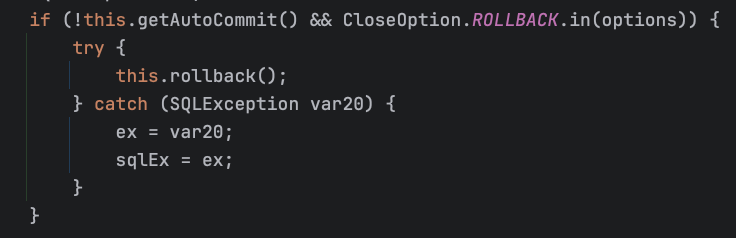
따라서 Auto Commit 모드를 끈 상태라면 좌우지간 개발자가 명시적으로 commit 메서드를 호출하지 않아도 롤백이 자동으로 되고, 예외가 터졌을 때도 명시적으로 rollback 메서드를 호출하지 않아도 롤백이 자동으로 되긴 합니다. 심지어 commit 메서드를 수행한 뒤에도 close될 때 ROLLBACK이 DB로 날라가는 모습도 확인했었습니다. 그러면 굳이 rollback 메서드를 호출하지 않아도 되는 것 아니냐는 생각을 했습니다만, DataSource 구현체를 어떤 것을 사용하는지에 따라 사용하는 Connection 구현체가 바뀌는 등 드라이버의 처리에 의존하는 것보다는 개발자가 명시적으로 rollback 메서드를 호출하는 것이 안정성 있는 시스템을 만들 수 있다는 생각이 듭니다.
1 - 3. SavePoint 인터페이스
JDBC API는 SavePoint라는 인터페이스를 통해 rollback 메서드 수행 시 특정 지점으로 되돌아가는 기능도 제공합니다. 트랜잭션 전체를 롤백하지 않고, Savepoint가 설정된 곳 이후의 작업만 롤백하는 형태로 이해할 수 있습니다. Connection 인터페이스의 다음 메서드들을 통해 SavePoint들을 다룰 수 있습니다
- setSavePoint() : 현재 트랜잭션에 익명의 SavePoint를 만들어 리턴
- setSavePoint(String) : 현재 트랜잭션에 이름이 있는 SavePoint를 만들어 리턴
- rollback(SavePoint) : SavePoint가 set된 곳 이후의 작업들을 undo (Auto commit이 꺼져있을 때 사용되어야 합니다)
- releaseSavePoint(SavePoint) : 현재 트랜잭션에서 해당 SavePoint를 포함해 이후에 설정된 SavePoint들을 전부 해제 (한 트랜잭션이 과도하게 많은 SavePoint를 set하면 그만큼 DB 리소스를 많이 쓰는 거라, 이 메서드를 통해 SavePoint들을 중간중간 제거하여 리소스를 해제하는 역할을 할 수 있습니다)
예제는 다음과 같습니다. 아까 보여드린 코드를 재활용했습니다.
public void insertNewProduct() {
String insertProductSql = "INSERT INTO TB_PRODUCT (PROD_CODE, PROD_NAME, PROD_TYPE) values (?, ?, ?)";
String insertProductHistorySql = "INSERT INTO TB_PRODUCT_HISTORY " +
"(PROD_CODE, PROD_NAME, PROD_TYPE, PROCESSED_TYPE) VALUES (?, ?, ?, ?)";
try (Connection conn = JdbcSample.getConnectionByDataSource()) {
conn.setAutoCommit(false);
Savepoint savepoint = conn.setSavepoint("BeforeInsert");
try (PreparedStatement insertProductPstmt = conn.prepareStatement(insertProductSql);
PreparedStatement insertProductHistoryPstmt = conn.prepareStatement(insertProductHistorySql)) {
insertProductPstmt.setString(1, "600");
insertProductPstmt.setString(2, "테스트입출금통장");
insertProductPstmt.setString(3, "10");
insertProductPstmt.executeUpdate();
savepoint = conn.setSavepoint("AfterProductInsert");
insertProductHistoryPstmt.setString(1, "600");
insertProductHistoryPstmt.setString(2, "테스트입출금통장");
insertProductHistoryPstmt.setString(3, "10");
insertProductHistoryPstmt.setString(4, "I");
insertProductHistoryPstmt.executeUpdate();
throw new SQLException("고의로 에러 발생");
} catch (SQLException e) {
conn.rollback(savepoint);
throw e;
}
} catch (SQLException e) {
System.out.println("Database error: " + e.getMessage());
}
}
MySQL에서는 다음처럼 날아갑니다.
