기존에 배열에서 for loop를 돌 때 사용가능한 방법으로 알고 있던 것은 for-of문을 사용하는 것이었다.
그러나 js에선 기본적으로 배열에서 루프를 도는 것고 관련해 forEach와 map이란 메소드를 제공한다. 이들에 대해 간단하게 살펴보자.
1. forEach
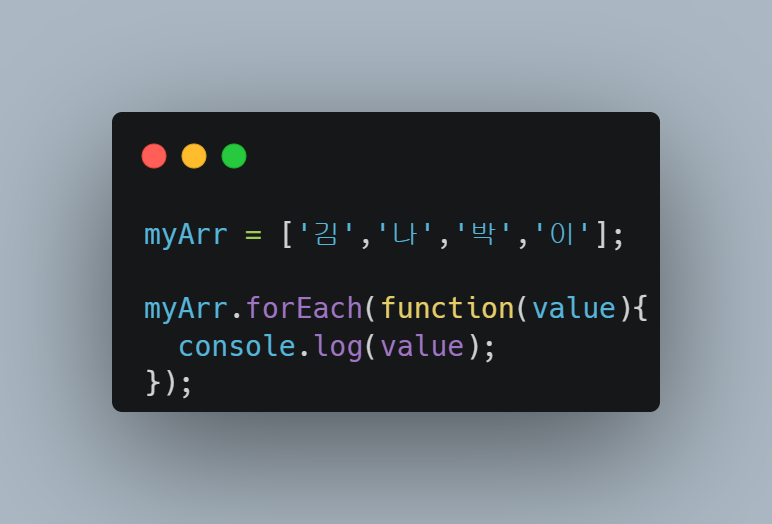
파라미터로 콜백함수를 작성하며, 이 콜백함수의 파라미터로 배열의 각각 요소들이 들어가서 콜백함수의 내용을 수행한다. 즉 콜백함수에는 파라미터 하나가 반드시 작성되어야 한다.
당연히 화살표 함수(Arrow function)으로도 작성가능
근데 이 콜백함수에 작성하는 파라미터를 여러 개 쓸 수도 있다. 일단 첫 번째 파라미터는 배열의 각각의 요소들이 들어가는 자리고, 두 번째 파라미터를 주면 요소의 인덱스를 관리할 수 있게 된다. 당연히 이 녀석은 처음엔 0부터 시작해서 각 요소들이 순회될 때마다 1씩 더해지는 값이다. 주로 다음과 같이 많이 쓴다.
세 번째 파라미터는 주로 arr이란 이름으로 많이들 작성하며, forEach메소드를 쓰고 있는 배열 자체(위 예시에선 myArr이란 배열)이 arr로 들어온다. myArr처럼 변수이름에 담아서 배열을 쓸 경우엔 굳이 쓸 필요 없긴 하지만, [1, 2, 3, 4]처럼 리터럴 배열을 사용할 경우엔 요긴하게 쓸 수 있을 것이다.
2. map
forEach와 동작하는 방식은 거의 비슷하다. 파라미터로 콜백함수를 받으며, 콜백함수의 첫 번째 파라미터로는 배열의 각각 요소들이, 두 번째 파라미터로는 인덱스 값이 전달된다. 그러나 map이 forEach와 다른 점은 메소드의 호출 결과로 또 다른 배열을 리턴한다는 것이다(forEach메소드는 리턴값이 없다). 즉 콜백함수 내에서 return문을 작성하게 되면 각각의 리턴값으로 구성된 새로운 배열이 map메소드의 결과로 리턴된다는 것이다!
즉 단순 반복작업이 필요하면 forEach, 새로운 배열이 필요하면 map메소드를 사용한다는 것.
주의할 점이 있는데, 두 메소드의 최대 반복 횟수는 메소드를 처음 호출할 때의 요소 개수이다. 즉 중간에 배열의 길이가 늘어나도 처음의 배열 원소 개수만큼만 동작한다는 점. 그러나 형광펜으로 강조했듯이 최대 반복 횟수가 처음 호출할 때의 요소 개수란 것이지 언제나 반복 횟수가 그렇다는 게 아니다. 배열의 길이가 줄어들면(pop을 한다던지), 그 만큼 반복횟수가 줄어든다. 이 점 알아두고 사용하도록 하자.
# 각 조별로 반티를 만드는데, 그 조에서 가장 큰 인원의 키 - 가장 작은 인원의 키만큼 돈이 든다
# 조원이 한명이면 드는 돈은 0원
# k개의 조를 만들어야 할 때 생길 수 있는 전체반티비용 중 최소는?
#1. 무식한 방법으로 접근 (브루트포스)
N개의 인원들을 K개의 조로 나누는 모든 경우를 조사해서 그 중 최소비용이 드는 애를 찾으면 될 것이다.
N개의 인원을 K개의 조로 나누는 경우는 (N-1)C(K-1)개이며, 러프하게 생각하면 (N - 1)!정도가 드는 것이니 이 방법으론 시간 내에 통과할 수 없을 거라 생각된다..
#2. 부분문제로 쪼갤 수 있는지 확인 -> DP or 그리디를 의심한다
마지막 조 인원이 1명일 때, 마지막 조에서 발생하는 비용 + 남은 N-1명을 K-1개 조로 나눌 때 드는 최소비용
마지막 조 인원이 2명일 때, 마지막 조에서 발생하는 비용 + 남은 N-2명을 K-1개 조로 나눌 때 드는 최소비용
마지막 조 인원이 3명일 때, 마지막 조에서 발생하는 비용 + 남은 N-3명을 K-1개 조로 나눌 때 드는 최소비용
이 중 최소값이 정답이 될 것이며, 형광펜으로 칠해진 부분이 부분문제.
#3. 혹시 저 부분문제들이 중복되는가? -> 그러면 DP로 풀 수 있을 것이다.
중복된다. f(N, K)가 N명을 K개의 조로 쪼갤 때 발생하는 최소비용이라 하면
f(N, K)를 구하기 위해선 f(N-1, K-1), f(N-2, K-1), f(N-3, K-1)...를 구해야 한다. (바로 위 #2에서 부분문제 쪼개는 부분 참고)
여기서 f(N-1, K-1)을 구하기 위해선 f(N-2, K-2), f(N-3, K-2), f(N-4, K-2), f(N-5, K-2)...를 구해야 하는데
f(N-2, K-1)을 구하기 위해선 f(N-3, K-2), f(N-4, K-2), f(N-5, K-2)...를 구해야 하고
f(N-3, K-1)을 구하기 위해선 f(N-4, K-2), f(N-5, K-2)...를 구해야 한다.
이 구조에서 중복되는 걸 관찰가능.
표로 중복되는 것을 관찰하면 다음과 같다.
#4. 그러나 맞닥뜨린 문제점 - 메모리 이슈 및 시간 이슈
DP로 그럼 잘 풀수 있겠거니 했지만..몇 가지 문제점이 생겼다. 첫 번째는 메모리 제한 이슈. 위 표와 같은 dp테이블을 만들려고 했는데, 그러려면 N * K사이즈만큼의 배열이 만들어지는데 문제는 N과 K의 최대치가 30만이라 30만*30만 = 900억이라는 경이로운 사이즈의 배열이 만들어진다. 그러나 이 문제의 메모리제한은 512MB로...안된다 암튼
또 하나의 문제점 = 시간복잡도. 위 방법으로 하게 될 경우 러프하게 생각하면 O(N^2)정도의 시간복잡도가 드는데, 이게 이 문제의 시간제한인 1초 내에 되리라는 생각이 들지 않는다.
#5. 그리디를 의심해보자
우선 그리디로 해도 괜찮은 문제인지 봤다. 그러나 여기서부터 꼬이기 시작..ㅋㅋㅋㅋㅋ
일단 난 #2에서 세웠던 부분문제에 얽매여 있었기 때문에..그리디로 한다면 처음부터 2명씩 모아간다던가 이런 식으로 생각했다.
일단 그리디 속성?이 현재 내리는 선택이 이후의 선택이 영향을 주지 않는다는 것 즉 내가 지금 2명 모았다고 다음 번 조는 두 명 못 모으나? 그런 건 아니다. ㅇㅋ
지금의 선택 자체로 부분문제가 되는가? 이것도 맞고그리디로 풀 수 있는 문제같긴 한데. 어떤 기준으로 조를 만들어 나가야 하는가라는 문제에 봉착했다. 그리디는 가장 ~~한대로 선택해 나가는 것인데, 키 순서로 이미 서있는 아가들을 어떤 기준으로 모아 나가야 하는가..?
#6. 결국 인터넷으로 서치해봤다
일단 정답은 인접한 애들끼리의 차이값을 계산한 후 이 값들을 정렬하고, N - K개 만큼의 가장 큰 값들을 빼고 남은 값들을 합치면 정답이라고 했다. 나도 풀다가 중간에 인접한 애들끼리의 차이값을 이용하는건가 하고 봤지만,, 암튼 이렇게 하면 됐던 거라고? 라는 생각이 들면서, "그래서 이게 왜 답이 되는데"라는 생각도 들었다.