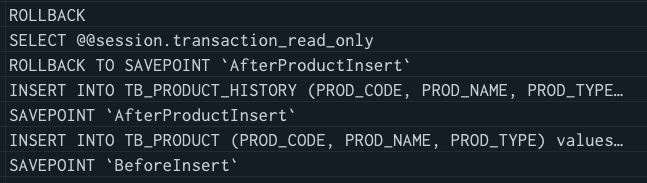
근데 마지막에 롤백이 실행된 것을 볼 수 있는데요, 이는 앞서 말한 것처럼 MySQL JDBC Driver는 Connection의 close가 호출됐을 때 Auto Commit 모드가 꺼져 있으면 롤백이 수행되게끔 구현되어있기 때문입니다. 그렇다면 "어차피 트랜잭션을 닫을 때 전체가 롤백되는 거라면 SavePoint를 사용한 부분 롤백은 아무 의미 없는 거 아닌가?" 라는 생각이 들었는데요. 사실 이것은 SavePoint의 사용 패턴이 트랜잭션을 부분 롤백한 채로 끝내는 데 목적이 있는 게 아니라 부분 롤백 후 트랜잭션을 계속 진행 하는 데 목적이 있기 때문입니다. 예를 들자면 배치 작업 등에서 일부 실패를 허용할 때 등이 있겠고, 이런 상황을 코드로 간략하게 보면 다음과 같습니다.
conn.setAutoCommit(false);
작업A();
Savepoint sp = conn.setSavepoint("sp1");
try {
작업B(); // 실패 가능성 있는 작업
} catch (SQLException e) {
con.rollback(sp); // sp1까지만 롤백, 트랜잭션을 여기서 닫지 않음!
}
작업C(); // 계속 진행
conn.commit(); // A와 C가 반영됨 ← 이걸 해야 의미가 있음
참고) 스프링의 트랜잭션 전파 옵션이 내부적으로 SavePoint를 활용한다고 하는데요, 곧 스프링 트랜잭션에 대해서도 공부를 하며 이 부분을 좀 더 파볼려고 합니다.
1 - 4. JDBC와 트랜잭션 격리 수준
JDBC API는 다음과 같은 5가지의 격리 수준을 지원합니다.
- TRANSACTION_NONE (0)
- TRANSACTION_READ_UNCOMMITTED (1)
- TRANSACTION_READ_COMMITTED (2)
- TRANSACTION_REPEATABLE_READ (4)
- TRANSACTION_SERIALIZABLE (8)
Connection의 setTransactionIsolation 메서드를 호출하여 특정한 격리수준을 현재 세션에 설정할 수 있으며, 현재 세션의 격리 수준은 getTransactionIsolation메서드로 조회할 수 있습니다. MySQL JDBC Driver는 setTransactionIsolation 메서드 호출 시 DB로 SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED 등이 날라갑니다. 참고로 벤더사들이 구현한 JDBC Driver 별로 특정 격리수준에 대한 setting이 드라이버 레벨에서 불가능하게 만들어져있다든지, 아니면 DB별로 특정 트랜잭션 격리 수준으로 SET SESSION하는게 안 될 수도 있습니다. (예를 들면, MySQL에서는 TRANSACTION_NONE을 설정할 수 없습니다)
참고) 각 격리 수준의 의미와 발생 가능한 문제들을 다루는 것은 JDBC 범위를 넘어간다고 생각하지 않아 따로 이 글에선 작성하지 않으려고 하는데요, 혹시 궁금하신 분들은 제가 예전에 쓴 글을 보시면 좋을 것 같습니다 :)
https://jofestudio.tistory.com/145
2. 커넥션 풀
"[JDBC] (1편) MyBatis, JPA 없이 JDBC로만 DB를 다루는 세상이었다면"에서 JDBC를 사용하는 애플리케이션은 DriverManager 또는 DataSource로부터 Connection을 얻는다고 소개했었는데요. 커넥션 풀링은 JDBC API에서는 DataSource에서 지원되는 기능으로 설계됐습니다. 즉 DataSource는 커넥션 풀링을 지원하냐 안 하냐에 따라 구분할 수 있습니다. 풀링을 지원하지 않는 DataSource는 getConnection을 통해 얻은 Connection이 DB와의 물리적인 연결을 의미하는 요소이고, close할 때는 실제로 물리적인 연결이 끊어지게 됩니다. 하지만 JDBC API는 풀링을 지원하는 DataSource는 내부 동작이 조금 달라지도록 설계했는데, 이를 이해하려면 JDBC API가 제공하는 다음 두 인터페이스에 대한 이해가 필요합니다.