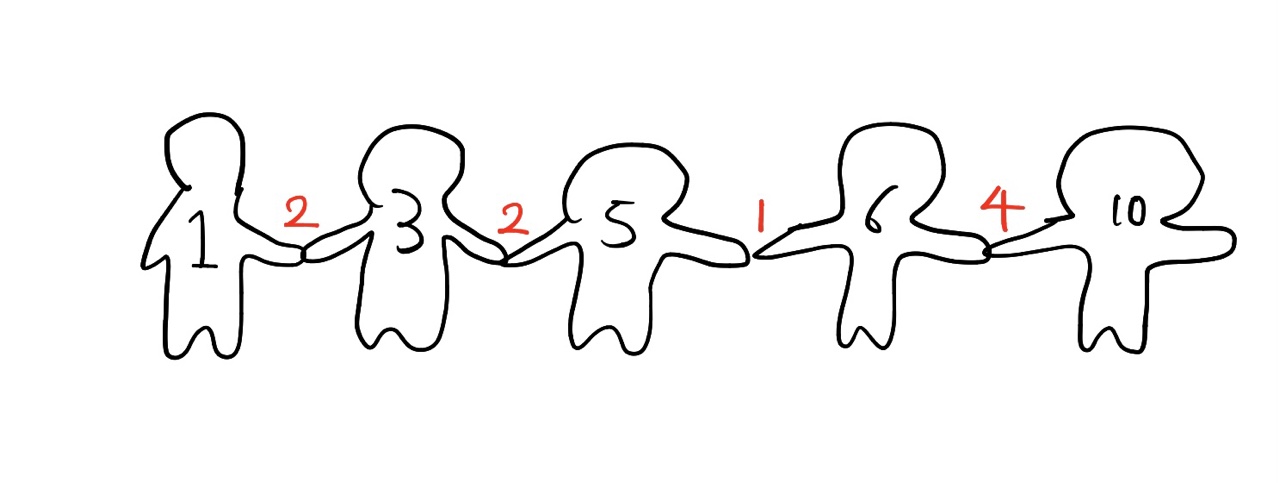
이게 왜 답이 되는지는 좀만 생각해보면 나올 수 있었다. 키 순서대로 서 있는 애들이 각자 손을 잡고 있다고 해보자. 즉 나는 애 앞에 서있는 애와 바로 뒤에 서있는 애와 손을 잡은 상황. 그리고 각 손에는 우리의 키 차이 만큼의 값을 가진다고 해보자.
여기서 가장 큰 차이를 내는 6이란 아가와 10이란 아가를 보자. 서로의 차이는 4로, 이 두 녀석이 한 조에 같이 있다면 그 조의 반티값은 최소 4이상이란 말이다. 즉 일단 우리는 최소비용을 맞추고 싶으니, 이 두 녀석은 같은 조로 넣으면 안된다! 즉 6과 10이 서로 손을 슬며시 놓는다고 생각해보자. 그리고 손을 잡은 애들끼리 조를 만든다고 하면? 1,3,5,6이 한 조고 10이 한 조로 총 두 개의 조가 만들어진다. 즉, x개의 값을 고르고 그 값들을 가지는 손들을 놓는다고 하면, x + 1개의 조가 만들어진다.
#7. 이렇게 하면 답이 되는 이유
키 순서대로 선 아가들이 있고, 인접한 애들의 차이를 담은 배열이 있을 때, 그 배열의 sum값이 그 조의 반티비용이기 때문이다. 1, 3, 5가 한 조일때 이 조의 반티값은 5 - 1 = 4로 계산할 수도 있지만 1과 3의 차이에 3과 5의 차이를 더한 값과도 같다. 즉 인접한 값의 차이끼리의 합과 그 조에서 최대값 - 최소값은 같다는 것.
또한 앞서 말했듯 그 배열에서 어떠한 값을 뺀다 즉 손을 놓는다는 것은 두 개의 배열로 분리하는 것이라 할 수 있는데, 당연히 이때 제일 큰 값을 빼는 게 좋다. 따라서 K - 1개의 가장 큰 값들을 빼주면 남은 값들의 합이 정답이 된다..
#8. 느낀점
막막하다. 남들은 쉽게 푸는 문제를 내가 나 혼자 어렵게 접근해서 풀려고 한다는 느낌도 든다. 그리디는 창의력이 중요하다는데 내가 창의력이 없이 정해진 루틴대로만 접근하려고 하는 느낌도 든다. 풀이를 보고 나니 아 이렇게 하면 될 수 밖에 없구나라는 생각은 들지만 나 스스로가 그 생각을 떠올릴 수 있을까?라는 생각도 든다.