2 - 1. ConnectionPoolDataSource
ConnectionPoolDataSource는 DataSource 인터페이스가 Connection타입의 객체를 반환하는 getConnection 메서드를 가졌던 것과는 다르게 , PooledConnection 타입의 객체를 만들어 반환하는 getPooledConnection이라는 메서드를 갖고 있는 인터페이스입니다. 즉 PooledConnection들의 팩토리 역할을 하는 객체로 볼 수 있습니다.
2 - 2. PooledConnection
DB와 맺는 실제 물리적인 연결을 래핑한 객체로, 커넥션풀이 저장되는 단위가 되는 커넥션이 PooledConnection입니다. 다시 말하면 커넥션풀을 통해 재사용되는 커넥션이 PooledConnection이라는 이야기입니다. 이 인터페이스는 getConnection이라는 메서드를 가지며, 이 메서드가 Connection 타입의 객체(DataSource의 getConnection을 하면 받는 그 타입)을 리턴합니다. 즉 PooledConnection과 Connection은 서로 다른 객체입니다.
아직까진 이해가 조금 힘들 수 있는데요, (왜냐하면 제가 그랬으니까..) 간략히 말하자면 커넥션 풀링을 지원하는 DataSource는 두 인터페이스들을 사용해서 다음처럼 동작합니다.
- ConnectionPoolDataSource를 통해 DB와의 물리적 연결을 의미하는 PooledConnection들을 만들어 풀에 저장해둠
- JDBC 애플리케이션이 DataSource의 getConnection을 통해 커넥션 요청 (= DataSource API를 통해 커넥션 요청)
- 커넥션 풀 매니저(= DataSource의 구현체)는 커넥션풀에 있는 PooledConnection을 하나 골라, getConnection을 통해 JDBC Application이 사용할 수 있는 Connection을 만들어 반환
그림으로 도식화하면 다음과 같습니다.
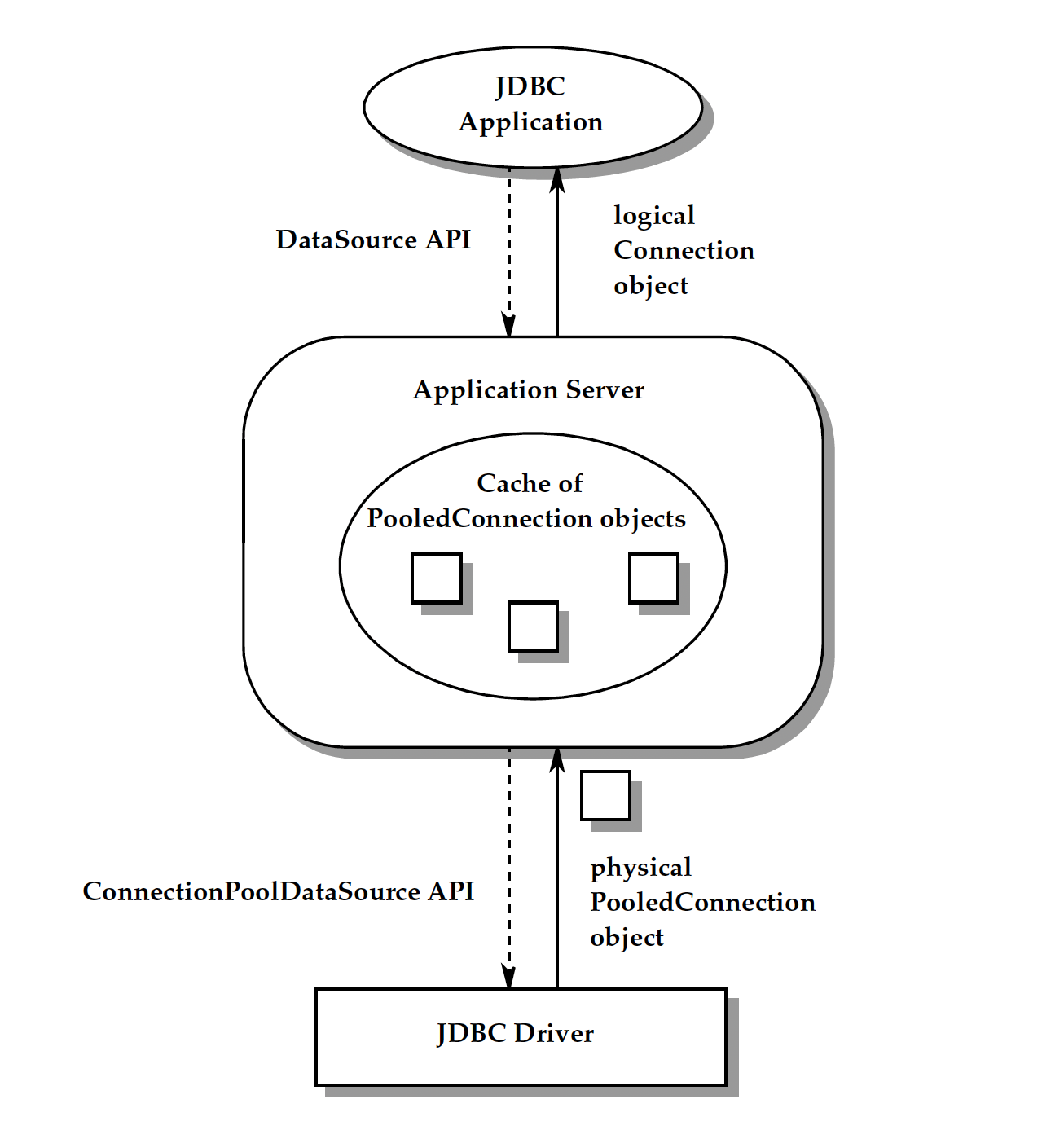
즉 커넥션 풀링을 지원하는 DataSource를 사용하는 경우, JDBC 애플리케이션에게 반환한 Connection은 논리적인 의미의 커넥션일 뿐 DB와의 실제 물리적 연결을 의미하진 않는 거고, ConnectionPoolDataSource가 만든 PooledConnection이 DB와의 실제 물리적 연결을 의미하는 셈입니다.