앞으로 어떻게 문제를 풀어볼지에 대한 고민을 해본다. 내가 지금 하는 방식은 일단 브루트포스로 할 수 있을지 어림짐작해보고, 안되면 DP나 그리디로 풀 수 있는지 보기 위해 1. 부분문제로 쪼갤 수 있는지 보고 2. 중복되는 게 있는지 본다. 아직 나에겐 이 문제가 dp일지 그리디일지 확 알 수 있는 정도의 경험이 없기 때문..근데 이렇게 접근을 해가는게 맞나 싶다. 경험이 충분히 쌓여야지 이 문제는 뭘로 접근해야겠다! 라는 감이 생길 거라는 생각이 들지만, 애시 당초에 이렇게 정해진 방식으로 접근해서 푸는 이런 딱딱한? 방식이 좋은 걸까 싶기도 하고. 처음부터 문제에 유연하게 접근해야 하나 등등의 생각도 들고. 많은 생각이 든다.
일단 이 문제를 통해 배운점은,
그리디 문제의 기준을 세울 때 여러 관점에서 보도록 하자는 것.
일단 조원이 많아질수록 그 조에서 드는 반티값이 많아지니까 나는 단순히 몇 명씩 모아나가야 하는지에 포커스를 맞췄지만, 기존에 이미 한 조를 형성하고 있다고 하고 어느 놈들을 기준으로 분할할지를 고르는 식으로 포커스를 맞췄다면 이 문제를 내 힘으로 풀었을 수 있었을 거다.여러 관점에서 볼 수 있도록 힘을 길러보자.
#9. 코드
import sys
N, K = map(int, sys.stdin.readline().split())
babies = list(map(int, sys.stdin.readline().split()))
diff = []
for i in range(N - 1):
diff.append(babies[i + 1] - babies[i])
diff.sort()
print(sum(diff[:N - K]))
리액트는 state와 props를 통해 데이터마다 다른 화면을 보여줄 수 있었다. 이번엔 state가 바뀔 때마다 리액트가 렌더링하는 방식을 살펴보겠다.
우선 결론적으로 말하자면, state가 바뀔 때마다 그 state를 갖고 있는 컴포넌트 자체를 새로 렌더링한다. 즉 그 컴포넌트를 통째로 화면에 다시그린다는 것. 이 때 쉽게 생각할 수 있는 문제점은 "아니 그럼 컴포넌트를 통째로 다시 그린다면 컴포넌트 내에서 안 바뀌는 부분도 다시 그린다는 건데 이건 좀 낭비 아냐?"이다.
이런 문제를 해결하기 위해, React에선 Virtual DOM(가상 돔)이란 것을 활용한다. 리액트 내에서 DOM Tree를 본따서 만든 것인데, 이를 통해 Element를 새로 렌더링할 때 실제 DOM Tree에 바로 반영하는 게 아니라 일단은 Virtual DOM에 적용한다. 이후 state 변경 전의 Virtual DOM과 변경 후의 Virtual DOM을 비교해, 실제로 바뀐 부분만 찾아낸 다음에 비로소 그 부분들만 실제 DOM Tree에 적용한다. 똑똑하게도 바로 화면을 바꾸는 게 아니라 화면을 바꿀 준비를 하고 어디어디가 바뀌는지 파악한 다음 그 때 바꾸는 것.
이런 방식으로 렌더링하는 것은 크게 2가지의 좋은 점이 있다.
1. 개발자가 직접 DOM을 신경쓸 필요가 없으니 단순하고 깔끔한 코드를 작성할 수 있다는 것. 무슨 데이터를 어떻게 보여줄 지만 신경쓰면 된다.
2. 변경사항들을 리액트가 적당히 모아 처리할 수 있다는 것. 브라우저의 한정적인 자원을 효율적으로 이용할 수 있다는 것이다.
참고로 이 Vitrual DOM은 리액트에만 있는 개념은 아니다. 그냥 여기선 Virtual DOM을 사용하면 효율적인 화면 처리가 가능하다는 것만 알아두면 될 것 같다.
자바스크립트에서도 다른 언어와 마찬가지로 && (and의 의미)와 || (or의 의미)라는 비교연산자가 있다. 그러나 다른 언어에서는 이들이 단순히 true 또는 false의 값만 리턴하는 것과 다르게, JS에선 이를 변수 할당에 이용할 수 있다. 단순히 bool 타입의 변수 할당이 아닌 다른 값(예를 들면 문자열)등을 할당할 때도 이들을 활용 가능하며, 상당히 직관적이다.