이로 인해 PooledConnection의 getConnection을 통해 얻은 Connection의 close 메서드가 호출될 때는 조금 다르게 동작하게 되는데요. 바로 물리적인 연결을 끊는 것이 아니라, 해당 Connection을 비활성화하고 연관된 PooledConnection을 다시 풀에 반납하는 식으로 동작하게 됩니다. 즉, 풀링을 지원하지 않는 DataSource든 풀링을 지원하는 DataSource든 똑같이 getConnection을 통해 Connection을 획득해서 사용할 수 있으나, 엄연히 말하면 이 둘은 타입은 같지만 서로 다른 구현체를 쓰는 것임을 알 수 있습니다. 또한 뻔하긴 합니다만 PooledConnection은 생애주기동안 여러 Connection을 만들게 됨도 알 수 있습니다.
참고 1) PooledConnection가 기존에 반환한 Connection이 활성 상태일 때 getConnection을 호출하면, 기존에 활성 상태로 있던 Connection이 비활성화됩니다. 이를 통해 강제로 클라이언트가 사용하는 커넥션을 끊을 수 있습니다.
참고 2) PooledConnection의 close를 호출해야 실제 DB와의 물리적 연결을 끊게 됩니다.
조금 더 세부적으로 파보면, PooledConnection에서 Connection을 만들어 줄 때 ConnectionEventListener라는 JDBC에서 제공하는 또다른 인터페이스의 구현체를 PooledConnection에 등록하는 과정이 있습니다. 이 인터페이스는 connectionClosed 메서드와 connectionErrorOccured라는 메서드를 가지는데요, PoolecConnection이 반환한 Connection이 close될 때 이 인터페이스의 connectionClosed 메서드를 통해 PooledConnection가 풀로 반환되게 됩니다.
⭐️ 2 - 3. 하지만 실제로 이 설계들을 항상 지키진 않는다.
방금 본 것처럼, JDBC는 ConnectionPoolDataSource, PooledConnection을 사용해서 커넥션 풀링을 사용하도록 설계했습니다. 하지만 실제 커넥션풀 라이브러리로 사용되는 HikariCP나 Apache Commons DBCP 등은 이 표준을 지키지 않고 구현한 경우가 많습니다. DataSource에서 getConnection을 해서 Connection을 얻는 건 똑같고 커넥션 풀링이 지원되는 건 똑같지만, 내부적으로는 ConnectionPoolDataSource나 PooledConnection을 쓰지 않고 본인들만의 방식으로 풀링을 구현했습니다.
왜 그랬을까요? 표준은 지켜야 하는게 아니었을까요!
사실 HikariCP나 Apache Commons DBCP 개발자가 아닌 이상 그 이유를 우리가 100% 명확히 알 수는 없습니다만, 그래도 깃허브 이슈나 남아있는 문서 등을 통해 그 분들이 왜 표준을 지키지 않고 독자적인 방식으로 구현하는 방향으로 기술적인 의사결정을 했는지 유추해볼 수 있습니다.