// sample
let ex0 = 1234;
let ex1 = false;
let ex2 = ex0 || 100; // ex2 = 1234
let ex3 = ex1 || 100; // ex3 = 100;
사실 공부중에 이렇게 할 수 있다는 걸 알게 됐는데, 처음엔 "어떤 의미인지는 대충 알겠는데 이게 돼?" 였다. 지금까지 나는 이런 상황에선 3항 연산자를 사용해서 또는 if문을 활용해서 할당해왔기 때문. 정리하자면 ||는 피연산자를 리턴할 수 있는데(bool타입이 아닌 피연산자도 리턴가능하다!!), 첫 번째 피연산자가 거짓이면 두 번째 피연산자의 값을 리턴하고 그렇지 않으면 첫 번째 피연산자를 리턴한다고 한다. 즉 첫 피연산자가 참으로 평가되면 첫 피연산자를, 첫 피연산자가 거짓으로 평가되면 두 번째 피연산자를 리턴한다는 것! 이 때 '거짓'으로 평가되는 것은 직접적으로 bool타입의 false 뿐만 아니라 빈 배열([]), 빈 문자열(''), 0, null, undefined, NaN 등이 있다.
이 녀석의 활용법은 무궁무진할 것이다. 예를 들어 b라는 변수에 a라는 배열의 마지막 값을 할당하고 싶지만 a가 빈 배열이면 1을 할당하고 싶을 땐 다음과 같이 심플하게 끝낼 수 있다.
let a = [1, 2, 3, 4];
let b = a[a.length - 1] || 1;
a가 빈 배열이라면 a[a.length - 1]이 undefined가 되고 이는 false로 평가되기 때문에 1이 할당될 것이다.
지금까진 ||를 변수 할당 시에 이용해먹는 방법이 대해 알아봤고, 이젠 &&를 변수 할당 시에 이용할 수 있는 방법을 소개하겠다. 나는 ||는 직관적으로 잘 이해된 것에 비해 &&가 살짝 헷갈렸는데, 이 연산자들의 성질을 안다면 이해하기 좀 쉬울 것이다. 이 논리연산자들의 성질은 다음과 같다.
1. ||는 첫 번째 피연산자가 true면 뒤에 놈은 신경도 안 쓰고 바로 true를 내뱉는 성격이 급한 애다. 뒤에 놈은 첫 번째 피연산자가 false일 때만 쳐다본다.
2. &&는 첫 번째 피연산자가 false면 뒤에 놈은 신경도 안 쓰고 바로 false를 내뱉는 성격이 급한 애다. 뒤에 놈은 첫 피연산자가 true일 때만 쳐다본다.
이걸 학교 과제에서 이용할 때 ||이나 &&의 좌우로 수식을 써놓고 특정 상황에선 그 수식이 수행되고 어떤 상황에선 안 수행되고 이런 식으로 코드를 짰었는데..
암튼 각설하고, ||가 첫 피연산자가 참으로 평가되면 첫 피연산자를 리턴하고 그게 아니면 두 번째 피연산자를 리턴했듯이,
&&는 첫 피연산자가 거짓으로 평가되면 첫 번째 피연산자를 리턴하고 그게 아니면 두 번째 피연산자를 리턴한다. 바로 위에서 소개한 성질이 있으니까!
즉 다음 코드의 결과는 a = null이다.
a = 100 && 200 && null && 300; // a = null
참고로..엄밀히 말하자면 ||의 경우 첫 피연산자가 참으로 평가되면 첫 피연산자를, 그게 아니면 두 번째 피연산자를 리턴한다고 했는데 사실 왼쪽에서 오른쪽으로 피연산자를 하나하나 평가하면서 참으로 평가되는 녀석이 있으면 바로 그 녀석을 리턴하고, 모든 피연산자가 거짓으로 평가되는 경우엔 마지막 피연산자를 리턴하는 것이다. 근데 결론적으론 첫 피연산자가 거짓으로 평가되면 두 번째 피연산자를 리턴하는 꼴과 같다는 말에서 이렇게 쓴 것. &&도 이와 마찬가지다
이 글을 쓰고 나중에 다른 곳에서 강의를 들으며 이 내용이 나와서 정리.
JS에서 &&는 왼쪽 값이 true로 평가되면 오른쪽 값을 리턴. 반대로 왼쪽 값이 false로 평가되면 그 값을 리턴
JS에서 ||는 왼쪽 값이 true로 평가되면 왼쪽 값을 리턴, 반대로 왼쪽 값이 false로 평가되면 오른쪽 값을 리턴