깃허브 HikariCP 레포지토리에서 다음 위키문서와 이슈를 찾아볼 수 있었습니다.
https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole
https://github.com/brettwooldridge/HikariCP/issues/54
특히나 이슈의 내용이 흥미로운데요! 요약하면 다음과 같습니다.
- dimzon(이슈 작성자) : HikariCP가 ConnectionPoolDataSource를 지원하도록 구조를 개선해보는게 어때?
- brettwooldridge : PooledConnection이 좋은 의도로 만들어진 인터페이스긴 하지만 풀링에 필요한 풍부한 기능은 없어. 예컨대 HikariCP는 자체적으로 Connection의 프록시를 제공하는데, 얘는 setTransactionIsolationLevel 등이 호출되면 가로채서 상태 변화도 추적한 뒤, 커넥션이 반납될 때 상태 변화가 없었다면 리셋하지 않아. 또 Postgre JDBC Driver의 ConnectionPoolDataSource 구현을 확인해보니, PooledConnection이 예상치 않게 동작해. JDBC Driver의 ConnectionPoolDataSource 구현이 우리가 제공하는 고성능 풀링을 위한 설정들이 제대로 적용되어있어야 할텐데, 그렇지가 않아..
커넥션풀 라이브러리를 구현하는 입장에서, JDBC 스펙대로 ConnectionPoolDataSource와 PooledConnection을 사용해서 풀링을 구현하려면 벤더사들이 제공하는 JDBC Driver이 만드는 구현체들에 의존할 수밖에 없는데, 그렇게 되면 어떤 드라이버를 쓰느냐에 따라 성능이 뒤죽박죽이 될 수도 있고 예상치 못한 동작이 가능할 수도 있습니다. 따라서 스스로 독자적으로 풀링을 구축하는 것이 더 안전하고 빠르다. 라고 생각한 듯 합니다.
하지만 해당 이슈에 24년도에도 ConnectionPoolDataSource 지원을 제고하자고 말한 내용이 있는 걸 보니.. 역시 개발과 기술에 정답은 없는 것 같습니다. 항상 트레이드 오프가 있고, 어떤 선택을 어떤 상황에서 어떤 근거로 했는지가 중요한 것 같네요.
2 - 4. 커넥션 풀 관련 속성
JDBC API는 커넥션 풀에 관련하여 다음 속성들을 정의하고 있습니다.
- maxStatements : 풀이 캐싱하는 Statement의 수
- initialPoolSize : 풀이 처음 만들어질 때 가질 커넥션 수
- minPoolSize : 풀이 항상 '사용 가능'해야 하는 최소 커넥션의 수. 0개면 필요할 때마다 만들겠다는 의미
- maxPoolSize : 풀이 가질 수 있는 최대 커넥션 수, 0이면 제한없다는 의미
- maxIdleTime : 커넥션이 닫히기 전, 물리적 연결이 사용되지 않는 채로 남아있어야 하는 시간(초)
- propertyCycle : 커넥션풀 설정을 반영하기 위한 간격(초)
커넥션풀 공급업체는 스스로만의 속성들을 사용 가능하나, 그러면 위 이름이 아닌 다른 속성들을 사용해야 합니다.
레퍼런스
JSR-221 (https://download.oracle.com/otndocs/jcp/jdbc-4_3-mrel3-spec/)
https://docs.oracle.com/javase/tutorial/jdbc/basics/transactions.html
https://docs.oracle.com/javase/tutorial/jdbc/basics/sqldatasources.html
https://docs.oracle.com/javase/8/docs/api/javax/sql/ConnectionPoolDataSource.html
https://docs.oracle.com/javase/8/docs/api/javax/sql/PooledConnection.html
https://docs.oracle.com/javase/8/docs/api/javax/sql/DataSource.html
'WEB > JAVA' 카테고리의 다른 글
| [JDBC] (1편) MyBatis, JPA 없이 JDBC로만 DB를 다루는 세상이었다면 (1) | 2026.01.11 |
|---|---|
| 한계를 뛰어넘는 자바의 마법, Virtual Thread 뜯어보기 (5) | 2024.10.09 |
| JNI(Java Native Interface)란? (feat. 자바 스레드 생성) (2) | 2024.09.15 |
| 이 함수형 인터페이스에는 추상메서드가 2개 이상인데요? (feat.Object) (1) | 2024.07.21 |
| try-with-resources : 자원을 자동으로 해제하기 (0) | 2023.01.24 |